[PConline 应i用]最近很多朋友都向笔者表示了想要购买新MacBook的想法,一方面是由于M1芯片性能非常强劲,另一方面也在于想要体验一下macOS——Windows系统上的流氓软件弹窗,实在了忍无可忍了!macOS兼容了iOS App后,生活娱乐方面的应用得到了很大程度的补足,而且没有莫名其妙的弹窗,这足以让不少用户产生从Windows生态转向macOS生态的意向。
但客观来说,如果想要兼顾方方面面,macOS上的软件生态依然是不能完全顶替Windows的。那么要如何解决Windows上的流氓弹窗,让Windows有一个更好的体验?很多朋友都会选择一些弹窗拦截工具,但这些工具也不是万能的。有时候出现一个弹窗,你甚至是不知道来自哪个软件!
今天,笔者就跟大家分享两个方法,来找到弹窗对应的软件,让乱弹窗的软件见鬼去吧!
Process Explorer 官方下载:https://docs.microsoft.com/en-us/sysinternals/downloads/process-explorer
这是一款微软自家的工具,它本身是由Sysinternals开发的,现在已经被微软收购。Process Explorer本身是一个高级的任务管理器,他可以用来管理系统不同的进程,远比Win10自带的任务管理器更加直观。不过这里,我们着重用到它的弹窗检测功能。
Process Explorer主界面,信息量非常丰富 Process Explorer有一个检测窗口隶属什么进程的功能。在主界面中,有一个类似瞄准镜的图标,用鼠标拖动这个图标到某个窗口中,Process Explorer自动就能分辨出这个窗口属于什么进程,这功能可谓非常实用了!如果你看到一个莫名其妙的弹窗,不知道是什么软件导致的,就可以用它来轻松揪出弹窗的幕后黑手,清理起来毫不费力。
瞬间知道窗口是什么进程发起的 Revo Uninstaller 官网地址:https://www.revouninstaller.com/
这是一个非常强力的卸载工具,它的主要功用,在于卸载电脑上某些顽固的软件。Revo Uninstaller对付弹窗也非常有一套,它自带了一个“猎人模式”,可以用来识别弹窗的归属,效果非常好。
Revo Uninstaller的猎人模式 Revo Uninstaller的猎人模式使用体验和Process Explorer是类似的。在进入到猎人模式后,就会弹出一个瞄准镜的小图标,将它拖动到某个窗口,Revo Uninstaller就可以识别出这个窗口的对应软件,并且还能进行卸载、停止进程、停止自动启动、打开所在文件夹等操作。
猎人模式可以轻松检测窗口的所属进程、软件,帮你辨认出窗口来自哪里 和Process Explorer的检测窗口功能相比,Revo Uninstaller的猎人模式不仅仅可以检测到窗口的对应进程,还可以直接处理相关软件,功能上要更强大一些。
总结 怎么样,有了这两个方法,找到弹窗对应的流氓软件,是不是方便多了?如果你想要找出电脑中会私自弹窗的流氓软件,不妨试试上文提到的工具吧,拒绝使用这些软件才是杜绝弹窗的根本方法!
『Python基础-5』数字,运算,转换
目录
基本的数字类型
二进制,八进制,十六进制
数字类型间的转换
数字运算
1. 数字类型
Python 数字数据类型用于存储数学上的值,比如整数、浮点数、复数等。数字类型在python中是不可变类型,意思是一个变量被赋予了一个不一样的数值之后就不再是原来的内存指向了,python是基于值得内存管理机制。
数据类型是不允许改变的,这就意味着如果改变数字数据类型的值,将重新分配内存空间。
Python 支持三种不同的数值类型:
整型(Int) - 通常被称为是整型或整数,是正或负整数,不带小数点。Python3 整型是没有限制大小的,可以当作 Long 类型使用,所以 Python3 没有 Python2 的 Long 类型。
浮点型(float) - 浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(2.5e2 = 2.5 x 102 = 250)
复数( (complex)) - 复数由实数部分和虚数部分构成,可以用a + bj,或者complex(a,b)表示, 复数的实部a和虚部b都是浮点型。
2. 二进制,八进制,十六进制
进制也就是进位制。进行加法运算时逢X进一(满X进一),进行减法运算时借一当X,这就是X进制,这种进制也就包含X个数字,基数为X。
二进制 Binary
二进制以2为基数,只用0和1两个数字表示数,逢2进一。
二进制常量用0b或0B开头,后面跟着二进制数字(0、1)
例,ob010101
八进制 Octal
八进制,就是其基数为8,基数值可以取0、1、2、3、4、5、6、7共8个值,逢八进一。
八进制常量以数字0o或0O开头(0和小写或大写的字母“o”),后面接着数字0~7构成的字符串。
例,0o177
十六进制 Hexadecimal
十六进制一ox或0X开头,后面接十六进制的数字0~9和A~F。十六进制的数字编写成大写或小写都可以。
例,ox9ff
各种进制的用途
2进制,是供计算机使用的,1,0代表开和关,有和无,机器只认识2进制。
10进制,当然是便于我们人类来使用,我们从小的习惯就是使用十进制,这个毋庸置疑。
16进制,内存地址空间是用16进制的数据表示, 如0x8049324。
编程中,我们常用的还是10进制。
比如:int a = 100,b = 99;
一、MySQL报错:Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column
Expression #1 of SELECT list is not in GROUP BY clause and contains
nonaggregated column ‘tt.from_id’ which is not functionally dependent
on columns in GROUP BY clause; this is incompatible with
sql_mode=only_full_group_by
参考:https://blog.csdn.net/weixin_45459224/article/details/102808392
https://blog.csdn.net/qq_34707744/article/details/78031413
https://www.cnblogs.com/chcha1/p/12996860.html
(如果要输入密码,输入的是本电脑的密码,不是mysql密码)
问题出现的原因
MySQL 5.7.5及以上功能依赖检测功能。如果启用了ONLY_FULL_GROUP_BY SQL模式(默认情况下),MySQL将拒绝选择列表,HAVING条件或ORDER BY列表的查询引用在GROUP
BY子句中既未命名的非集合列,也不在功能上依赖于它们。(5.7.5之前,MySQL没有检测到功能依赖关系,默认情况下不启用ONLY_FULL_GROUP_BY。有关5.7.5之前的行为的说明,请参见“MySQL5.6参考手册”。)
我的mysql版本是5.17.14(sql客户端navicat:select version();即可查询)
解决方法一:(不能根治,每次重启mysql服务器又变回之前的sql模式,只能保证在mysql重启之前有效哦,我是用这种方法解决的牛客网项目)
1、打开navicat,用sql查询:
select @@global.sql_mode
2、查询出来的值为:
ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
3、去掉ONLY_FULL_GROUP_BY,重新设置值。
set @@global.sql_mode =`STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION`; 4、注意不要重启mysql
# 作业
# 1.列举布尔值为False的值
# 0 False ‘‘ [] {} () None
# 2.写函数:
# 根据范围获取其中3和7整除的所有数的和,并返回调用者:
# 符合条件的数字以及符合条件的数字的总和, 如:def func(start,end):
# def f1(arg):
# print(arg+100)
# def f2(arg):
# ret = f1(arg+1)
# print(arg)
# print(ret)
# ret=f2(7)
# print(ret)
# # 108
# # 7
# # None
# # None
# 24.将字符串"老男人"转换成utf8编码的字节类型
# 在内存里只有一种编码Unicode
# s = ‘老男人‘等于写在了内存里
# 字节有很多种
# 字节利于存储在磁盘,利于传输
# a=bytes(s,‘utf8‘)#转化为字节
# 另外一种方式
# s.
例如时间为06:30 要计算40分钟以后的时间,正确应该是07:10
excel公式中输入,其中C2表示06:30 G2表示40
=TEXT(C2+TIME(0,G2,0),"hh:mm") TIME(hour,minute,second)
1 摘要 we strive to develop techniques based on neural networks to tackle the key problem in recommendation — collaborative filtering — on the basis of implicit feedback.
我们致力于发展基于神经网络的技术,在隐式反馈的基础上,来解决推荐中的关键问题–协同过滤
we propose to leverage a multi-layer perceptron to learn the user–item interaction function
我们想利用多层感知器来学习用户-项目交互特征
2 介绍 The key to a personalized recommender system is in modelling users’ preference on items based on their past interactions (e.g., ratings and clicks), known as collaborative filtering
个性不要个体;独立不要孤立;自由不要自私;浪漫不要散漫 路漫漫其修远兮,吾将上下而求索—屈原 离骚 文章介绍:
这是计算机网络老师布置的课后作业,参考文章: 习题二 , 习题三 , 习题四 , 持续更新…
题目都很新型,网上很难能够找出所有答案,今天分享出来,希望能够帮助有需要的人,一起学习进步!
# 本文章分享由小亮子整理汇总,如有转载,请注明出处!!! # 总结不易,望点赞鼓励 # 文章最后送福利哦!! # 看完再走也不迟~ 一、计算机网络的体系结构 课后习题: 1、无连接通信和面向连接通信的最主要区别是什么? 解:在计算机网络领域,网络层应该向运输层提供怎样的服务(“面向连接”还是“无连接”)曾引起了长期的争论。争论焦点的实质就是:在计算机通信中,可靠交付应当由谁来负责?是网络还是端系统?
