RecyclerView缓存机制 说到Android的布局,ListView肯定是最常用的控件之一了,而提到ListView就不得不说起RecyclerView了,强大的RecyclerView不仅可以实现和ListView同样的效果,还优化了ListView中存在的各种不足之处。Android官方更加推荐使用RecyclerView。官方给RecyclerView的解释:
A flexible view for providing a limited window into a large data set.
翻译过来的意思就是一个为大数据集提供有限窗口的灵活视图。如果我们想用好这个RecyclerView,那么对于他的缓存机制我们就有了解的必要了,下面我们就来看下RecyclerView 的缓存机制
RecyclerView的缓存类 RecyclerView 有几个比较重要的缓存类:Recycler,RecycledViewPool,ViewCacheExtension
Recycler 我们先来看下源码( 部分)
public final class Recycler { final ArrayList<ViewHolder> mAttachedScrap = new ArrayList<>(); ArrayList<ViewHolder> mChangedScrap = null; final ArrayList<ViewHolder> mCachedViews = new ArrayList<ViewHolder>(); int mViewCacheMax = DEFAULT_CACHE_SIZE; RecycledViewPool mRecyclerPool; private ViewCacheExtension mViewCacheExtension; static final int DEFAULT_CACHE_SIZE = 2; ...省略... } 这个Recycler 类里就基本包含了所有的缓存类,首先说下他的成员变量
mAttachedScrap :这个变量用一个ArrayList存放了ViewHolder,这里的ViewHolder的数据是不做修改的,当使用到这里的缓存的时候是不用走adapter的绑定方法的。mChangedScrap :这个变量和上面的mAttachedScrap 一样,不过有区别的是这里存放的是已经变了的ViewHolder,使用到了这个缓存的话是需要重新走adapter的绑定方法的。mCachedViews :这个存放的是已经与RecyclerView分离了的ViewHolder,但是他依然保存了ViewHolder的信息,比如position,数据等。这里的默认的大小为2,就是mViewCacheMax这个变量,不过我们可以人为的改变他的大小,用到了RecyclerView.setItemViewCacheSize()方法。mRecyclerPool:这个就是一个缓存类,从名字中我们也可以看到,是一个缓存池。进入这个类我们可以看到: public static class RecycledViewPool { private static final int DEFAULT_MAX_SCRAP = 5; .
ubuntu18.04 安装nvidia显卡驱动 1、查询显卡型号2、添加源3、查看驱动4、安装驱动5、其他安装方式6、查看显卡信息7、报错解决办法 一定要先禁用 nouveau,参考 ubuntu单系统开机后黑屏操作方法。 1、查询显卡型号 windows下打开设备管理器,选择显示适配器,UHD是集成显卡,GeForce是独立显卡。
在Ubuntu下查询显卡型号
集成显卡输入命令:
lspci -nn | grep VGA 独立显卡输入命令如下:(推荐)
lspci -nn | grep 3D 或者
lspci | grep -i nvidia 在PCI devices上查询对应的显卡型号
我的集成显卡8086:9b41对应的型号如下:
独立显卡10de:1d13对应型号如下
与windows查询的型号一致
2、添加源 sudo add-apt-repository ppa:graphics-drivers/ppa sudo apt update 3、查看驱动 sudo ubuntu-drivers devices 终端显示如下:
➜ sudo ubuntu-drivers devices [sudo] password for aviana: == /sys/devices/pci0000:00/0000:00:1c.0/0000:01:00.0 == modalias : pci:v000010DEd00001D13sv00001028sd00000956bc03sc02i00 vendor : NVIDIA Corporation driver : nvidia-driver-460 - third-party free driver : nvidia-driver-470 - third-party free recommended driver : xserver-xorg-video-nouveau - distro free builtin 4、安装驱动 使用命令行安装
如果我们深入研究Nginx的功能还是蛮有意思的,比如我们前面有聊到UA可以控制爬虫限制和放行访问。我们也可以利用Nginx进行控制和限制URL、目录,以及IP地址的访问。比如有一些运维的时候,需要用到屏蔽某些IP地址,或者是我们某个目录只能某个IP地址访问或者限制访问。
在这篇文章中,老蒋整理Nginx常见的控制URL、目录,以及IP地址的访问权限设置案例实例记录。
1、限制指定目录扩展名后缀
location ~ ^/images/.*\.(php|php5|sh|pl|py)$ { deny all; } location ~ ^/static/.*\.(php|php5|sh|pl|py)$ { deny all; } 2、禁止直接访问txt和doc文件
location ~* \.(txt|doc)$ { if (-f $request_filename) { root /data/www/www; rewrite ^(.*) https://www.itbulu.com/ break; #可以重定向到某个URL; } } location ~* \.(txt|doc)$ { root /data/www/www; deny all; } 3、禁止访问文件和目录
#禁止访问的文件或目录 location ~ ^/(\.user.ini|\.htaccess|\.git|\.svn|\.project|LICENSE|README.md) { return 404; } 4、排除某个目录不受限制
location ~ \.well-known{ allow all; } 5、禁止访问单个目录的命令
location ~ ^/(static)/ { deny all; } location ~ ^/static { deny all; } 6、禁止访问多个目录的配置
目录
一、webpack-bundle-analyzer是什么?
