基于Spark的离线电影推荐
系统需求分析以及流程设计
需求
- 基于spark集群实现离线电影推荐
- 推荐结果可以可视化(未实现)
数据源
包括两个数据文件,分别是ratings.dat和movies.dat。
首先是ratings.dat,用户评分数据记录表。包含了用户对电影的评分信息。

然后是movies.dat,电影信息表。包含了电影名电影类型等基本信息。

流程图
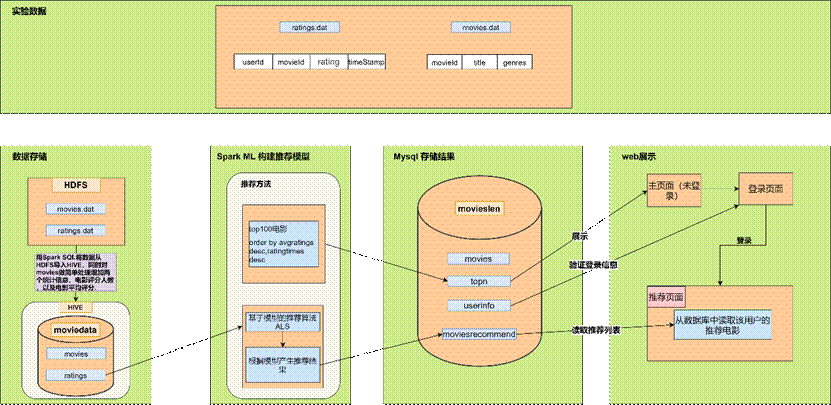
数据存储及表的设计
-
底层存储hdfs
存储着原始数据
movies.dat
ratings.dat
-
数据仓库hive
读取hdfs数据并进行初步处理,再存入moviedata数据库相关表中。
(1) movies表
存放处理后的movies数据,有5个字段。movieid(Int电影id号)、moviename(String电影名称)和genre(String 电影类型),ratingtimes(Int电影评分人数)和avgratings(Float 电影平均评分)。
(2) ratings表
存放处理后的ratings数据,有四个字段。userid(Int 用户id), movieid(Int 电影id), rating(Float 电影评分), timestampss (Int 时间戳)。
-
业务数据库mysql
推荐产生的结果,以及用户信息和电影信息都存储在数据库movieslen中。
(1)moviesrecommend表
moviesrecommend存放基于模型的电影推荐结果。包含两个字段,分别是userid(用户id号)和moviesid(包含推荐电影id号的字符串)。

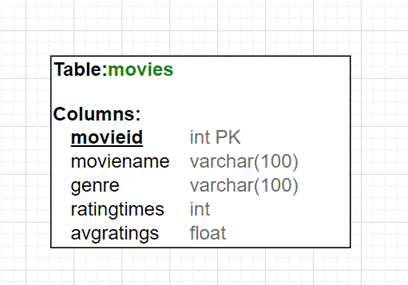
(2)movies表movies表,电影基本信息表。有5个字段。movieid(电影id号)、moviename(电影名称)和genre(电影类型),ratingtimes(电影评分人数)和avgratings(电影平均评分)。
(3)topn表
topn,存放综合排名前100的电影信息。表有五个字段。movieid(电影id号)、moviename(电影名称)和genre(电影类型),ratingtimes(电影评分人数)和avgratings(电影平均评分)。用于未登录页面的信息展示。

(4)userinfo表
userinfo表存储用户信息,包含3个字段分别是userid(用户id号)、username(用户名)和userpass(用户密码)。