主要的区别有两条:
其一:面向连接分为三个阶段,第一是建立连接,在此阶段,发出一个建立连接的请求。只有在连接成功建立之后,才能开始数据传输,这是第二阶段。接着,当数据传输完毕,必须释放连接。而面向无连接没有这么多阶段,它直接进行数据传输,发送数据。
其二:面向连接的通信具有数据的保序性, 而面向无连接的通信不能保证接收数据的顺序与发送数据的顺序一致。
例子:
对于无连接的服务(邮寄),发送信息的计算机把数据以一定的格式封装在帧中,把目的地址和源地址加在信息头上,然后把帧交给网络进行发送。无连接服务是不可靠的。
对于面向连接的服务(电话),发送信息的源计算机必须首先与接收信息的目的计算机建立连接。这种连接是通过三次握手(three hand shaking)的方式建立起来的。一旦连接建立起来,相互连接的计算机就可以进行数据交换。与无连接服务不同,面向连接的服务是以连接标识符来表示源地址和目的地址的。面向连接的服务是可靠的,当通信过程中出现问题时,进行通信的计算机可以得到及时通知。
2、举出使用分层协议的两个理由。 解:(1)把复杂的设计问题分割为较小的简单问题;
(2)某一层协议的改变不影响相邻的其他层协议。
3、举出OSI参考模型和TCP/IP参考模型的两个共同点及两个不同点。 解: 相同的方面是:两个模型都基于分层协议,两者都有网络层,运输层和应用层;在两个模型中,运输服务都能够提供可靠的端到端的字节流。
不同点的方面是:二者层的数目是不同的,TCP/IP没有会话层和表示层,TCP/IP支持网络互连,OSI不支持网络互连;TCP/IP的网络层只提供无连接服务,而OSI在网络层中,既有面向连接的服务,也有无连接服务。
4、OSI的哪一层分别处理以下问题: (a)把传输的比特流化分为帧。
(b)决定使用哪条路径通过子网。
解: (a)数据链路层
(b)网络层
补充扩展知识点:
①把传输的位流分成帧。——数据链路层
②在通过子网的时候决定使用哪条路径到达目的地。——网络层
③提供端到端的可靠数据传输。——传输层
④传输线上的位流信号同步。——物理层
⑤两端用户间传输文件。——应用层
⑥计算机自动拨号建立线路连接的 过程。——物理层
⑦将收到的电子邮件放入邮箱并通知接收者。——应用层
⑧连接两个子网,使它们能够互相通信。——网络层
⑨网络安全和保密。——表示层
5、一个有n层协议的系统,应用层生成长度为m字节的报文,在每层都加上h字节报头。那么网络带宽中有多大百分比是在传输各层报头? 解: 在同一结点内,当应用进程产生数据从最高层传至最低层时,所添加的报头的总长度为 n h字节,数据部分仍为 m 字节。因此,为传输报头所占用的网络带宽百分比为:
n h /( n h + m )* 100%
谢尔顿的左耳朵www.zhangxiaoshuai.fun 最近做的一个项目中涉及到了微信支付的模块,因为之前从来没有接触过支付这方面的内容,所以花了一些时间去专门研究,最后总算是搞定了支付;但是能支付可不行,我需要将用户支付过的订单的支付状态进行修改,并在下一次用户进行浏览的时候进行判断:用户是否已经对该资源进行了支付,如果已经进行了支付,那么直接放行;如果没有进行支付,就需要拉起收银台进行支付。
虽然这篇文章的标题主要是回调接口的内容,但是我还是想要把支付这一些问题进行一个小小的回顾总结。
最开始遇到的问题是:用户点击资源的时候系统进行预下单,然后在调用支付接口获取一系列参数,但是可能存在用户刚点进资源中,系统已经完成了预下单,但是用户又不想看了,又退了出去,过了一会,用户又回来了,这时,系统会再次下单,但是最开始的时候我没有考虑这种情况,所以在用户第二次进行下单的时候,就会出现下单失败的情况,最终的解决方案是:在用户请求下单之前,先查询是否存在之前下好的订单,如果存在,则只需修改预下单的时间即可,然后返回给前端订单信息;
完成重复下订单的问题之后,又出现了新的问题:当收银台被拉起的时候,用户又不想支付了,所以用户选择了关掉收银台,但是用户并没有退出资源界面,过了一会,用户重新点击支付,后台报错:订单已支付,请不要重复操作。what?我还没有支付呢……到底是哪里出现了问题呢?通过DEBUG,我将问题定位到自定义的“订单编号”上面,因为我这里使用的编号是该视频的序列编号,这个编号是固定的,当这个视频没有被购买过,第一次购买的人是可以成功支付的,这个时候自定义序列编号就会成为该订单的订单号,并且存在与微信后台中,这样在第二个人购买的时候,当我们将一系列的参数封装起来传到微信服务器上的时候,就会出现“该订单已存在”的现象。微信服务器返回给我的数据标识中:return_code:SUCCESS,而result_code:FAIL,在一个成功一个失败的情况下肯定是无法拉取起银台进行支付的,最终解决方案:使用当前年月日和一些标识生成每一个独一无二的订单编号,这样就解决了这个问题;
解决了无法支付的问题之后,随之而来的就是支付成功之后,微信似乎并没有调取回调接口进行逻辑业务。这样就造成了用户在支付成功之后,系统并没有将用户支付成功的结果进行存储,然后用户下次进行观看的时候就会造成继续收费的情况;
通过百度中各路大神的建议,我前后分别作出了如下尝试:
1.关闭和打开Linux防火墙; 2.分别尝试http和https; 3.尝试使用公网访问该回调接口,访问没有问题; 最后,我将目光集中在了tomcat日志上
查看catalina.out
显然,在请求支付的时候,后台是将notify_url传递过去了
这是支付成功之后的调用,显然是调用了回调接口,这说明回调地址应该是没有问题的。
但是为什么明明业务中写了对数据库的操作,既然调用了回调接口,却对数据库没有进行更新呢?
我又去到了error.log中查看
这就是我回调接口中的日志打印啊,这下我确信应该是业务逻辑中出现了问题,导致没有执行(日志打印在业务逻辑之前)
果然,在通过一个订单编号查询订单的方法参数上竟然还写的是之前的自定义订单号,这样每次根本没有订单被查询到,也就谈不上对支付状态更新和对支付成功订单进行存储的功能了……
我赶紧修改了查询参数、service层和持久层,总算是完成了基本的闭环支付。
参考链接: Java中的循环的重要事项
Java开发面试题
Java基础篇Java8大基本数据类型Java的三大特性面向对象如果让你推销一款Java产品,你会怎么推销呢?(java的特点)JVM与字节码JDK与JREStringBuilder和StringBuffer的区别简单介绍下多态、重载、重写自动装箱和拆箱String能被继承吗?简单介绍一下static关键字super()和this()equals和==关于常量池抽象类与接口Java中的比较器(Comparable、Comparator)Java中的栈与堆final、finally、finalize数组和链表的区别为什么提出集合框架集合的概述以及底层数据结构并发与并行sleep和wait的区别线程的生命周期什么是线程、进程线程和进程的区别图解进程线程什么是线程安全、为什么提出线程安全、如何实现?Thread 类中的start() 和 run() 方法有什么区别?Java中notify 和 notifyAll有什么区别?泛型是什么?为什么使用?概述反射和序列化序列化的好处使用JDBC的过程
数据库篇数据库的基本操作MySql底层采用什么数据结构来存储数据?分页所用的关键字SQL实现数据表的复制什么是事务事务的四大特性什么是存储过程简单介绍一下触发器什么是E-R图什么是外连接、内连接?什么是索引?有什么用?范式
数据结构篇快速排序冒泡排序二分查找二叉树的遍历什么是红黑树
计算机网络篇TCP和UDP三次握手 四次挥手网络的七层协议当在浏览器输入栏按下回车会发生什么邮件服务器之间传送邮件通常使用什么协议,它们分别使用哪个端口,简述其功能。
web篇表单中get和post区别什么是Ajax,好处是什么九大内置对象转发(Forward)和重定向(Redirect)的区别cookie和session你了解监听器吗?
框架篇(这里只涉及SSM)什么是ORMMyBatis默认用什么做日志管理MyBatis动态代理MyBatis输入输出类型resultMap的使用为什么使用Druid(德鲁伊),不使用c3p0简单介绍SpringSpring的两大特性什么是MVCSpringMVC的工作流程
声明
Java基础篇 Java8大基本数据类型 byteshortintlongfloatdoublecharboolean占用空间1字节(B)2字节4字节8字节4字节8字节不定 默认2字节JVM未定义初始值00000.00.0空格false
Java的三大特性 封装:隐藏内部功能的具体实现,只保留和外部交流数据的接口。例:汽车与发动机,不必知道发动机的实现原理,只需使用汽车给予的接口,插入钥匙。继承:一个对象可以从它的父类继承所有的通用的属性和方法,并在无需重新编写原来的类的情况下对这些功能进行扩展;最大的好处是实现代码的高效重用。多态:同一个动作作用于不同的对象 所产生不同的行为。例:人会吃饭,中国人用筷子,美国人用叉子。 面向对象 面向对象的核心,就是类和对象。Java中的面向对象的思想:万物皆对象。类:是对一类事物的描述,是抽象的,看不见,摸不着。对象:是实际存在的该类事物的每个个体 也称为实例 是具象的。所以面向对象程序设计的重点是类的设计,而不是对象的设计。类是对象的描述 对象叫做类的实例化(Instance)类不占内存,对象才占内存。 如果让你推销一款Java产品,你会怎么推销呢?(java的特点) 1.Java是面向对象的
2.Java是跨平台的;一次编译,到处运行
3.Java是多线程的
4.Java有GC,简化了开发
5.Java是分布式的
6.Java现在运用最广泛(有待商榷,python太猛了)
7.支持多线程( C++ 语言没有内置的多线程机制,因此必须调用操作系统的多线程功能来进行多线程程序设计,而 Java 语言却提供了多线程支持);
8.支持网络编程并且很方便( Java 语言诞生本身就是为简化网络编程设计的,因此 Java 语言不仅支持网络编程而且很方便);
9.编译与解释并存;
JVM与字节码 JVM:Java虚拟机(JVM)是运行 Java 字节码的虚拟机。 JVM有针对不同系统的特定实现,目的是使用相同的字节码,它们都会给出相同的结果(一次编译,到处运行)。 字节码:在 Java 中,JVM可以理解的代码就叫做字节码(即扩展名为 .class 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java程序无须重新编译便可在多种不同操作系统的计算机上运行。 JDK与JRE JDK是Java Development Kit,它是功能齐全的Java SDK。它拥有JRE所拥有的一切,还有编译器(javac)和工具(如javadoc和jdb)。它能够创建和编译程序。 JRE 是 Java运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,包括 Java虚拟机(JVM),Java类库,java命令和其他的一些基础构件。但是,它不能用于创建新程序。 StringBuilder和StringBuffer的区别 1.
添加微信二维码到任意一篇博客
复制二维码链接地址
替换到img src 段中
<ul class="panel_head"> <span>感悟</span></ul> <ul class="panel_body"> 坚持就有赢的可能 <img src="https://img-blog.csdnimg.cn/20201203084648159.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3h1d2Vpd2VpMTg2MA==,size_16,color_FFFFFF,t_70#pic_center"> </ul> `` 1. 管理博客  2. 模块管理  3. 添加一个自定义模块 4. 编辑 5.复制js代码 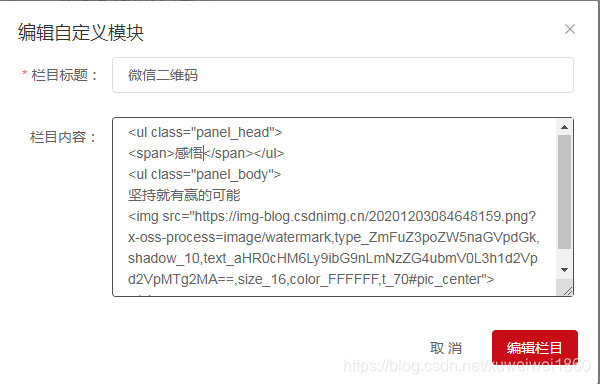 6.效果 
Python中是有查找功能的,五种方式:in、not in、count、index,find 前两种方法是保留字,后两种方式是列表的方法。
下面以a_list = ['a','b','c','hello'],为例作介绍:
string类型的话可用find方法去查找字符串位置:
a_list.find('a')
如果找到则返回第一个匹配的位置,如果没找到则返回-1,而如果通过index方法去查找的话,没找到的话会报错。
补充知识:Python中查找包含它的列表元素的索引,index报错!!!
对于列表["foo", "bar", "baz"]和列表中的项目"bar",如何在Python中获取其索引(1)?