二、安装
三、使用方法
1. 作为插件使用
2. 作为CLI的一个工具
一、webpack-bundle-analyzer 是什么? webpack-bundle-analyzer 是 webpack 的插件,需要配合 webpack 和 webpack-cli 一起使用。这个插件可以读取输出文件夹(通常是 dist)中的 stats.json 文件,把该文件可视化展现,生成代码分析报告,可以直观地分析打包出的文件有哪些,及它们的大小、占比情况、各文件 Gzipped 后的大小、模块包含关系、依赖项等,对应做出优化,从而帮助提升代码质量和网站性能。
二、安装 # NPM npm install --save-dev webpack-bundle-analyzer # Yarn yarn add -D webpack-bundle-analyzer 三、使用方法 1. 作为插件使用 1. 配置 webpack.config.js 文件:
// webpack.config.js 文件 const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin module.exports={ plugins: [ new BundleAnalyzerPlugin() // 使用默认配置 // 默认配置的具体配置项 // new BundleAnalyzerPlugin({ // analyzerMode: 'server', // analyzerHost: '127.0.0.1', // analyzerPort: '8888', // reportFilename: 'report.
开新坑!准备开始聊triton。
老潘用triton有两年多了,一直想写个教程给大家。顺便自己学习学习,拖了又拖,趁着这次换版本的机会,终于有机会了写了。

triton作为一个NVIDIA开源的商用级别的服务框架,个人认为很好用而且很稳定,API接口的变化也不大,我从2020年的20.06切换到2022年的22.06,两个大版本切换,一些涉及到代码的工程变动很少,稍微修改修改就可以直接复用,很方便。
本系列讲解的版本也是基于22.06。
本系列讲解重点是结合实际的应用场景以及源码分析,以及写一些triton周边的插件、集成等。非速成,适合同样喜欢深入的小伙伴。
什么是triton inference server? 肯定很多人想知道triton干啥的,学习这个有啥用?这里简单解释一下:
triton可以充当服务框架去部署你的深度学习模型,其他用户可以通过http或者grpc去请求,相当于你用flask搭了个服务供别人请求,当然相比flask的性能高很多了triton也可以摘出C-API充当多线程推理服务框架,去除http和grpc部分,适合本地部署多模型,比如你有很多模型要部署,然后分时段调用,或者有pipeline,有了triton就省去你处理显存、内存和线程的麻烦 注意,还有一个同名的triton是GPU编程语言,类似于TVM的TVMscript,需要区分,这篇文章中的triton指的是triton inference server
借用官方的图,triton的使用场景结构如下: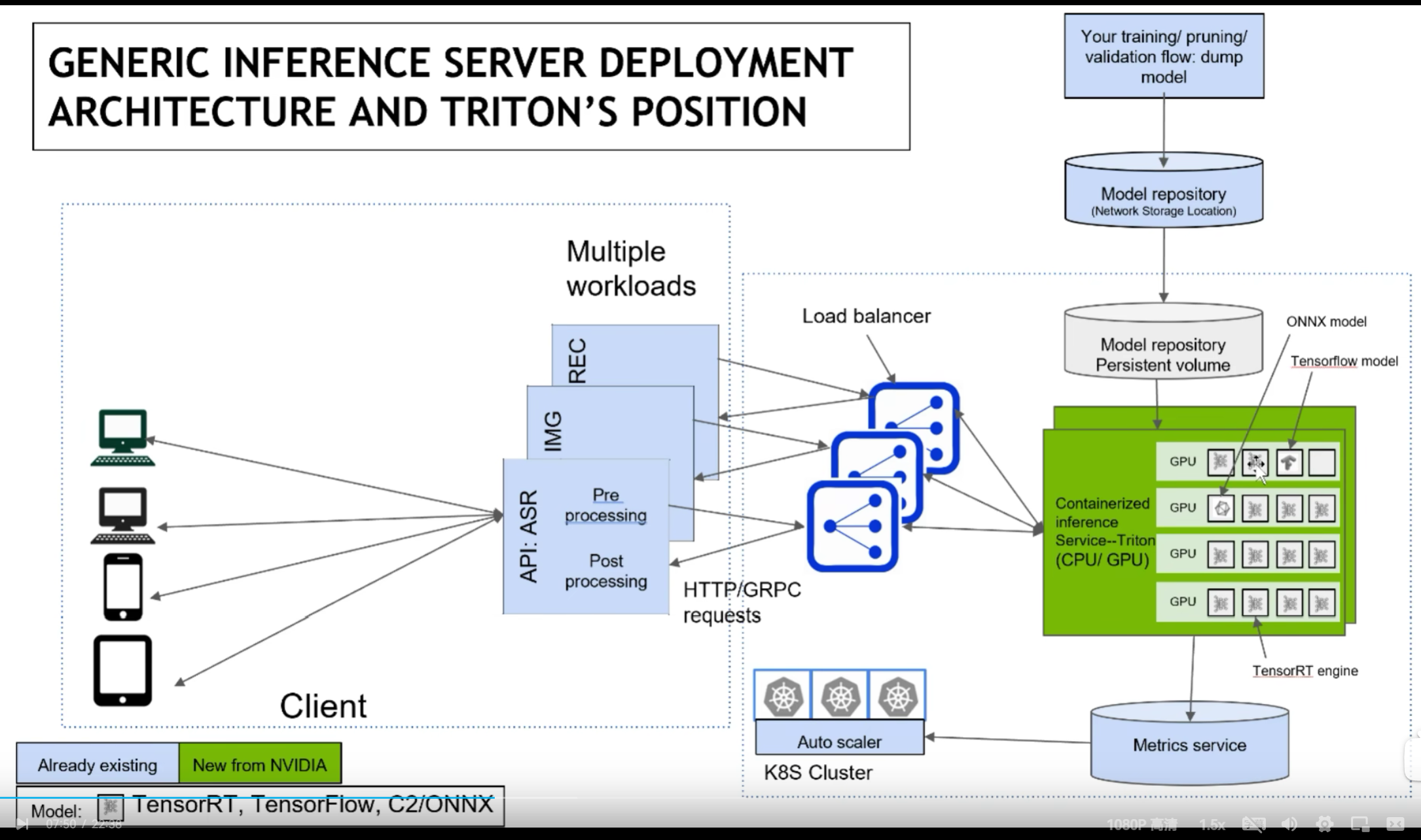
涉及到运维部分,我也不是很懂,抛去K8S后,结构清爽了些:
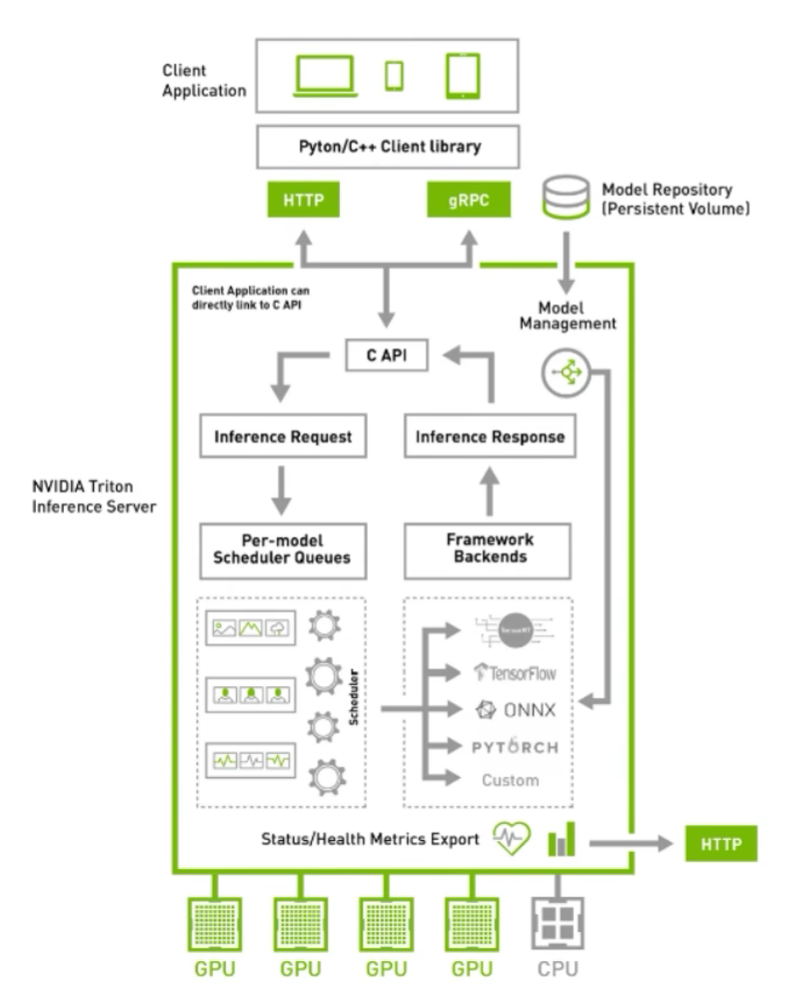
triton的一些优点 通过上述的两个结构图,可以大概知道triton的一些功能和特点:
支持HTTP/GRPC支持多backend,TensorRT、libtorch、onnx、paddle、tvm啥的都支持,也可以自己custom,所以理论上所有backend都可以支持单GPU、多GPU都可以支持,CPU也支持模型可以在CPU层面并行执行很多基本的服务框架的功能都有,模型管理比如热加载、模型版本切换、动态batch,类似于之前的tensorflow server开源,可以自定义修改,很多问题可以直接issue,官方回复及时NVIDIA官方出品,对NVIDIA系列GPU比较友好,也是大厂购买NVIDIA云服务器推荐使用的框架很多公司都在用triton,真的很多,不管是互联网大厂还是NVIDIA的竞品都在用,用户多代表啥不用我多说了吧 
如何学习triton 两年前开始学习的时候,官方资料比较匮乏, 只能通过看源码来熟悉triton的使用方式,所幸知乎上有个关于TensorRT serving不错的教程,跟着看了几篇大致了解了triton的框架结构。那会triton叫做TensorRT serving,专门针对TensorRT设计的服务器框架,后来才变为triton,支持其他推理后端的。
现在triton的教程比较多了,官方的docs写着比较详细,还有issue中各种用例可以参考,B站上也有视频教程,比两年前的生态要好了不少。
当然,最重要的,还是上手使用,然后看源码, 然后客制化。
源码学习 从triton的源码中可以学到:
C++各种高级语法设计模式不同backend(libtorch、TensorRT、onnxruntime等)如何正确创建推理端,如何多线程推理C++多线程编程/互斥/队列API接口暴露/SDK设计CMAKE高级用法 等等等等,不列举了,对于程序员来说,好的源码就是好的学习资料。当然,也可以看老潘的文章哈。
triton系列教程计划 triton相关系列也会写一些文章,目前大概规划是这些:
什么是triton以及triton入门、triton编译、triton运行triton管理模型、调度模型的方式triton的backend介绍、自定义backend自定义客户端,python和c++高级特性、优先级、rate limiter等等 编译和安装 一般来说,如果想快速使用triton,直接使用官方的镜像最快。
但是官方镜像有个尴尬点,那就是编译好的镜像需要的环境一般都是最新的,和你的不一定一致。

比如22.09版本的镜像需要的显卡驱动为520及以上,如果想满足自己的显卡驱动,就需要自行编译了。
官方也提供了使用镜像的快速使用方法:
# 第一步,创建 model repository git clone -b r22.09 https://github.com/triton-inference-server/server.git cd server/docs/examples ./fetch_models.sh # 第二步,从 NGC Triton container 中拉取最新的镜像并启动 docker run --gpus=1 --rm --net=host -v ${PWD}/model_repository:/models nvcr.