实验环境搭建
主要环境
本实验是基于Spark的电影推荐系统,Spark的运行模式采用Spark on Yarn模式。所以需要在虚拟机上部署分布式Hadoop集群,同时需要安装Hive作为数据仓库,Hive底层将数据存储在HDFS上,配置MySQL存储Hive元数据。
虚拟机:VMware
1)服务器规划(虚拟机为CentOS7):
master 分配2G内存,1核
slave1 分配1G内存,1核
slave2 分配1G内存,1核
2)hdfs搭建
master 上搭建namenode,secondary namenode
slave1 上搭建datanode
slave2 上搭建datanode
3)Yarn搭建
master 上搭建resourcemanager
slave1 上搭建nodemanager
slave2 上搭建nodemanager
4)MySQL搭建,在 master 上搭建
5)Hive搭建,在 master 上搭建
6)Spark 集群搭建,搭建 Spark on Yarn 模式
可参考:https://blog.csdn.net/qq_43402639/article/details/115531789
本机项目环境:Intellij Maven
项目结构:

数据加载转换以及存储
实验都是在IDEA里编写的。要连接到集群中的hive数据库首先要将
数据存储利用HDFS作为底层存储,Hive作为数据仓库。数据原始存储在HDFS上,然后借助org.apache.spark.sql中的SparkSession来构建完成数据的ETL工作。
SparkSession:从Spark2.0以上的版本开始,spark是使用全新的SparkSession接口代替Spark1.6中的SQLcontext和HiveContext来实现对数据的加载、转换、处理等工作,并且实现了SQLcontext和HiveContext的所有功能。我们在新版本中并不需要之前那么繁琐的创建很多对象,只需要创建一个SparkSession对象即可。
SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame,并支持把DataFrame转换成SQLContext自身中的表。
然后使用SQL语句来操作数据,也提供了HiveQL以及其他依赖于Hive的功能支持。
创建SparkSession实例:
val session: SparkSession = SparkSession.builder
.master("local")
//.master("yarn")
.appName("HdfsToHive")
.enableHiveSupport()
.getOrCreate()
通过builder创建实例,同时设置master,appName等参数来确定运行模式以及application名称等,enableHiveSupport使得session支持对hive的查询访问。
数据读取
可以看到数据格式是以 “::”字符分割的字符串,所以需要分割并提取出相关字段。
因为SparkSession实例中自带SparkContext的实例,所以直接通过sessioin获取到sparkContext。