一、index
>>> ["foo", "bar", "baz"].index("bar")
警告如下
请注意,虽然这也许是回答这个问题最彻底的方法是问,index是一个相当薄弱的组件listAPI,而我不记得我最后一次使用它的愤怒。在评论中已经向我指出,因为这个答案被大量引用,所以应该更加完整。关于list.index跟随的一些警告。最初可能需要查看文档字符串:
>>> print(list.index.__doc__)
L.index(value, [start, [stop]]) -> integer -- return first index of value.
Raises ValueError if the value is not present.
我曾经使用过的大多数地方index,我现在使用列表推导或生成器表达式,因为它们更具有推广性。因此,如果您正在考虑使用index,请查看这些出色的python功能。
如果元素不在列表中,则抛出
如果项目不存在则调用index结果ValueError。
>>> [1, 1].index(2)
Traceback (most recent call last):
File "", line 1, in ValueError: 2 is not in list
如果该项目可能不在列表中,您应该
首先检查它item in my_list(干净,可读的方法),或
将index呼叫包裹在try/except捕获的块中ValueError(可能更快,至少当搜索列表很长时,该项通常存在。)
大多数答案解释了如何查找单个索引,但如果项目在列表中多次,则它们的方法不会返回多个索引。用途enumerate():
https://pan.baidu.com/s/1ljpv4EpD6PhjY1ryemU-tg
提取码:14p7
想了解更多数据结构以及算法题,可以关注微信公众号“数据结构和算法”,每天一题为你精彩解答。也可以扫描下面的二维码关注
问题描述
给你一个字符串s,请你根据下面的算法重新构造字符串:
从s中选出最小的字符,将它接在结果字符串的后面。从s剩余字符中选出最小的字符,且该字符比上一个添加的字符大,将它接在结果字符串后面。重复步骤2,直到你没法从s中选择字符。从s中选出最大的字符,将它接在结果字符串的后面。从s剩余字符中选出最大的字符,且该字符比上一个添加的字符小,将它接在结果字符串后面。重复步骤5,直到你没法从s中选择字符。重复步骤1到6,直到s中所有字符都已经被选过。 在任何一步中,如果最小或者最大字符不止一个,你可以选择其中任意一个,并将其添加到结果字符串。
请你返回将s中字符重新排序后的结果字符串 。
示例 1:
输入:s = “aaaabbbbcccc”
输出:“abccbaabccba”
解释:第一轮的步骤 1,2,3 后,结果字符串为 result = “abc”
第一轮的步骤 4,5,6 后,结果字符串为 result = “abccba”
第一轮结束,现在 s = “aabbcc” ,我们再次回到步骤 1
第二轮的步骤 1,2,3 后,结果字符串为 result = “abccbaabc”
第二轮的步骤 4,5,6 后,结果字符串为 result = “abccbaabccba”
示例 2:
输入:s = “rat”
输出:“art”
解释:单词 “rat” 在上述算法重排序以后变成 “art”
示例 3:
输入:s = “leetcode”
输出:“cdelotee”
示例 4:
输入:s = “ggggggg”
输出:“ggggggg”
示例 5:
输入:s = “spo”
Pandas是Python的一个大数据处理模块。Pandas使用一个二维的数据结构DataFrame来表示表格式的数据,相比较于Numpy,Pandas可以存储混合的数据结构,同时使用NaN来表示缺失的数据,而不用像Numpy一样要手工处理缺失的数据,并且Pandas使用轴标签来表示行和列。
DataFrame类:
DataFrame有四个重要的属性: index:行索引。 columns:列索引。 values:值的二维数组。 name:名字。
构建方法,DataFrame(sequence),通过序列构建,序列中的每个元素是一个字典。 frame=DateFrame构建完之后,假设frame中有’name’,’age’,’addr’三个属性,可以使用fame[‘name’]查看属性列内容,也可以fame.name这样直接查看。 frame按照’属性提取出来的每个列是一个Series类。 DataFrame类可以使用布尔型索引。 groupby(str|array…)函数:可以使用frame中对应属性的str或者和frame行数相同的array作为参数还可以使用一个会返回和frame长度相同list的函数作为参数,如果使用函数做分组参数,这个用做分组的函数传入的参数将会是fame的index,参数个数任意。使用了groupby函数之后配合,size()函数就可以对groupby结果进行统计。 groupby后可以使用: size():就是count sum():分组求和 apply(func,axis=0):在分组上单独使用函数func返回frame,不groupby用在DataFrame会默认将func用在每个列上,如果axis=1表示将func用在行上。
reindex(index,column,method):用来重新命名索引,和插值。 size():会返回一个frame,这个frame是groupby后的结果。 sum(n).argsort():如果frame中的值是数字,可以使用sum函数计算frame中摸个属性,各个因子分别求和,并返回一个Series,这个Series可以做为frame.take的参数,拿到frame中对应的行。 pivot_table(操作str1,index=str2,columns=str3,aggfunc=str4)透视图函数: str1:是给函数str4作为参数的部分。 str2:是返回frame的行名。 str3:是返回frame的列名。 str4:是集合函数名,有’mean’,’sum’这些,按照str2,str3分组。 使用透视图函数之后,可以使用.sum()这类型函数,使用后会按照index和columns的分组求和。 order_index(by,ascending): 返回一个根据by排序,asceding=True表示升序,False表示降序的frame concat(list):将一个列表的frame行数加起来。 ix[index]:就是行索引,DataFrame的普通下标是列索引。 take(index):作用和ix差不多,都是查询行,但是ix传入行号,take传入行索引。 unstack():将行信息变成列信息。 apply(func,axis=0)和applymap(func):apply用在DataFrame会默认将func用在每个列上,如果axis=1表示将func用在行上。applymap表示func用在每个元素上。 combine_first(frame2):combine_first会把frame中的空值用frame1中对应位置的数据进行填充。Series方法也有相同的方法。 stack()函数,可以将DataFrame的列转化成行,原来的列索引成为行的层次索引。(stack和unstack方法是两个互逆的方法,可以用来进行Series和DataFrame之间的转换) duplicated():返回一个布尔型Series,表示各行是否重复。 drop_duplicates():返回一个移除了重复行后的DataFrame pct_change():Series也有这个函数,这个函数用来计算同colnums两个相邻的数字之间的变化率。 corr():计算相关系数矩阵。 cov():计算协方差系数矩阵。 corrwith(Series|list,axis=0):axis=0时计算frame的每列和参数的相关系数。
数据框操作
df.head(1) 读取头几条数据 df.tail(1) 读取后几条数据 df[‘date’] 获取数据框的date列 df.head(1)[‘date’] 获取第一行的date列 df.head(1)‘date’ 获取第一行的date列的元素值 sum(df[‘ability’]) 计算整个列的和 df[df[‘date’] == ‘20161111’] 获取符合这个条件的行 df[df[‘date’] == ‘20161111’].index[0] 获取符合这个条件的行的行索引的值 df.iloc[1] 获取第二行 df.iloc1 获取第二行的test2值 10 mins to pandas df.
方式一:
yum安装
1、配置yum源
备份原来的epel源
mv /etc/yum.repos.d/epel.repo /etc/yum.repos.d/epel.repo.backup 配置阿里云epel源.
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo 2、安装
yum -y install percona-xtrabackup
方式二:
rpm包安装
1、官网下载rpm包安装
https://www.percona.com/downloads/Percona-XtraBackup-2.4/
wget https://downloads.percona.com/downloads/Percona-XtraBackup-2.4/Percona-XtraBackup-2.4.21/binary/redhat/7/x86_64/percona-xtrabackup-24-2.4.21-1.el7.x86_64.rpm 下载慢的,访问我的百度云链接
链接:https://pan.baidu.com/s/1jqN-3JWKzku2BWHgW_eGOA
提取码:9fcr
安装依赖包
yum -y install perl perl-devel libaio libaio-devel perl-Time-HiRes perl-DBD-MySQL 2、安装
rpm -ivh percona-xtrabackup-24-2.4.21-1.el7.x86_64.rpm --nodeps --force 或者
yum -y localinstall percona-xtrabackup-24-2.4.21-1.el7.x86_64.rpm 方式三:
二进制包安装
1、下载安装包(二进制包)
https://www.percona.com/downloads/Percona-XtraBackup-2.4/Percona-XtraBackup-2.4.21/binary/redhat/7/
wget https://downloads.percona.com/downloads/Percona-XtraBackup-2.4/Percona-XtraBackup-2.4.21/binary/tarball/percona-xtrabackup-2.4.21-Linux-x86_64.glibc2.12.tar.gz 下载慢的,看我百度云链接下载
链接:https://pan.baidu.com/s/1SA6WVObQms3stlmpZvN0Fg
提取码:0ptk
2、安装xtrabackup
解压安装包
tar -xf percona-xtrabackup-2.4.21-Linux-x86_64.glibc2.12.tar.gz 启动解压包到自定义路径
cp percona-xtrabackup-2.4.21-Linux-x86_64.glibc2.12 /usr/local/ 配置环境变量 /etc/profile最后添加如下内容
vim /etc/profile export XTRABACKUP_PATH=/usr/local/percona-xtrabackup-2.
说明:
gitlab数据备份的前提条件,恢复版本需要与原备份版本一致以docker方式运行时候,启动恢复后若报错login or password rejected,是因为docker -v 环境有问题,docker volume ls 查看挂载,做合理删除本文档经测试,完全可用,若出现问题,注意环境的检查 搭建gitlab # 查看gitlab版本 cat /opt/gitlab/embedded/service/gitlab-rails/VERSION # 下载启动gitlab sudo docker run --detach --hostname gitlab.example.com --publish 443:443 --publish 7980:80 --publish 22:22 --name gitlab --volume $GITLAB_HOME/config:/etc/gitlab --volume $GITLAB_HOME/logs:/var/log/gitlab --volume $GITLAB_HOME/data:/var/opt/gitlab gitlab/gitlab-ce:11.10.1-ce.0 查看docker日志 docker logs gitlab # 若出现报错,查看报错信息,做调整,否则后续数据恢复后登陆出现问题,以docker启动方式来看,一般为-v问题 copy数据至docker内备份路径下,默认为/var/opt/gitlab/backups docker cp /home/ctdna/Downloads/1606838545_2020_12_01_11.10.1_gitlab_backup.tar gitlab:/var/opt/gitlab/backups 恢复数据 docker exec -it gitlab sh cd /var/opt/gitlab/backups # ls 查看,若仅有一个文件 gitlab-rake gitlab:backup:restore # ls 若有多个备份文件,不可添加_gitlab_backup.tar后缀,会自动补充 gitlab-rake gitlab:backup:restore BACKUP=1606752150_2020_11_30_11.10.1 可用性检测 gitlab-rake gitlab:check SANITIZE=true http://192.