See Finer, See More!腾讯&上交提出IVT,越看越精细,进行精细全面的跨模态对比! 【写在前面】 基于文本的人员检索是基于文本描述来查找查询对象。关键是要学会在视觉-文本模态之间建立一种共同的潜在空间映射。为了实现这一目标,现有的工作利用分割来获得明确的跨模态对齐或利用注意力来探索显著的对齐。这些方法有两个缺点:1)标记跨模态对齐是耗时的。2)**注意力方法可以探索显著的跨模态对齐,但可能会忽略一些微妙和有价值的对。**为了解决这些问题,作者提出了一个隐式视觉-文本(IVT)框架,用于基于文本的人员检索。与以往的模型不同,IVT利用单一网络来学习两种模态的表示,这有助于视觉-文本的交互。为了探索细粒度的对齐,作者进一步提出了两种隐式语义对齐范式:多层次对齐(MLA)和双向掩码建模(BMM)。MLA模块在句子、短语和单词层面探索更精细的匹配,而BMM模块旨在挖掘视觉和文本模态之间更多的语义对齐。作者在公共数据集(包括CUHK- pedes、RSTPReID和ICFG-PEDES)上进行了大量实验,以评估提出的IVT。即使没有明确的身体部分对齐,本文的方法仍然达到最先进的性能。
1. 论文和代码地址 See Finer, See More: Implicit Modality Alignment for Text-based Person Retrieval
论文地址:https://arxiv.org/abs/2208.08608
代码地址:https://github.com/TencentYoutuResearch/PersonRetrieval-IVT
2. 动机 人的重新识别(re-ID)有很多应用,例如在监控中寻找嫌疑人或丢失的孩子,在超市中跟踪顾客。基于文本的人物检索(text-based person retrieval, TPR)作为人物re-ID的子任务,近年来备受关注。这是因为文本描述很容易访问,并且可以以自然的方式描述更多的细节。比如,警察通常会查看监控录像,并从目击者那里获取证词。文本描述可以提供补充信息,在缺少图像的场景中甚至是至关重要的。
基于文本的人物检索需要对视觉形态和文本形态进行处理,其核心是学习二者之间的共同潜在空间映射。为了实现这一目标,目前的工作首先利用不同的模型来提取特征,即ResNet50用于视觉形态,LSTM或BERT用于文本形态。然后,他们致力于探索视觉-文本部分对的语义对齐。然而,这些方法至少有两个缺点,可能导致次优的跨模态匹配。首先,单独的模型缺乏形式交互。每个模型通常包含很多层,参数很多,仅利用末端的匹配损失很难实现全交互。为了缓解这一问题,一些关于一般图像-文本预训练的研究使用交叉注意进行交互。但是,它们需要对所有可能的图像-文本对进行编码来计算相似度得分,导致推理阶段的时间复杂度为二次元。如何设计一个更适合TPR任务的网络,还需要深入思考。其次,标记视觉文本的部分对,如头部、上身和下身,是耗时的,而且由于文本描述的可变性,一些对可能会缺失。例如,一些文本包含发型和裤子的描述,但其他文本不包含此信息。一些研究者开始探索隐式局部对齐来挖掘部分匹配。为了保证可靠性,通常选择高置信度的局部匹配。但这些部分通常属于容易通过全局对齐挖掘的显著区域,即不带来额外的信息增益。根据作者的观察,**局部语义匹配不仅要看得更细,而且要看得更多。**一些微妙的视觉文本线索,例如发型和衣服上的标志,可能很容易被忽视,但可以作为全球匹配的补充。