val sc: SparkContext = session.sparkContext
为了方便后续数据的组织,定义两个案例类 Movie和Rating。
case class Movie(movieid : Int, moviename : String, genre : String)
case class Rating(userid : Int, movieid : Int, rating : Float, timestampss : Int)
通过SparkContext的textFile方法,读取到hdfs上的movies.dat以及ratings.dat文件。并通过map方法将数据映射成RDD[Movie]以及RDD[Rating]类型。
val moviesInfo: RDD[String] = sc.textFile("hdfs://master:8020/moviedata/movies.dat")
val moviesRes: RDD[Movie] = moviesInfo.map(_.split("::")).map(line => Movie(line(0).toInt, line(1), line(2)))
val ratingsInfo: RDD[String] = sc.textFile("hdfs://master:8020/moviedata/ratings.dat")
val ratingsRes: RDD[Rating] = ratingsInfo.map(_.split("::")).map(line => Rating(line(0).toInt, line(1).toInt, line(2).toFloat, line(3).toInt))
数据处理
在读取到的数据字段的基础上,增加电影平均评分和电影评分人数字段丰富电影信息。
val ratingcount: DataFrame = ratingFrame
.groupBy("movieid")
.count()
.withColumnRenamed("count","ratingtimes")
var ratingavg: DataFrame = ratingFrame
.groupBy("movieid")
.avg("rating")
.withColumnRenamed("avg(rating)","avgratings")
将新产生的字段连接到原DataFrame中,因为存在电影未被评分,所以选择左连接保留所有电影信息。
val withCountMovieInfo: DataFrame = moviesFrame
.join(ratingcount,Seq("movieid"),"left_outer")
val withCountAndAvgMovieInfo: DataFrame = withCountMovieInfo
.join(ratingavg, Seq("movieid"), "left_outer")
同时需要将NULL值改为0:
val movieInfo: DataFrame = withCountAndAvgMovieInfo.na.fill(0)
数据存储
最后将处理过后的数据存入到HIVE中。通过将一张表的数据导入到另一张表的方式来构建新表:insert into [table1] select * from [table1]。
先在程序中构建临时视图temp1和temp2:
movieInfo.createOrReplaceTempView("temp1")
ratingFrame.createOrReplaceTempView("temp2")
再将临时表中的数据导入到hive表中:
session.sql("create table if not exists moviedata.movies" +
"(movieid Int, moviename String, genre String, ratingtimes Int, avgratings Float)")
session.sql("insert into moviedata.movies select * from temp1")
session.sql("create table if not exists moviedata.ratings" +
"(userid Int, movieid Int, rating Float, timestampss Int)")
session.sql("insert into moviedata.ratings select * from temp2")
同时还要将一份movies数据存入mysql中,用于网页上的展示。Spark的DataFrame支持write方法直接写入到mysql数据库中,写入模式只支持SaveMode.Append以及SaveMode.Overwrite。
val url = "jdbc:mysql://localhost:3306/movieslen?serverTimezone=GMT"
val prop = new Properties()
prop.put("user","root")
prop.put("password","******")
movies.write.mode(SaveMode.Append).jdbc(url,"movies",prop)
TopN
对于新出现的没有任何观影记录的用户,可以推荐Top电影榜。
其中排序规则按照评分人数大于100且评分排名靠前的电影。(可以采用评分人数和平均评分加权的方式选取排名靠前的电影,产生的排名结果更合理)
val top100Movies: DataFrame = session
.sql("select * from moviedata.movies where ratingtimes>100 order by avgratings desc,ratingtimes desc limit 100")
但在Hive中使用全局排序时,需要注意,Hive会将所有数据交给一个Reduce任务计算,实现查询结果的全局排序。所以如果数据量很大,只有一个Reduce会耗费大量时间。
查询语句优化:(参考https://cloud.tencent.com/developer/article/1769598 https://blog.csdn.net/weixin_38629422/article/details/109745613)
在每个Reduce中进行排序后,各自取得前N个数据,然后再对结果集进行全局排序,最终取得结果。
val top100Movies: DataFrame = session
.sql("select * from (select * from moviedata.movies distribute by length(moviename) sort by avgratings desc,ratingtimes desc limit 100) temp order by avgratings desc,ratingtimes desc limit 100")
结果存入mysql中
// TODO : 将top100数据存入 sql 表 topn中