使用onnx进行推理遇到的问题 1. Python37\lib\site-packages\onnxruntime\capi_pybind_state.py:14: UserWarning: Cannot load onnxruntime.capi. Error: ‘DLL load failed: 找不到指定的模块。’ 2. Python\Python37\lib\site-packages\onnxruntime\capi_pybind_state.py:25: UserWarning: Unless you have built the wheel using VS 2017, please install the 2019 Visual C++ runtime and then try again warnings.warn("Unless you have built the wheel using VS 2017, " 3. from onnxruntime.capi._pybind_state import get_all_providers, get_available_providers, get_device, set_seed, \ImportError: cannot import name ‘get_all_providers’ from ‘onnxruntime.capi._pybind_state’ 解决方法: 使用pip install onnxruntime 安装的是onnxruntime 1.5.2版本,版本过高,
通过pip install onnxruntime==1.2.0(及以下,如1.1.2等均可解决),解决上述问题。
题图:Java的发明人詹姆斯·高斯林 (五) 日期时间
日期格式化时,传入pattern中表示年份统一使用小写的y。 说明:日期格式化时,yyyy表示当天所在的年,而大写的YYYY代表是week in which year(JDK7之后引入的概念),意思是当天所在的周属于的年份,一周从周日开始,周六结束,只要本周跨年,返回的YYYY就是下一年。 正例:表示日期和时间的格式如下所示: new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") 2.在日期格式中分清楚大写的M和小写的m,大写的H和小写的h分别指代的意义。
说明:日期格式中的这两对字母表意如下: 1) 表示月份是大写的M; 2) 表示分钟则是小写的m; 3) 24小时制的是大写的H; 4) 12小时制的则是小写的h。 3.获取当前毫秒数:System.currentTimeMillis(); 而不是new Date().getTime()。
说明:如果想获取更加精确的纳秒级时间值,使用System.nanoTime的方式。在JDK8中,针对统计时间等场景,推荐使用Instant类。 4.不允许在程序任何地方中使用:1)java.sql.Date。 2)java.sql.Time。 3)java.sql.Timestamp。
说明:第1个不记录时间,getHours()抛出异常;第2个不记录日期,getYear()抛出异常;第3个在构造方法super((time/1000)*1000),在Timestamp 属性fastTime和nanos分别存储秒和纳秒信息。 反例: java.util.Date.after(Date)进行时间比较时,当入参是java.sql.Timestamp时,会触发JDK BUG(JDK9已修复),可能导致比较时的意外结果。 5.不要在程序中写死一年为365天,避免在公历闰年时出现日期转换错误或程序逻辑错误。
6.避免公历闰年2月问题。闰年的2月份有29天,一年后的那一天不可能是2月29日。
使用枚举值来指代月份。如果使用数字,注意Date,Calendar等日期相关类的月份month取值在0-11之间。 说明:参考JDK原生注释,Month value is 0-based. e.g., 0 for January. 正例: Calendar.JANUARY,Calendar.FEBRUARY,Calendar.MARCH等来指代相应月份来进行传参或比较。 (六) 集合处理
1.关于hashCode和equals的处理,遵循如下规则:
1) 只要覆写equals,就必须覆写hashCode。 2) 因为Set存储的是不重复的对象,依据hashCode和equals进行判断,所以Set存储的对象必须覆写这两种方法。 3) 如果 自定义对象作为Map的键,那么必须覆写hashCode和equals。 说明:String因为覆写了hashCode和equals方法,所以可以愉快地将String对象作为key来使用。 2.判断所有集合内部的元素是否为空,使用isEmpty()方法,而不是size()==0的方式。 说明:在某些集合中,前者的时间复杂度为O(1),而且可读性更好。 3.在使用java.util.stream.Collectors类的toMap()方法转为Map集合时,一定要使用含有参数类型为BinaryOperator,参数名为mergeFunction的方法,否则当出现相同key值时会抛出IllegalStateException异常。
说明:参数mergeFunction的作用是当出现key重复时,自定义对value的处理策略。 4.在使用java.util.stream.Collectors类的toMap()方法转为Map集合时,一定要注意当value为null时会抛NPE异常。
说明:在java.util.HashMap的merge方法里会进行如下的判断: if (value == null || remappingFunction == null) throw new NullPointerException(); 5.
使用kafka用户密码配置访问权限
01
—
配置jaas 文件
配置server jaas 文件
[root@web148 kafka]# cat config/kafka_server_jaas.conf KafkaServer { org.apache.kafka.common.security.plain.PlainLoginModule required username="ydwydy" password="ydwydy#_$" user_ydwydy="ydwydy#_$";};KafkaClient { org.apache.kafka.common.security.plain.PlainLoginModule required username="ydwydy" password="ydwydy#_$";};Client { org.apache.kafka.common.security.plain.PlainLoginModule required username="ydwydy" password="ydwydy#_$";}; username:用户名,连接kafka时需要提供的账号信息
password:密码,连接kafka 提供的密码
user_usernmae:user_ + username,等号后是跟此用户的密码
client jaas配置文件:
[root@web148 kafka]# cat config/kafka_client_jaas.conf KafkaClient { org.apache.kafka.common.security.plain.PlainLoginModule required username="ydwb2b" password="ydwb2b@_@" user_ydwb2b="ydwb2b@_@";}; zk jaas 配置文件
[root@web148 kafka]# cat config/kafka_zoo_jaas.conf Server{ org.apache.kafka.common.security.plain.PlainLoginModule required username="ydwb2b" password="ydwb2b@_@" user_ydwb2b="ydwb2b@_@";}; 02
—
kafka启动命令修改
启动配置位置随自己的的路径和名称变动
zookeeper-server-start.sh 启动文件配置
[root@web148 kafka]# cat bin/zookeeper-server-start.
记得上次讲了USB的一些基础后就没有深入下去了,上周工作很忙,这周又没啥状态,把spi和i2c的一些所学的总结下后,现在终于可以开始了USB了,对于其系统结构,设备描述符,数据传输方式相信都有所了解之后呢,肯定要知道具体的一些数据啊,流程图啊什么的,那样才能更好的理解,还是先看看下面这个图吧。
先看下上面的图,相信这个图很好理解吧?恩,看着挺熟悉的吧?下面还是介绍下吧。公司是有USB分析仪,不过看过,没用过,这东西特贵。至于用,也是很简单的,插好线后,设置一些功能,点一下运行就OK,然后就有上面的图了。上图是用国嵌资料中的,公司里的东西,不好拿来用。
USB数据是由二进制数字串构成的,首先数字串构成域(有七种),域再构成包,包再构成事务(IN、OUT、SETUP),事务最后构成传输(中断传输、并行传输、批量传输和控制传输)。
1、传输(中断、批量、同步、控制)
这里的Transfer是传输方式,这个是控制传输GET,获取描述符。
这个也是Transfer,她是控制传输SET,设置地址。
2、事务(IN、 OUT、 SETUP)
这个是setup事务。
这个是IN事务。
这个就是OUT事务了。
3、包(令牌包(SETUP)、数据包(DATA)、握手包(ACK)和特殊包)
这个是setup事务中的包,看Dir可以知道,有hostàdevice的,也有deviceàhost的。
4、域(同步域(Sync)、标识域(PID)、地址域(ADDR)、端点域(ENDP)、
帧号域(FRAM)、数据域(DATA)、校验域(CRC))
还是上面这个图,看着有Sync,ADDR,CRC5,DATA等,这些域。
所以,域组成了包,包又组成了事务,事务组成了一次传输。相信,这样的解释,对于USB协议来说,可以理解得很多很多了吧。
什么是同源策略 同源策略最早是由Netscape提出的一种安全策略,目前所有支持JavaScript的浏览器都使用这个策略。
同源策略要求:客户端脚本在没有明确授权的情况下,不能读写不同源网址的数据和资源(如HTTP头、Cookie、DOM、localStorage等)。
同源策略只是一个规范,并不是强制要求,各大厂商的浏览器只是针对同源策略的一种实现。它是浏览器最核心也是最基本的安全功能,如果缺少了同源策略,则浏览器的正常功能可能都会受到影响。 同源是指:
域名相同协议相同端口相同 例:ziv.com
协议是 http://
域名是 ziv.com
端口是 80 (默认端口)
以下网址与 ziv.com的同源情况如:
http://www.ziv.com/pc/demo.html 同源 http://ziv.com/h5/demo.html 不同源 域名不同 http://www.ziv.com:81/h5/demo.html 不同源 端口不同 https://www.ziv.com/h5/demo.html 不同源 协议不同 同源策略的意义
当两个网址是非同源时,它们之间的交互会有以下限制:
Cookie、LocalStorage和IndexDB无法相互读取DOM无法相互获取AJAX请求不能发送 这些限制都是出于对安全的考虑,都是有必要的。比如,你登录了知乎账号,然后打开了另一个网站,这个网站上的JavaScript可以跨域读取你的知乎账号数据,那这样就毫无隐私可言。又比如,一个恶意网站嵌入了银行账号登录页面,如果没有同源限制,恶意网页的JavaScript就可以获取用户登录的用户信息,想象一下如果是这样后果是不是很严重。
当然,同源策略也会带来一些弊端,导致我们合理的用途也会受到影响。因此,在开发过程中,我们常常需要通过跨域来规避限制。
几种跨域的方法: document.domain
document.domain 可以用来得到当前网页的域名,同时市场上主流浏览器都支持domain可写,但是只能赋值为当前域名或者基础域名,如果赋值成当前域名的子域名就会报错。
如果两个网页一级域名相同,二级域名不同,则可以通过设置相同的document.domain实现cookie共享和iframe窗口(或window.open打开的窗口)与父窗口之间的通信。
比如,a网页是 http://a.ziv.com/a.html,b网页是http://b.ziv.com/b.html,然后设置它们的document.domain为:
document 那么,a网页设置的cookie,在b网页可以通过js拿到,同样b网页设置的cookie,在a网页也可以通过js拿到。它们的cookie是相互共享的。
如果在a网页通过iframe将b网页设置为a的子窗口:
<iframe id="iframe" src="http://b.ziv.com/b.html"></iframe> 那么,a、b窗口可以相互获得彼此的DOM。
在a网页中
document.getElementById("iframe").contentWindow.document 通过上面的代码可以获取b窗口的DOM。
在b窗口中
window 通过上面的代码可以获取a窗口的DOM。
注意:domain的使用必须在一级域名相同时,才能规避同源限制 window.name
window.name是浏览器窗口的一个属性,在一个窗口的生命周期里,不论是否同源,窗口里载入的所有页面都有权限对window.name进行读写。利用这一特性,我们可以实现在同一个窗口里,载入的不同网页之间的通信。
下面举个实例说明下如何使用window.name进行跨域:
原理:这里用到两个特性,
在一个窗口下,先后载入的页面都可以对window.name进行读写同源或者一级域名相同并且domain相同的父子窗口可以相互获得DOM 首先,需要三个页面
http://a.ziv.com/a.html 获得数据、处理数据的页面http://a.ziv.com/proxy.html 中间(代理)页面,一般是没有内容的html文件,必须与a页面一级域名相同,为了使a页面能够获得window.name这个属性http://b.viz.com/data.html 拥有数据的页面 具体步骤如下:
在数据页面data.html中通过window.name,设置需要的数据。
<script type="text/javascript">
window.name = 'data!
python strip() 函数和 split() 函数:
strip是删除的意思;split则是分割的意思。strip可以删除字符串的某些字符,而split则是根据规定的字符将字符串进行分割。
1 Python strip()函数介绍:
声明:s为字符串,x为要删除的字符序列
s.strip(x) 删除s字符串中开头、结尾处为x的序列字符
s.lstrip(x) 删除s字符串中开头处为x的序列字符
s.rstrip(x) 删除s字符串中结尾处为x的序列字符
注意:
(1)当x为空时,默认删除空白符(包括’\n’, ‘\r’, ‘\t’, ’ ')
(2)这里的x序列是只要边(开头或结尾)上的字符在删除序列内,就删除掉。
例如,
>>> a = ' 123' >>> a ' 123' >>> a.strip() '123' (2)这里的x删除序列是只要s字符串上(开头或结尾),就删除掉。
例如,
>>> a = '123abc' >>> a.strip('21') '3abc' >>> a.strip('12') '3abc' 2 python split()函数介绍说明:
Python中没有字符类型的说法,只有字符串,这里所说的字符就是只包含一个字符的字符串!!!