为了解决上述问题,作者首先引入了一个隐式视觉文本(IVT)框架,该框架只使用一个网络就可以学习两种模态的表示(见上图(b))。这得益于Transformer可以对任何可以标记化的模态进行操作。为避免分离模型和交叉注意力模型的缺点,即分离模型缺乏模态交互,交叉注意模型在推理阶段速度较慢。IVT支持单独的特征提取,以确保检索速度,并共享有助于学习公共潜在空间映射的一些参数。为了探索细粒度的模式匹配,作者进一步提出了两种隐式语义对齐范式:多层次对齐(MLA)和双向掩码建模(BMM)。这两种范式不需要额外的手工标记,并且易于实现。具体地说,如上图©所示,MLA旨在通过使用句子、短语和单词级匹配来探索细粒度对齐。BMM与MAE和BEIT有相似的想法,它们都通过随机掩蔽学习更好的表示。不同的是,后两者针对的是单模态的自动编码式重建,而BMM不重建图像,而是侧重于学习跨模态匹配。通过屏蔽一定比例的视觉和文本token,BMM迫使模型挖掘更多有用的匹配线索。提出的两种范式不仅可以看到更好的语义对齐,而且可以看到更多的语义对齐。大量实验证明了TPR任务的有效性。
本文的贡献可以概括为三个方面:
(1)提出了从骨干网的角度解决模态对齐问题,并引入了隐式视觉文本(IVT)框架。这是第一个统一的基于文本的人员检索框架。
(2)提出了两种隐式语义对齐范式,即MLA和BMM,使模型能够挖掘更精细和更精确的语义对齐。
(3)对三个公共数据集进行了广泛的实验和分析。实验结果表明,本文的方法达到了最先进的性能。
3. 方法 3.1 Overview 为了解决基于文本的人物检索中的形态对齐问题,作者提出了一个隐式视觉-文本(IVT)框架,如上图所示。它由统一的视觉-文本网络和两种隐式语义对齐范式组成,即多层对齐(MLA)和双向掩码建模(BMM)。IVT的一个关键思想在于使用统一的网络来处理模态对齐。通过共享一些模块,如层归一化和多头注意,统一的网络有助于学习视觉和文本模式之间的共同空间映射。它还可以使用不同的模块学习特定于模态的线索。提出了两种隐式语义对齐范式,即MLA和BMM,以探讨细粒度的语义对齐。不同于以往的手工加工部件或从注意力中选择突出部件的方法,这两种范式不仅可以挖掘出更精细的语义对齐,而且可以挖掘出更多的语义对齐,这是作者提出的IVT的另一个关键思想。
3.2 Unified Visual-Textual Network Embedding 如上图所示,输入是图像-文本对,从视觉和文本两种方式提供一个人的外观特征。设图像-文本对记为 { x i , t i , y i } ∣ i = 1 N \left.\left\{x_{i}, t_{i}, y_{i}\right\}\right|_{i=1} ^{N} {xi,ti,yi}∣i=1N,其中 x i , t i , y i x_{i}, t_{i}, y_{i} xi,ti,yi分别表示图像,文本和身份标签。N为样本总数。对于输入图像 x i ∈ R H × W × C x_{i} \in \mathbb{R}^{H \times W \times C} xi∈RH×W×C,首先将其分解为 K = H ⋅ W / P 2 K=H \cdot W / P^{2} K=H⋅W/P2个patch,其中P表示patch的大小,然后将其线性投影为patch嵌入 { f k v } ∣ k = 1 K \left.