val url = "jdbc:mysql://localhost:3306/movieslen?serverTimezone=GMT"
val prop = new Properties()
prop.put("user","root")
prop.put("password","200425")
top100Movies.write.mode(SaveMode.Append)
.jdbc(url,"topn",prop)
基于模型的推荐算法
利用基于模型的推荐算法org.apache.spark.ml.recommendation.ALS来进行电影推荐。首先从Hive中获取到所需的ratings数据,然后训练模型,再用模型预测出每个用户预测分数排名前十的电影。最后将结果存入到mysql表中。
-
基于模型的推荐算法ALS
ALS算法是基于模型的推荐算法,基本思想是对稀疏矩阵进行模型分解,评估出缺失项的值,以此来得到一个基本的训练模型。它是协同过滤的一种,并被集成到Spark的Ml库中。
-
模型训练及评分预测
ALS可调参数:
· numBlocks 是用于并行化计算的用户和商品的分块个数 (默认为10)。
· rank 是模型中隐义因子的个数(默认为10)。
· maxIter 是迭代的次数(默认为10)。
· regParam 是ALS的正则化参数(默认为1.0)。
· implicitPrefs 决定了是用显性反馈ALS的版本还是用适用隐性反馈数据集的版本(默认是false,即用显性反馈)。
· alpha 是一个针对于隐性反馈 ALS 版本的参数,这个参数决定了偏好行为强度的基准(默认为1.0)。
· nonnegative 决定是否对最小二乘法使用非负的限制(默认为false)。
受虚拟机限制没有调参过程,参数都为默认值。
val als = new ALS()
.setUserCol("userid")
.setItemCol("movieid")
.setRatingCol("rating")
val model: ALSModel = als.fit(ratings)
// TODO: 为每个用户推荐十部电影
val userRecommend: DataFrame = model.recommendForAllUsers(10)
结果处理及存储
从每个用户的推荐集中选取出预测评分最高的十部电影,并且只保留moiveid,去除预测评分字段,同时将movieid转化成以”,”分割的字符串。
val userAndMovies: DataFrame = userRecommend.select("userid", "recommendations.movieid")
val resToMysql = userAndMovies.rdd.map(row => {
val userid: Int = row.getInt(0)
val movies: mutable.Seq[Int] = row.getAs[mutable.Seq[Int]](1)
(userid, movies.mkString(","))
}).toDF("userid","moviesid")
最后将处理后的推荐数据存入到mysql的moviesRecommend表中(产生的推荐结果可以剔除实际评分过低的电影以及评分人数过少的电影,以免推荐劣质电影)
val url = "jdbc:mysql://localhost:3306/movieslen?serverTimezone=GMT"
val prop = new Properties()
prop.put("user","root")
prop.put("password","****")
resToMysql.write.mode(SaveMode.Append).jdbc(url,"moviesRecommend",prop)
基于物品的推荐算法
同时根据点击的电影,可以同时推荐相似电影。基于物品的电影推荐是计算电影之间的相似度,这里选用余弦相似度,然后推荐相似度高的(同样的产生的推荐结果可以剔除实际评分过低的电影以及评分人数过少的电影,以免推荐劣质电影)。
物品的特征矩阵可以通过ALS模型拟合后获得
// 余弦相似度
def cosineSimilarity(vec1: FloatMatrix, vec2: FloatMatrix) :Float = {
vec1.dot(vec2) / (vec1.norm2() * vec2.norm2())
}
// TODO : 训练模型
val als = new ALS()
.setUserCol("userid")
.setItemCol("movieid")
.setRatingCol("rating")
val model: ALSModel = als.fit(ratings)
// TODO : 得到物品特征矩阵
val res: RDD[(Int, FloatMatrix)] = model.itemFactors.rdd.map(
row => {
val movieid: Int = row.getInt(0)
val features: mutable.Seq[Float] = row.getAs[mutable.Seq[Float]](1)
val matrix = new FloatMatrix(features.toArray)
(movieid, matrix)
}
)
// TODO : 计算电影之间的相似度 用笛卡尔积组合所有(Int, FloatMatrix)对
val moviesRec: RDD[((Int, FloatMatrix), (Int, FloatMatrix))] = res.cartesian(res)
val top10Recs: RDD[(Int, String)] = moviesRec
.filter {
case (a, b) =>
a._1 != b._1
} // 过滤掉自己和自己的相似度数据
.map {
case (a, b) => {
(a._1, (b._1, cosineSimilarity(a._2, b._2)))
}
} // 计算两个特征向量之间的余弦相似度 (电影1,(电影2,相似度))
.filter(_._2._2 > 0.7) // 先过滤掉一部分数据
.groupByKey() // 根据movieid聚合
.map { // 通过映射取出每部电影的相关度排名前十的相关电影,不需要保留相似度
case (mid: Int, recs: Iterable[(Int, Float)]) => {
val recMids: List[Int] = recs.toList.sortWith(_._2 > _._2).take(10).map(_._1)
(mid, recMids.mkString(","))
}
}
import session.implicits._
val resToMysql: DataFrame = top10Recs.toDF("movieid", "moviesid")
完整代码:
链接:https://pan.baidu.com/s/1IxnT2If-qCzH01Zhq7z56A
提取码:84me