(1)按某一个字符分割,如‘.’
>>> str = ('www.google.com') >>> print str www.google.com >>> str_split = str.split('.') >>> print str_split ['www', 'google', 'com'] (2)按某一个字符分割,且分割n次。如按‘.
Nginx访问限制模块limit_conn_zone 和limit_req_zone配置使用 nginx可以通过limit_conn_zone 和limit_req_zone两个组件来对客户端访问目录和文件的访问频率和次数进行限制,另外还可以善用进行服务安全加固,两个模块都能够对客户端访问进行限制,具体如何使用要结合公司业务环境进行配置。
如能善用此模块能够对 cc、ddos等此类的攻击进行有效的防御。
一:nginx访问限制模块简介
nginx限速配置指令
1.
指令
limit_zone
语法:limit_conn_zone $variable zone=name:size;
默认值:no
使用字段:http
指令描述会话状态存储区域。
会话的数目按照指定的变量来决定,它依赖于使用的变量大小和memory_max_size的值。
2.
指令
limit_conn
语法:limit_conn zone_name max_clients_per_ip
默认值:no
使用字段:http, server, location
指令指定一个会话的最大同时连接数,超过这个数字的请求将被返回”Service unavailable” (503)代码。
如下例:
http { imit_conn_zone $binary_remote_addr zone=one:10m; ............ server { listen 80; server_name www.abc.com; location / { limit_conn one 1; #这将指定一个地址只能同时存在一个连接。“one”与上面的对应,也可以自定义命名 limit_rate 300k; } } limit_zone: 是针对每个IP定义一个存储session状态的容器.这个示例中定义了一个10m的容器,按照32bytes/session, 可以处理320000个session。
limit_conn one 1:限制每个IP只能发起一个并发连接。
limit_rate 300k: 对每个连接限速300k. 注意,这里是对连接限速,而不是对IP限速。如果一个IP允许两个并发连接,那么这个IP就是限速limit_rate×2。
nginx限制访问频率配置指令
3.
指令
limit_req_zone
在某些情况下,我们需要模拟网络很差的状态来测试软件能够正常工作,比如网络延迟、丢包、乱序、重复等。linux 系统强大的流量控制工具 tc 能很轻松地完成,tc 命令行是 iproute2 软件包中的软件,可以根据系统版本自行安装。
流量控制是个系统而复杂的话题,tc 能做的事情很多,除了本文介绍的还有带宽控制、优先级控制等等,这些功能是通过类似的模块组件实现的,这篇文章介绍的功能主要是通过 netem 这个组件实现的。netem 是 Network Emulator 的缩写,关于更多功能以及参数的详细解释可以参阅 tc-netem 的 man page。
网络状况模拟 网络状况欠佳从用户角度来说就是下载东西慢(网页一直加载、视频卡顿、图片加载很久等),从网络报文角度来看却有很多情况:延迟(某个机器发送报文很慢)、丢包(发送的报文在网络中丢失需要一直重传)、乱序(报文顺序错乱,需要大量计算时间来重新排序)、重复(报文有大量重复,导致网络拥堵)、错误(接收到的报文有误只能丢弃重传)等。
对于这些情况,都可以用 netem 来模拟。需要注意的是,netem 是直接添加到网卡上的,也就是说所有从网卡发送出去的包都会收到配置参数的影响,所以最好搭建临时的虚拟机进行测试。
在下面的例子中 add 表示为网卡添加 netem 配置,change 表示修改已经存在的 netem 配置到新的值,如果要删除网卡上的配置可以使用 del:
# tc qdisc del dev eth0 root 1. 模拟延迟传输 最简单的例子是所有的报文延迟 100ms 发送:
# tc qdisc add dev eth0 root netem delay 100ms 如果你想在一个局域网里模拟远距离传输的延迟可以用这个方法,比如实际用户会访问外国网站,延迟为 120ms,而你测试环境网络交互只需要 10ms,那么只要添加 110 ms 额外延迟就行。
在我本地的虚拟机中实验结果:
[root@node02 ~]# tc qdisc replace dev enp0s8 root netem delay 100ms [root@node02 ~]# ping 172.
最近需要用python做一个GUI,实现实时采集数据并显示的功能。作为一个还没学过python的小白,在经历了两三周断断续续的学习和请教学长之后,总算是做出了一些成果,特于此记录一下学习过程。
一、了解Python3基础语法
因为做我这个GUI不需要太复杂的语法或者功能,我简单的浏览了一个很不错的Python3教程:
我觉得做GUI需要的基础语法,里面几章的内容就大概可以。
紧接着,我选择了很好用的Python IDE,Pycharm作为编译器。
二、库的选择和学习
Python令我很惊喜的就是库太强大了,几乎无所不包,大大降低了上手难度。就像当初玩单片机遇到Arduino一样。
Python做GUI的库有好几个,我选择了上手比较容易的tkinter,它创建GUI的流程大体上就是,首先创建顶层窗口对象,然后创建其他组件放进该对象中,最后进入主事件循环:循环刷新窗口。所以在布局的过程中,布局到哪里,对应的功能就相应的跟在后面。
由于实时显示采集数据和串口助手功能很相似,所以我决定先设计一个最普通的串口助手,为后面GUI的框架再用以改进。
我最开始想的大概布局就是这样:
接下来最重要的就是学会使用tkinter的各个组件了,这边我姑且以自己的理解总结一下我用到的一些组件和编程的思路。
1. 创建顶层窗口对象,我就叫它父容器
GUI = tk.Tk() # 创建父容器GUI
GUI.title("Serial Tool") # 父容器标题
GUI.geometry("460x380") # 设置父容器窗口初始大小,如果没有这个设置,窗口会随着组件大小的变化而变化
此时的效果如下:
2. 接下来是每个子容器及其组件的创建
首先是调试信息窗口,我设想的是一个带有滚动条的窗口,可以显示当前的操作状态和一些操作信息,当窗口显示满的时候可以自动往下滚动显示。
在这里,我用到的组件主要有LabelFrame,ScrolledText,grid,place,button,Entry。
LabelFrame组件会自动绘制一个边框将子组件包围起来,并在它们上方显示一个文本标题,组件选项如下:
咋一看好多参数,其实很多都可以使用默认参数,自定义几个参数即可。
ScrolledText组件是创建一个带有滚动条的文本窗口,全部参数选项有哪些我也没搞清楚,因为它是Text的一个子组件,所以Text部分选项参数它也可以调用,其中Text的全部选项我就不贴了,只选取一个贴一下:
我在这里使用的是选项是wrap=tk.WORD,这个值表示在行的末尾如果有一个单词跨行,会将该单词放到下一行显示,比如输入hello,he在第一行的行尾,llo在第二行的行首, 这时如果wrap=tk.WORD,则表示会将 hello 这个单词挪到下一行行首显示。
grid,pack,place是tkinter的三个布局器。
gird的实现机制是将窗口逻辑上分割成表格,在指定的位置放置想要的组件,主要参数如下:
pack采用块的方式组织配件,它是一个弹性的容器,容器的大小会随着内部子容器的大小而变化,但是可以使用.propagate(False),限定组件的大小不变。如果不指定pack的option参数,pack会从上到下的放置组件。主要参数如下:
grid采用行列确定位置,行列号只是指定放置的相对位置,而不是实际的像素坐标。行列交汇处为一个单元格。每一列中,列宽由这一列中最宽的单元格确定。每一行中,行高由这一行中最高的单元格决定。组件并不是充满整个单元格的,你可以指定单元格中剩余空间的使用。你可以空出这些空间,也可以在水平或竖直或两个方 向上填满这些空间。你可以连接若干个单元格为一个更大空间, 这一操作被称作跨越。创建的单元格必须相邻。主要参数如下:
Place 布局管理可以显式的指定控件的绝对位置或相对于其他控件的位置. 要使用 Place 布局, 调用相应控件的 place() 方法就可以了。说简单点,指定一个坐标即可放置组件。
简单了解完这三个布局器说实话一头雾水,不过实际用起来多尝试很快就可以理解它们的作用,我每个子容器主要是使用place,因为简单暴力,直接指定坐标,指哪放哪。grid和pack多用在子容器内部布局使用。
button组件用于实现各种各样的按钮,选项参数如下:
咋一看好多参数,其实很多都可以使用默认参数,自定义几个参数即可。
Entry组件通常用于获取用户输入的文本,选项参数如下:
好了,组件介绍完毕可以开始布局了,首先我的调试信息窗口写法如下:
Information = tk.LabelFrame(GUI, text="操作信息", padx=10, pady=10) # 创建子容器,水平,垂直方向上的边距均为10
Information.place(x=20, y=20)
Information_Window = scrolledtext.
首先需要进入bios,戴尔进入bios方法:1.重启电脑,在重启过程中,点按F2;2.重启电脑,在重启过程中,点按F12,出现界面,在下图红框位置回车。 3.下面的是戴尔独有的BIOS的界面, 4.进入BIOS就开始正文了,左侧点开 Secure Boot 展开后选择 Secure Boot Enabled ,然后在右侧选择 Disadled ,,出现的对话框选 yes ,然后绿框位置 Apply 会亮起,点击 Apply 5.左侧点开 Advanced Boot Options ,然后右侧把 Enable Legacy Option ROMs 选项打上对勾,然后在点击 Apply 6.左侧点开 Boot Sequence 右侧选项改成 legacy ,然后点Apply 7.戴尔关闭UEFI,开启legacy,设置就完成了,最后点右下角的 Exit 退出就好了 错误情况:步骤4无法打勾在步骤4的时候,打勾可能出现以下错误 解决方法:点开左侧 cecurity ,选择 PTT Security ,在右侧取消掉 PTT on的对勾
package com.lin.utils; import java.math.BigInteger; import javax.crypto.Cipher; import javax.crypto.KeyGenerator; import javax.crypto.spec.SecretKeySpec; import org.apache.commons.codec.binary.Base64; import org.apache.commons.lang3.StringUtils; import sun.misc.BASE64Decoder; /** * AES的加密和解密 * @author libo */ public class Aes { //密钥 (需要前端和后端保持一致) private static final String KEY = "abcdefgabcdefg12"; //算法 private static final String ALGORITHMSTR = "AES/ECB/PKCS5Padding"; /** * aes解密 * @param encrypt 内容 * @return * @throws Exception */ public static String aesDecrypt(String encrypt) { try { return aesDecrypt(encrypt, KEY); } catch (Exception e) { e.