1、静态传值 注意:在template中不要加样式,因为不会起到任何作用他是不会执行的
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> <script src="https://cdn.jsdelivr.net/npm/vue@2.7.10/dist/vue.js"></script> <style> </style> </head> <body> <!-- 静态传值 --> <div id="root"> <!--使用组件 --> <com-son movies="狐妖小红娘" haha="我是父组件传过来的一句话"></com-son> </div> <!-- 子组件html部分 --> <template id="myson"> <div> <!-- 静态 --> <h1>我是子组件</h1> <h1>{{movies}}</h1> <h1>{{haha}}</h1> </div> </template> <script> // 创建子组件 let ComSon = { template: "#myson", props: ['movies', "haha"], } const vm = new Vue({ el: '#root', data() { return { } }, methods: { }, // 注册成一个局部组件 components: { ComSon } }); </script> </body> </html> 效果图:
“原创,并未实现数据驱动,所以此框架仅供参考,前提需要查看者熟悉unittest、selenium的使用方法,和良好的python代码编程技术”
实现材料:python、appium服务器、selenium、夜神模拟器、哔哩哔哩手机客户端
目标:通过自动化脚本实现哔哩哔哩app端搜索肯德基,进入视频,并判断是否进入成功
1.Appium配置 运行appium需要sdk和jdk的支持,安装方法网上有很多,在此不赘述
系统变量ANDROID_HOME:sdk所在的目录
系统变量JAVA_HOME:jdk所在目录
(路径仅供参考,需要联合实际目录)
点击startserver启动服务,默认开在本机的4723端口(127.0.0.1:4723)
可以通过访问http://127.0.0.1:4723/wd/hub验证服务是否开启成功 (此为成功开启)
为方便调试,可以把adb的所在目录添加进系统变量,方便命令提示符的调用
启动模拟器,输入adb命令查看是否连接成功
2.通过POM设计自动化测试脚本 所谓POM可称为页面对象模式(page object model),主旨是将动作、数据、程序相分离
动作和程序的关系相当于:动作是跑、跳、看、卧倒等基础动作,但你如果指挥一个人去卧室躺在床上,光靠单个动作可完成不了,须要由动作组成的程序来完成
所以需要计划创建三个python包裹,分别是页面基类包、动作程序包、测试用例包
首先创建页面基类包,并在其中创建py文件appbasic
这个包里面包括对象实例、基本动作
代码主体:
#系统包 import os #appium模块 from appium import webdriver from appium.webdriver.common.appiumby import By #selenium模块,用于元素判断和元素等待 from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.support.wait import WebDriverWait #时间包,用于等待 import time ''' 页面基类driver和一些常用的动作方法 ''' #定义一个driver类 class driver: # 初始化驱动 def __init__(self, device, msg): self.caps = msg #appium对象驱动是依靠webdriver.Remote()方法建造的,需要传入appium服务地址和连接信息 self.dv = webdriver.Remote(device, self.caps) # 等待某个元素 def element_wait(self, ele): #这里用try是防止人为误判,如果没有该元素会报错,所以保底让他停留1秒 try: ''' WebDriverWait方法需要传入驱动对象和最大等待时间, EC(这里是EC因为在导包的时候使用了EC作为别名,所以直接引用), EC.
众所周知,有机小分子拥有很多内禀属性,如logP, logD,溶解度,和pKa等。可以帮助我们在实验过程中快速评估和预测小分子行为。如化合物的亲脂性常常由logP和logD表示。所谓logP是对P(分配系数Partition coefficient)取10为底的对数形式,它定义了化合物在两种互不相容的溶剂中(正辛醇/水)的分配比率。logP所计算的分配比率并未考虑小分子的电离,只考虑了未电离形式的分配情况。而logD同时考虑了小分子电离形式以及未电离形式,因为随着溶液PH改变,小分子电离程度也随之改变,所以logD计算的数值随PH不同而发生变化。总之不论logD还是logP数值越小表示越亲水,膜透过性越差。
最近需要尝试对手头上两个小分子药物的细胞水平活性存在的差异进行解释,想着看能不能从膜透过性(logP)方面找找原因。原本我觉得这种预测工具网上随便搜一搜就能找到一大堆,可实际上却没几个。功夫不负有心人,最终找到了几个能用的,总结如下。可以收藏起来以备后用。
MarvinSketch 这款软件号称是可以替代Chemdraw的存在,试了一下呈现的图片还挺美观的,界面也很简洁。美中不足的是插件功能需要申请注册表,否则部分功能需要跳转网页端(网页端不能保证分子结构信息不被泄露) 。
软件下载地址:https://chemaxon.com/products/marvin/download
计算logP 计算logD 打开网址:https://disco.chemaxon.com/calculators/demo/plugins/logd/
注意:这个在线工具不承诺保护小分子结构信息不被泄露,如果是十分机密的小分子谨慎上传。
ALOGPS 一个网页端工具,省去了离线安装的麻烦。可以预测logP以及溶解度。
网址为:http://146.107.217.178/web/alogps/
Chem3D 说到预测logP,我第一个想到的是Chemdraw,看到网友支的招也是使用Chemdraw。可不知道是不是因为我版本的原因,愣是没找到这个功能。后来突然想到了它的好兄弟——Chem3D,结果一打开很快就找到了这个功能。
OSIRIS Property Explorer 这个离线工具需要提前安装好java环境。绘制好结构后,右侧自动显示该分子的各种属性预测值(包括logP)
后台回复“logP”可获得该软件。
事务相关概念 事务(Transaction) 对数据库一系列操作的集合。
事务的特性(ACID) 原子性(Atomicity):事务中的所有操作要么都执行完(然后全部提交),要么一个都不执行(全部回滚)。事务中的操作不可部分执行,更不可分割。
一致性(Consistency):事务运行结果不改变数据库中的数据一致性。例如“转账”事务,转账前后两个账户的余额总计是不变的。
隔离性(Isolation):事务并发运行过程中,一个事务不能被其他事务或操作干扰。同时执行的事务之间不能互相影响。
持久性(Durability):指事务运行完毕并成功提交后,其对数据库的所有操作结果应永久保留。以后运行的其他事务、操作甚至系统故障、意外情况等均不会影响该事务的运行结果,除非其他事务或操作更新相关数据。
调度(Schedule) 指事务的执行顺序。多个事务依次执行称为事务的串行调度(Serial Schedule);多个事务同时执行称为事务的并发调度(Concurrent Schedule)。多个事务并发调度的执行结果与它们串行调度的执行结果一致,则这个并发调度被称为“可串行化调度”(Serializable Schedule)。
冲突(Conflict) 如果事务调度中的两个操作交换执行顺序会改变它们所属的事务运行结果,则这两个操作冲突。
共有如下两种冲突情况:(1)同一事务的任何两个操作之间都是冲突的,无论这两个操作的数据对象是否相同,无论这两个操作是读还是写;(2)不同事务对同一数据对象,只要有任一操作涉及到写就一定冲突。
封锁 相关概念 谁来上锁? 事务。(或者说,系统根据事务的需求来上锁)
锁谁? 数据对象,可以是单行记录、数据页、索引、表甚至整个数据库。
为啥要锁? 避免其他事务访问数据对象产生数据不一致性错误。
锁了会怎样? 数据对象被上锁后其他事务或操作就无法对该对象读或写,直到锁被释放。
锁多久? 由事务决定。一般事务结束后会释放掉。
封锁粒度 封锁粒度即锁的对象或锁的作用范围。封锁粒度从高到低可分为数据库锁(Database-Level Lock)、表级锁(Table-Level Lock)、页级锁(Page Lock)、行级锁(Row Lock)以及索引(Index Key)等。
一般来说锁的粒度越高,事务执行效率更高,但并发性越低。假如某事务要处理数据库中的某些表,直接对整个数据库上锁无疑是最方便高效的方式,但这样其他事务对该数据库以及其中的所有表、行等均无法操作。如果该事务仅对它要操作的那些表逐一上锁,虽然效率较低,且需要同时管理多个锁,但其他事务可以并发处理同数据库中的其他表。
数据库软件一般支持不同粒度的锁并存。
锁的类型 共享锁(Shared Lock):简称S锁、读锁。事务A对某数据对象加了S锁,则事务A只能对该对象进行读操作。其他事务对于被上了S锁的对象只能上S、IS或U锁,而不能上X或IX锁。
排他锁(Exclusive Lock):简称X锁、写锁。在任一数据对象上,X锁均无法与其他任何锁共存。若某事务对数据对象加了X锁,则除该事务外任何事务无法对该数据对象进行读写操作。
提升锁(Update Lock):简称U锁。U锁是一种过渡锁。若事务A对某对象有修改意图,则先加上U锁。等到真正开始更新操作时再将U锁提升为X锁。被加了U锁的对象只能被别的事务加S或IS锁。
意向锁(Intent Lock):简称I锁。
首先我们考虑以下这种情况:事务A在表1中上了一个行锁,此时事务B要对整个表1进行修改,此时B就要看表1是否上了锁,或者遍历表中所有的行,当表1没上锁或者表1中所有行都没上锁时B才能给表1上锁然后操作。但是遍历表中所有行效率太低。因此,A在上行锁之前先申请给该行所属的表1的I锁,上了I锁后再上行锁。当B看到表1上有意向锁就知道表被占用了,就不用再通过遍历表这种低效的方式找锁了。
意向锁一般与S锁或X锁连用,即意向共享锁(Intent Shared Lock,IS锁)和意向排他锁(Intent Exclusive Lock,IX锁)。若某对象上存在IS锁或IX锁,说明该对象的下层某数据对象被加了S锁或X锁。同理,若某对象被加了S锁或X锁,则该对象的上级对象也要对应加上IS锁或IX锁。
下图展现了对于同一数据对象锁的共存情况。
多粒度树 如图,可以将不同粒度的上锁对象视为树型结构,从上到下分别是数据库、表、行。
上锁时可以仅针对某个节点单独加锁,同时这也意味着该节点下的所有子节点被加了相同的锁,且自该节点往上的所有祖节点被加上意向锁。
另外,为了减少冲突,加锁时应自上而下逐层加锁;解锁时应自下而上逐层解锁。
显示封锁与隐式封锁 显式封锁:直接加到数据对象上的封锁
隐式封锁:该数据对象没有独立加锁,但其某个祖节点加上了锁。
因此,在处理冲突时,系统不仅要检查显式封锁,还要检查隐式封锁。
封锁产生的问题 活锁(Live Lock):某事务一直在等待某个数据对象解锁而一直无法执行的情况称为活锁。例如事务A要对对象1上锁,但事务B提前上了锁,A只能等B解锁。但在B解锁后事务C、D、E…一直轮流使用对象1,不断上锁解锁,导致A一直无法给对象1上锁。
死锁(Dead Lock):系统中两个及以上的事务都在互相等待另一事务释放锁,导致这多个事务一直无法执行的状态。例如,事务A对对象1上锁,事务B对对象2上锁,但A也需要对2上锁,由于2被B占用,A只能等待,接着B要对对象1上锁,同样也要等待,就这样事务A、B互相等待对方解锁,导致两个事务一直无法执行。