用的element以及antd图标种类都比较少,不够实用,学别人引用svg的图标库
一、引入svg准备 安装依赖npm install svg-sprite-loader --save-dev配置build文件夹中的webpack.base.conf.js
添加1:exclude: [resolve('src/icons')],
添加2: { test: /\.svg$/, loader: 'svg-sprite-loader', include: [resolve('src/icons')], options: { symbolId: 'icon-[name]' } }, 位置:
在src/components下新建文件夹SvgIcon及文件index.vue,
index.vue中内容如下 <template> <svg :class="svgClass" aria-hidden="true" v-on="$listeners"> <use :xlink:href="iconName"/> </svg> </template> <script> export default { name: 'SvgIcon', props: { iconClass: { type: String, required: true }, className: { type: String, default: '' } }, computed: { iconName() { return `#icon-${this.iconClass}` }, svgClass() { if (this.className) { return 'svg-icon ' + this.
Join语法有很多inner和outer,还有left、right,有的时候会真有点分不清楚。
假设我们有两张表。Table A 是左边的表。Table B 是右边的表。其各有四条记录,其中有两条记录name是相同的,如下所示:让我们看看不同JOIN的不同
1.INNER JOIN
SELECT * FROM TableA INNER JOIN TableB ON TableA.name = TableB.name
2.FULL [OUTER] JOIN (1)
SELECT * FROM TableA FULL OUTER JOIN TableB ON TableA.name = TableB.name
4.RIGHT [OUTER] JOIN
RIGHT OUTERJOIN 是后面的表为基础,与LEFT OUTER JOIN用法类似。这里不介绍了。
5.UNION 与 UNION ALL
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。 请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。UNION 只选取记录,而UNION ALL会列出所有记录。
(1)SELECT name FROM TableA UNION SELECT name FROM TableB
选取不同值
表元数据里有数据量级的记录,count(*)不加任何where条件,那么直接读取表元数据,不走MR,
修改hive的参数,把count缓存关闭,问题解决!
set hive.compute.query.using.stats=false;
linux系统(ubuntu)下安装exe文件 昨天将家中的旧笔记本翻出来安装了ubuntu20.04.1,想在电脑中安装exe文件时,不能直接打开。
于是借鉴网络中的方法(https://blog.csdn.net/weixin_42445727/article/details/82688333?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522160670040219724827630005%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=160670040219724827630005&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~baidu_landing_v2~default-1-82688333.pc_search_result_no_baidu_js&utm_term=linux%E5%A6%82%E4%BD%95%E5%AE%89%E8%A3%85exe%E6%96%87%E4%BB%B6&spm=1018.2118.3001.4449)
1.打开终端运行 sudo apt-get install wine
2.安装完成之后 sudo apt-get update
3.cd到文件路径 wine Autorun.exe
(原文发在微信公众号“建筑工业产品经理”)
有时候需要对模型做大量的参数分析以尝试获得一些规律认识,这时若仅仅通过abaqus的cae界面手动修改参数以及前后处理,几乎不可能完成大量的分析(例如需要修改模型参数进行数百甚至上千次分析),这就需要通过写程序来提高效率。这个技能很实用,下面简述最近做此分析的过程,作为备忘。
step1:利用abaqus建立一个参数的模型并得到其inp文件。
step2:通过matlab批量修改inp文件中的参数,获得用于参数分析的批量的n个inp文件,例如要进行125个算例就可以获得125个inp文件。
参数分析一般需要选择好哪几个变量,这几个变量分别用那几个数值,例如三个参数各取值5个数,就有125个参数组合,这些参数组合提前准备好,并通过代码批量替换inp文件中的特定数据,得到125个inp文件。
step3:对批量的inp文件进行计算分析(在.bat文件中写入对n个inp的计算job,将bat文件放在abaqus工作目录中运行,abaqus可依次计算这n个job),得到n个odb文件;
step4:在abaqus的cae界面中对其中一个odb文件录制宏,得abaqus自动生成的.py文件(python语言代码写的后处理操作);
step5:修改与宏所对应的.py文件,加入循环语句,进而自动对n个odb文件进行后处理,分别提取所需要的结果。将所关心的数据写入到txt文件中,至此得到了含有n个算例下所关心的数据;
step6:在matlab中进一步分析n个算例的数据结果,得到参数分析所需要的图表,讨论与分析。
小结:整个过程似乎有点繁琐,是因为我对于python并不熟悉,所以有些工作通过matlab来完成。也许有更简单的办法,有朋友分享一下么?
目录:
1. 理解PSR4 规范
2. 理解composer autoload 的实现
3. 理解yii2 autoload的实现
4. yii2 autoload 与 composer autoload 的联系与区别
5. yii2 核心类的 加载 流程, classmap 作用及意义
6. yii2 container 类/对象 的作用,如何自定义自己的container类
7. yii2 路由规则类,路由管理类 特点,如何自定义自己的路由规则类。
8. 框架常用的函数,但平时写业务不常用的函数
9. Application 类
10. 异常处理的注册,及异常处理
11. 日志处理
1.PSR4 规范、2. composer autoload 的实现 参考博客:
3. yii2 autoload 的实现 vendor/yiisoft/yii2/classes.php 里边定义了 classMap
classMap 是 yii2 核心包 里边 的类的map; 像独立的yii2 包的类不在此数组内:如 yii\gii ; yii\debug
vendor/yiisoft/yii2/Yii.php
spl_autoload_register(['Yii', 'autoload'], true, true); 注意 第三个参数 true 表示优先 从 yii2 的 autoload 函数 去加载类,再尝试 用 composer 的autoload 函数去 加载类。
Introduction 特征融合的方法很多.如果数学化地表示,大体可以分为以下几种:
X + Y \textbf{X}+\textbf{Y} X+Y: X \textbf{X} X、 Y \textbf{Y} Y表示两个特征图, + + +表示元素级相加. 代表如ResNet、FPN X c o n c a t Y \textbf{X} \; concat\;\textbf{Y} XconcatY . c o n c a t concat concat表示张量 拼接操作。 代表如GoogleNet、U-Net X + G(X) ⋅ X \textbf{X}+\textbf{G(X)}\cdot\textbf{X} X+G(X)⋅X. G ( ⋅ ) \textbf{G}(\cdot) G(⋅)是注意力函数。这里表示自注意力机制。代表如SENet、 CBAM、Non-local G(Y) ⋅ X + Y \textbf{G(Y)}\cdot\textbf{X}+\textbf{Y} G(Y)⋅X+Y. 同样是将注意力机制作用在一个特征图上,而权重信息来源于对方。代表如GAU G(X) ⋅ X + ( 1 − G(X) ) ⋅ Y \textbf{G(X)}\cdot\textbf{X}+(1-\textbf{G(X)})\cdot\textbf{Y} G(X)⋅X+(1−G(X))⋅Y.
区间和的个数 描述 困难
给定一个整数数组 nums,返回区间和在 [lower, upper] 之间的个数,包含 lower 和 upper。
区间和 S(i, j) 表示在 nums 中,位置从 i 到 j 的元素之和,包含 i 和 j (i ≤ j)。
说明:
最直观的算法复杂度是 O(n^2) ,请在此基础上优化你的算法。
示例:
输入: nums = [-2,5,-1], lower = -2, upper = 2, 输出: 3 解释: 3个区间分别是: [0,0], [2,2], [0,2],它们表示的和分别为: -2, -1, 2。 解题 题目是要找一个区间,这个区间中的数据的和在lower和upper之间
这个区间可以只包含一个数
求一共有多少个这样的区间
先按暴力来一下最简单的解法
不过超时了
class Solution: def countRangeSum(self, nums: List[int], lower: int, upper: int) -> int: n = len(nums) res = 0 for i in range(n): s = 0 for j in range(i, n): s += nums[j] if lower <= s <= upper: res += 1 return res 不过使用java还是可以通过所有用例的
在Java中使用Get/Post方式发送Http请求 RESTfulClient工具类:
package com.fsc.civet.mongo.util;import java.io.File;import java.io.IOException;import java.nio.charset.Charset;import java.util.ArrayList;import java.util.List;import org.apache.http.Consts;import org.apache.http.HttpEntity;import org.apache.http.HttpResponse;import org.apache.http.NameValuePair;import org.apache.http.ParseException;import org.apache.http.client.entity.UrlEncodedFormEntity;import org.apache.http.client.methods.HttpGet;import org.apache.http.client.methods.HttpPost;import org.apache.http.client.methods.HttpPut;import org.apache.http.client.methods.HttpRequestBase;import org.apache.http.conn.HttpHostConnectException;import org.apache.http.entity.ContentType;import org.apache.http.entity.StringEntity;import org.apache.http.impl.client.DefaultHttpClient;import org.apache.http.message.BasicNameValuePair;import org.apache.http.params.BasicHttpParams;import org.apache.http.params.HttpConnectionParams;import org.apache.http.entity.mime.HttpMultipartMode;import org.apache.http.entity.mime.MultipartEntity;import org.apache.http.entity.mime.MultipartEntityBuilder;import org.apache.http.entity.mime.content.StringBody;import org.apache.http.params.HttpParams;import org.apache.http.protocol.HTTP;import org.apache.http.util.EntityUtils;import org.json.JSONException;import org.json.JSONObject;public class RESTfulClient { public static String SERVER_URL = ""; public static String REQUEST_PATH = ""; public static String REQUEST_URL = SERVER_URL + REQUEST_PATH; public static String GET_CONTENT_TYPE = "application/json"; public static String GET_ACCEPT = "
Video ID / sCPN :每个视频独特的、独有的ID / 用于识别问题的字符串(开发人员适用)
Viewport / Frames:当前播放窗口的分辨率 / 视频帧数的变化情况(由于主机性能的原因导致的丢帧数)
Current / Optimal Res:视频的解析度 / 最佳解析度
Volume / Normalized:当前音量百分比 / 实际输出音量百分比(与YouTube标准音量的响度差距)
Codecs:视频类型 / 格式
Color:视频色域
Connection Speed:视频的加载速度,也就是大家常参考的数字,这个数字并不是很准确,由于YouTube使用的是小数据包、高频发送次数的调度方案,所以在延迟服务器上这个数字会很大。高延迟速率的链接速率是明显偏小的。(状态条为蓝色,加载无压力)
Network Activity:网络连接速度(状态条为蓝色,连接无压力。已经缓存完全后,为黑色)
Buffer Health:已缓存的视频时长(断网后,我们还能观看的时长)
Mystery Text:字母“ s”后的数字代表播放器的状态代码
S:播放状态 (4暂停、8播放、19快进或是快退、14加载视频中等等)
T:视频的时间轨道线
B:缓冲区间和缓冲区大小 (缓冲区的第二数字 - T(时间轨道线)= 缓冲的时间)
P:暂停
一.问题 由于编程语言提供的基本数值数据类型表示的数值范围有限,不能满足较大规模的高精度数值计算,因此需要利用其他方法实现高精度数值的计算,于是产生了大数运算。尤其是乘法运算,下面就是大整数的乘法的过程(加 减法都一样的原理)。
二.解决问题的方法 方法一(传统的相乘逐步相加) 乘法规律,一个数的第i位和另一个数的第j位相乘,一定会累加到结果的第i+j位,结果的数组一个数组元素存2位数,最后对结果整除得到进位,mod得到余数就是i+j位的数字,最后打印出来。
对于大整数比较方便的输入方法是,①按字符型处理,存储在字符串数组s1、s2中,计算结果存储在整型数组ans中。 ②通过字符的ASCII码,数字字符可以直接参与运算,i位数字与j位数字相乘的表达式为:(s1[i]-‘0’)*(s2[j]-‘0’)。 ③每一次数字相乘的结果位数是不固定的,而结果数组中每个元素只存储一位数字,所以用变量t暂存结果,对t mod运算得到的就是ans[i+j]的值,若超过1位数则进位,用变量b存储。
这种做法的时间复杂度为o(n^2)
c语言源码:
#include <stdio.h> #include <string.h> #include <stdlib.h> #include <math.h> int max(int a,int b){ return a>b?a:b; } int main() { char s1[205], s2[205],ans[1000]; int str1[205],str2[205]; int len1, len2,i; while( scanf("%s%s", s1, s2)!=EOF){ len1 = strlen(s1), len2 = strlen(s2); memset(str1,0,205);//初始化0 memset(str2,0,205); memset(ans,0,1000); int len = 0; for(i = 0; i < len1; ++ i) str1[i] = s1[len1 - 1 - i] - '0'; for(i = 0; i < len2; ++ i) str2[i] = s2[len2 - 1 - i] - '0'; for( i = 0; i < len1; ++ i) { int b = 0; //每遍历完数组a的一个数,进位b都要初始化为0 for(int j = 0; j < len2 || b; ++ j)//当str[j]没遍历完,或者最高位满十需要进位,进位不为0 { int t = ans[i + j] + str1[i]*str2[j] + b; ans[i + j] = t%10; //余数就是该ans[i+j]位置的数 b = t/10;//进位 //len = max(len, j + i); } len = i+j-1 //最终的位数 } for( i = len; i >= 0; -- i) //倒置输出 printf("
最近很多朋友都向笔者表示了想要购买新MacBook的想法,一方面是由于M1芯片性能非常强劲,另一方面也在于想要体验一下macOS——Windows系统上的流氓软件弹窗,实在了忍无可忍了! macOS兼容了iOS App后,生活娱乐方面的应用得到了很大程度的补足,而且没有莫名其妙的弹窗,这足以让不少用户产生从Windows生态转向macOS生态的意向。 但客观来说,如果想要兼顾方方面面,macOS上的软件生态依然是不能完全顶替Windows的。 那么要如何解决Windows上的流氓弹窗,让Windows有一个更好的体验?很多朋友都会选择一些弹窗拦截工具,但这些工具也不是万能的。有时候出现一个弹窗,你甚至是不知道来自哪个软件! 今天,笔者就跟大家分享两个方法,来找到弹窗对应的软件,让乱弹窗的软件见鬼去吧! Process Explorer 官方下载:https://docs.microsoft.com/en-us/sysinternals/downloads/process-explorer 这是一款微软自家的工具,它本身是由Sysinternals开发的,现在已经被微软收购。Process Explorer本身是一个高级的任务管理器,他可以用来管理系统不同的进程,远比Win10自带的任务管理器更加直观。不过这里,我们着重用到它的弹窗检测功能。 Process Explorer主界面,信息量非常丰富 Process Explorer有一个检测窗口隶属什么进程的功能。在主界面中,有一个类似瞄准镜的图标,用鼠标拖动这个图标到某个窗口中,Process Explorer自动就能分辨出这个窗口属于什么进程,这功能可谓非常实用了! 如果你看到一个莫名其妙的弹窗,不知道是什么软件导致的,就可以用它来轻松揪出弹窗的幕后黑手,清理起来毫不费力。 农民工返回擦拭坐过的椅子,心疼背后更心酸! (mebk.org)
瞬间知道窗口是什么进程发起的Revo Uninstaller 官网地址:https://www.revouninstaller.com/ 这是一个非常强力的卸载工具,它的主要功用,在于卸载电脑上某些顽固的软件。Revo Uninstaller对付弹窗也非常有一套,它自带了一个“猎人模式”,可以用来识别弹窗的归属,效果非常好。 Revo Uninstaller的猎人模式 Revo Uninstaller的猎人模式使用体验和Process Explorer是类似的。在进入到猎人模式后,就会弹出一个瞄准镜的小图标,将它拖动到某个窗口,Revo Uninstaller就可以识别出这个窗口的对应软件,并且还能进行卸载、停止进程、停止自动启动、打开所在文件夹等操作。 被耽误的福建经济,该腾飞了 (mebk.org)
猎人模式可以轻松检测窗口的所属进程、软件,帮你辨认出窗口来自哪里 和Process Explorer的检测窗口功能相比,Revo Uninstaller的猎人模式不仅仅可以检测到窗口的对应进程,还可以直接处理相关软件,功能上要更强大一些。 总结 马恩资料库官方网站 (mebk.org)
怎么样,有了这两个方法,找到弹窗对应的流氓软件,是不是方便多了?如果你想要找出电脑中会私自弹窗的流氓软件,不妨试试上文提到的工具吧,拒绝使用这些软件才是杜绝弹窗的根本方法!
1.easyui中datagrid添加单元格编辑事件
这部分代码实现两个功能
(1)在进行选择行的时候在页脚统计已选数据需要计算字段的和
(2)有一个字段可以进行编辑,在编辑完成后也要在页脚完成对该字段的统计
根据昨天的内容,可以完成不编辑字段的统计,今天的重点是需要编辑字段的统计。
代码如下:
$('#whxdg').datagrid({
fit:true,
singleSelect:false,
toolbar: '#whxtb',
showFooter:'true',
url:getRootPath()+'/handverify/findDfInfo.do?customer='+code+'&pk_org='+pk_org+'&status=2',
columns:[[ {field:'ck',checkbox:true},
{field:'BILLNO',title:'单据号',width:200,align:'center'},
{field:'BILLTYPE',title:'单据类型',width:200,align:'center'},
{field:'JINE',title:'金额',width:200,align:'center'},
{field:'YHXJE',title:'已核销金额',width:200,align:'center'},
{field:'MONEY_CR',title:'未核销金额',width:200,align:'center'},
{field:'XGHXJE',title:'修改核销金额',width:200,align:'center',editor:{type:'numberbox',options:{precision:0},min:0}},
{field:'BILLDATE',title:'单据日期',width:200,align:'center'},
{field:'HEADID',title:'单据日期',width:200,align:'center',hidden:true},
{field:'BODYID',title:'单据日期',width:200,align:'center',hidden:true}
]],
//添加单击事件,
onClickCell: function(index,field,value){
if(field == 'XGHXJE'){
$(this).datagrid('beginEdit', index);
var ed = $(this).datagrid('getEditor', {index:index,field:'XGHXJE'});
$(ed.target).focus();
}else{
$(this).datagrid('endEdit', index);
}
},
onSelect:function (index,row){
$(this).datagrid('endEdit',index);
var rows = $('#whxdg').datagrid('getFooterRows'); //获取底部页脚信息
var foot_row = rows[0];
var XGHXJE = row.XGHXJE;
if(XGHXJE == ""){
XGHXJE = 0;
}
rows[0]['JINE'] = (parseFloat(row.
习题集一
习题1:判断是否匹配成功,并输出对应匹配信息
import re
source = "1huhongqiang"
if re.match("hu",source):#if re.match is not None
print("可以匹配到")
else:
print ("没有匹配到")
if re.search("hu",source):
print ("可以匹配到")
else:
print ("没有匹配到")
习题2: 找出一个字符串中是否有连续的5个数字
>>> print re.search(r"\d{5}","1234aadd222222").group()
22222
习题3:出一个字符串中的连续5个数字,要求数字前后必须是非数字
>>> re.search(r'(\D\d{5}\D)|(^\d{5}\D)|(\D\d{5}$)|(^\d{5}$)','12567').group()
'12567'
习题4:统计一个文件中单词的数量
with open("d:\\word.txt","r") as file_obj:
print(len(re.findall(r"(\b[A-Za-z]+\b)",file_obj.read())))
习题5:把a1b23c4d非字符内容拼成一个字符串
>>> "".join(re.findall(r"[^A-Za-z]","a1b23c4d"))
'1234'
习题6:取最后一个字母
>>> re.findall(r"[A-Za-z]","ab12cd")[-1]
'd'
>>> re.search(r"[A-Za-z]$","ab12cd").group()
'd'
习题7:找出一个字符串中的所有数字
>>> pattern = re.compile(r"\d+")
>>> pattern.findall("a1cd33dd99kddd")
['1', '33', '99']
>>> pattern = re.compile(r"\d")
>>> pattern.findall("a1cd33dd99kddd")
['1', '3', '3', '9', '9']
一、数据类型 数据类型分为两大类:数值型与非数值型
数值型:整型int(不分长整型短整型),浮点型float(不区分单双精度),复数型complex,布尔型bool(true、false)
非数值型:列表list,元组tuple,集合set,字典dictionary,字符串str(不将字符和字符串分开)
二、输入输出语句 1、输入语句
a = input("请输入“),函数返回值是一个字符串,所以想要进行加运算时需要先使用int()转化为数值型。
当想要多输入时,有三种方法:
(1)
因为我们可以用序列对多个变量进行赋值,如字符串,列表,元组等。
(2).eval()函数
eval()能够以Python表达式的方式解析并执行字符串,并将返回结果输出。eval()函数将去掉字符串的两个引号,将其解释为一个变量。
作用:
a. 处理数字
单引号,双引号,eval()函数都将其解释为int类型;三引号则解释为str类型。
b.处理字符串类型的字符串
对于eval()括号中的的字符串(非数字),如果字符串带的是单引号或者是双引号都会引起NameError,这是因为eval()函数在处理字符串时会去掉其两个引号。正确应该使用一个单引号包含一个双引号组成的三引号来包含字符串。
(3).利用split函数
注意:python2中map函数返回的是一个列表,python3中map函数返回的是一个迭代器,类型是map
总结:可以用序列(字符串,列表,集合等)对多个变量进行赋值;input()函数返回值是字符串;eval()函数是去单引号和双引号,如前所述,对数值和字符串的不同作用;split()函数可定义用什么去分割字符串,返回值是列表,map(函数,序列),函数对序列中的每个值都分别作用,返回值是map类型。
二、模块 module就是py文件,py文件里可以包含变量,函数,类(其中类里可以含有很多函数)。
导入模块:
import 包名或import 包名 as 别名,使用时需要加前缀。
from 包名 import 成员名,使用时有时不用加前缀可直接引用函数,有时还是需要加前缀,其中包名可以是第三方的包也可以是自己写的包,成员名可以是py文件,可以是函数名,也可以是类名。
成员是类时且类中含有很有函数引用函数时需要加前缀
三、字符串 1、split() 描述:split() 通过指定分隔符对字符串进行切片,如果第二个参数 num 有指定值,则分割为 num+1 个子字符串。
语法:str.split(‘str’,num)
参数:str ——分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
num – 分割次数。默认为 -1, 即分隔所有。
返回值
返回分割后的字符串列表。
2、strip() 描述:strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
语法:str.strip(‘string’)
参数:sting是需要移除的字符串列
返回值:返回的是头尾移除指定字符串的新字符串
str默认是空格、换行符\n和制表符\t,num默认为-1即分割所有,当num为1时分割成两部分。
四、文件 (一)读取文件 python有三种读取文件的方式:read(),readline(),readlines()
read():返回值是一个字符串,将文本内容全都存储与这个字符串中。
readline():返回值是一个字符串,每次只能读取文件的一行。
readlines():返回值是一个由字符串组成的列表,将文件中每行作为一个字符串元素。
注:当读文件时,读出的文件就相当于不在文件中了,故先用read(),再用readline()和readlines()读出的都是空;当先使用一次readline(),再使用read()读出的是除第一行剩下的。
f = open('test.
SyntaxError: invalid syntax 这个报错经常遇见,但是总感觉自己的代码没有问题,根据报错提示的行也找不到错误,这些情况以及解决方法都有哪些呢?
1)丢符号类: 忘记在 if , elif , else , for , while , class ,def 声明末尾添加 冒号( : )代码中的 ( )没有成对出现,比如: for line in f: line = line.strip() …… if len(words)>1: for word in words: if not Dict.get(word[0]): Dict[word[0]]=set() Dict[word[0]].add(word[1]) else: Dict[word[0]].add(word[1]#缺少一个) for K in Dict.keys(): max_cixing_word[K]=len(Dict[K]) File "<ipython-input-6-eb7bfb9def4a>", line 48 for K in Dict.keys(): ^ SyntaxError: invalid syntax 如果我们按报错的行去找,怎么也不会发现错误,上下文去看就会发现,上一个if函数里,没有写全括号,少了一个),就会导致python认为下面的代码都属于括号里的内容,添加后此错误消失。
2)多符号类: 多了一个 “ :” #比如 def main(): print("
CentOS操作系统的使用过程中,往往会因为人为失误或者客观原因导致系统崩溃。例如我们常见的2种场景:
误操作执行rm -rf /*但及时Ctrl+C中断;
服务器断电后系统故障无法启动;
大多数的工程师应该使用过Windows PE(下文简称PE)系统,在Windows系统无法正常启动时可能会想到尝试PE模式下进行系统修复或者修复失败的情况下拷贝原有的数据。对于CentOS系统,也有类似PE系统的救援安装模式可进行尝试修复系统或者拷贝数据。
救援安装模式我们要先准备一个安装引导介质,这里以安装镜像iso文件举例。
准备工作:
安装镜像iso文件
笔记本一台
Oracle JDK
U盘或者移动硬盘(可选)
实施步骤:
笔记本安装JDK并接入服务器BMC管理口网络或者直连服务器BMC管理口(具体步骤省略)
浏览器登录BMC管理口,海康新服务器默认10.10.10.10(具体步骤省略)
打开虚拟Java控制台加载iso安装文件
打开虚拟光驱 加载iso镜像文件
重启服务器进入救援安装模式
F11进入引导菜单
选择虚拟光驱
选择Troubleshooting
选择救援安装模式
进入命令行
查看磁盘识别情况
查看磁盘
如果看不到centos_hikvisionos卷组信息,代表root和opt未能自动挂载,执行第6步进行挂载。
激活卷组挂载文件系统
vgchange -ay //激活卷组
mkdir /oldroot //创建临时挂载点
mkdir /oldopt //创建临时挂载点
mount /dev/centos_hikvisionos/root /oldroot //挂载根文件系统
mount /dev/centos_hikvisionos/opt /oldopt //挂载/opt文件系统
文件系统配置
确认网卡链路
ip a //查看网卡名称
ethtool enp65s0f1 //查看网络链路
Speed:1000Mb/s //代表网卡已连接千兆网络
链路确认
配置原网卡IP地址
ip addr add 60.1.0.3/28 dev enp65s0f1 //配置IP掩码 ip route add default via 60.
计算机中丢失OpenNI2.dll 在使用PCL点云库时,直接用pcl_mesh_sampling.exe或是pcl_mesh_samplingd.exe文件生成点云.pcd文件时会报错“:
无法启动此程序,因为计算机中丢失OpenNI2.dll。尝试重新安装该程序以解决此问题。”的错误。
生成.pcd文件的具体做法详见我的上一篇博文:
https://blog.csdn.net/m0_45866718/article/details/110263833
解决方法 (1)第一种方法:
将安装路径下OpenNI2\Tools目录中的OpenNI2.dll放到自己的exe目录下。
比如我的安装路径是C:\Program Files(x86)\OpenNI2.dll\Tools,
我的VS2013工程路径是D:\VS2013 Project\setting_PLC\setting_PLC。
将安装路径中的OpenNI2.dll放到工程路径下,大功告成。
(2)第二种方法
把OpenNI.dll放在system32文件夹下。
文章目录 前言一、OC与C的区别二、OC的数据类型三、OC面向对象和面向过程1. 类2. 对象3. 方法 四、多文件开发1.多类可指向同一个地址2.分组导航标记3.多文件开发 五、异常处理总结 前言 入职第一份工作iOS开发,师傅说先学习一下语法OC,和Android很多不同,竟然和C和Java有点类似,start!
环境:mac pro 版本10.
编译器:xcode12.2
xcode对mac版本要求很苛刻,如果安装不了就升级系统,而且Pro的cv是commond+c不是ctrl+c,每次换换快捷键就很(╥﹏╥)
一、OC与C的区别 Objective-C简称OC,是C语言的升级版,封装语法更为简单优化。
新建一个OC项目:
//导入系统的相关的使用的是“<>” #import <Foundation/Foundation.h> //导入其他非系统的类或者头文件使用的是 "" #import "Person.h" int main(int argc,const char * argv[]){ NSLog(@"Hello World!"); } .m代表message消息机制
main是OC的入口和出口,main的参数(可接收用户在运行时传递数据给程序、参数可不要)
int返回值 程序的结束状态
#import 将文件的内容拷贝到写指令的地方;其中#是预处理指令,import是include的增强(同一个文件无论import多少次,只会包含一次)。
框架:功能集 常用、Foundation框架 基础
@autoreleasepool是自动释放池(可删除、占时不必深入)
NSLog(@“Hello,world!”);是printf的增强:
(1)会输出一些调试信息(执行时间、程序名称、进程编号、线程编号、输出信息)
(2)会自动换行(最后加上\n换行只换一次,后面自动换行失效)
(3)c,oc均可输出
字符串:
(1)C语言存储:a.字符数组,b.字符指针
(2)OC:NSString指针变量,只能存储OC字符串的地址
(3)OC必须加前缀@符号
NSLog(@"OC使用字符串要加前缀@") NSLog(@"我是%@",str) 前缀:NextStep->Cocoa->Foundation框架之中
@符号:将C转为OC字符串,绝大部分关键字以@开头
注释:和C同
//单行注释 /* *多行注释 */ 函数的定义与调用(同C),编译连接执行: (1)在.m中写代码
(2)使用 编译器将源码编译为目标文件
cc -c xx.m a.预处理 b.检查语法 c.
<html>
<head>
<style>
body {margin-left: 0px;margin-top: 0px;margin-right: 0px;margin-bottom: 0px;overflow: hidden;}
</style>
</head>
<body>
<iframe src='http://hi.baidu.com/' width='100%' height='100%' frameborder='0' scrolling="yes" name="_blank" id="_blank" ></iframe>
</body>
</html>
代码强大之处:
1. 该方法完美兼容IE6,7,8 ,Fire fox,chrome,opera 等主流的浏览器;
2.同域,跨域皆支持;
3.不调用任何JS脚本;
注意三点.
1. 文件开头不能是:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
必须 是<html>开头
2. body样式中的 overflow: hidden; 绝对不对省略;
3.Iframe 中的 height='100%' 以及 滚动条不能设为no(默认是yes,不用设置即可)
好了,马上试试吧。100%不会让你失望。
1、通过SQL语句创建图书信息管理数据库,命名为“db_Library”,数据文件和日志文件放在D盘下以自己学号和姓名命名的文件夹中,数据文件的逻辑名为db_Library_data,数据文件的操作系统名为db_Library_data.mdf,文件初始大小为10MB,最大可增加至300MB,增幅为10%;日志文件的逻辑名为db_Library_log,日志文件的操作系统名为db_Library_data.ldf,文件初始大小为5MB,最大可增加至200MB,增幅为2MB。
CREATE DATABASE db_Library
ON PRIMARY (
NAME=db_Library_data,
FILENAME=‘D:\DATA\db_Library_data.mdf’,
SIZE=10MB,
MAXSIZE=300,
FILEGROWTH=10%)
LOG ON (
NAME=db_Library_log,
FILENAME=‘D:\DATA\db_Library_data.ldf’,
SIZE=5,
MAXSIZE=200,
FILEGROWTH=2 )
2、通过SQL语句在该数据库中创建模式L_C。
(二)创建和管理数据表
要求为各数据表的字段选择合适的数据类型及名称;为各数据表设置相应的完整性约束条件。
1、通过SQL语句将以下数据表创建在L_C模式下:
课程信息表(tb_course)——课程编号、课程名、先修课、学分
USE db_Library go
CREATE SCHEMA L_C GO
CREATE TABLE L_C.tb_course (
课程编号 char(10) primary key,
课程名 varchar(30) not null,
先修课 char(10),
学分 real
)
CREATE TABLE tb_course (
课程编号 char(10) primary key,
课程名 varchar(30) not null,
先修课 char(10),
学分 real
)
2、通过SQL语句将以下数据表创建在该数据库的默认模式dbo下:
图书类别信息表(tb_booktype)——类别编号、类别名称
C++标准并不支持函数模板偏特化,然而在实际开发中,我们确实需要对一些函数模板进行偏特化。本文将介绍几种函数模板偏特化的通用方案。
1. 什么是偏特化 1.1 类模板偏特化 偏特化是相对于全特化而言的,即只特化了部分模板参数,如下:
// 类模板偏特化demo template <typename T, typename Allocator_T> class MyVector { public: MyVector() { std::cout << "Normal version." << std::endl; } }; template <typename T> class MyVector<T, DefaultAllocator> { public: MyVector() { std::cout << "Partial version." << std::endl; } }; MyVector<int, MyAnotherAllocator> v1; MyVector<int, DefaultAllocator> v2; 输出结果:
Normal version. Normal version. Partial version. 后面的一个MyVector是一个偏特化版本,其只特化了Allocator_T这一个模板参数为DefaultAllocator。通过输出结果也可以看出来,其中v1, v2使用上面的一个类定义,而v3使用的是下面的特化版的类。
1.2 函数模板偏特化 和类模板偏特化同样的道理,我们尝试去对一个函数进行偏特化:
/// 函数模板偏特化demo template <typename A, typename B> void f(A a, B b) { std::cout << "