并行操作产生的问题 脏读(Dirty Read) 假设事务A读取并更新了某对象,之后未提交其操作且回滚。在A更新后回滚前事务B读取到了同一对象。但由于A的更新被回滚,B读到的是一个无意义的值。
错误原因分析:
HTML页面是通过HTTPS加载的,但是其他资源文件(如图片,视频,样式表文件,脚本)是使用HTTP方式加载的。之所以称为混合内容,是因为在一个网页中同时使用了HTTP和HTTPS,而最初的请求方式为
HTTPS。
现代浏览器可能会阻止此类内容,或者显示关于此类内容的警告,提醒用户此页面包含不安全的内容。阻止混合内容的浏览器可能会首先尝试将该内容的连接从HTTP
“升级”到HTTPS。
第一步 在页面中加入(meta)头中添加upgrade-insecure-requests` <meta http-equiv="Content-Security-Policy" content="upgrade-insecure-requests"> 第二部 这将会把http请求转化为https请求。这样就不会再出现Mixed Content的错误了。
标题 java中double与Double的区别声明double变量的时候,加d与不加d有什么区别 java中float与double的区别java Double 详解BigDecimal、Double、String之间的互转java将double型数据转化为String类型java double转String时消除使用科学计数 将double类型数据转换成long类型数据将double类型数据转换成int类型数据java中double型数据如何设置舍入策略比较两个指定的 double值double值取反double值取绝对值double格式化千位分割符double任意格式化Double 类的常用常量 读者须知:这块建立在你的数值在double范围内的,不然造成精度丢失,合理选择接收数据类型,如BigDecimal类型解决问题,这里只做double相关介绍。特别需要注意的是两个浮点数的算术运算
会有精度损失的,总之一句话,浮点数你要想精度不丢失一律用BigDecimal,且构造选用String的构造 Java NumberFormat格式化float类型的bug
java中double与Double的区别 double是基本数据类型,而Double实际上是一个包装类,内置有很多方法。
如果数据只是一个普通的浮点类型,两种都可以使用。有一个不一样的是Double可以返回null值。
double money = 0.0d; double money1 = 0.0; double money2; //System.out.println(money2);//编译不通过,你必须的有默认值 double money3; money2 = money; //money2 = money3;//编译不通过,你必须的有默认值 Double mon; //System.out.println(mon);//编译不通过 Double mon1; //mon1 = mon;// 编译不通过 mon = null; mon1 = mon; mon = 0.0d; //Double a = 10;//编译不通过 Double a1 = 10d; Double a1 = 10.0; //规范声明如下:然后再去赋值 double truedouble = 0.
CSS单行和多行文本实现 1、CSS实现单行文本的溢出显示...2、实现多行文本溢出显示 1、CSS实现单行文本的溢出显示… 给出效果如下:
代码如下所示:
overflow: hidden; text-overflow:ellipsis; white-space: nowrap; /*还需要增加宽度实现兼容浏览器*/ 2、实现多行文本溢出显示 给出效果如下:
代码展示如下:
display: -webkit-box; -webkit-box-orient: vertical; -webkit-line-clamp: 3; overflow: hidden; 注意:使用范围,由于使用了webkit的CSS拓展属性,因此该方法属性可以适用于webkit的浏览器和移动端。
注意:
-webkit-line-clamp用来限制在一个块元素显示的文本的行数。 为了实现该效果,它需要组合其他的WebKit属性。display: -webkit-box; 必须结合的属性 ,将对象作为弹性伸缩盒子模型显示 。-webkit-box-orient 必须结合的属性 ,设置或检索伸缩盒对象的子元素的排列方式 。 给出的效果如下:
实现代码如下:
div { position: relative; line-height: 20px; max-height: 40px; overflow: hidden; } div:after { content: "..."; position: absolute; bottom: 0; right: 0; padding-left: 40px; background: -webkit-linear-gradient(left, transparent, #fff 55%); background: -o-linear-gradient(right, transparent, #fff 55%); background: -moz-linear-gradient(right, transparent, #fff 55%); background: linear-gradient(to right, transparent, #fff 55%); } 注意:
Git拉取数据报错:
kex_exchange_identification: Connection closed by remote host
Connection closed by 140.82.121.3 port 443
fatal: Could not read from remote repository.
Please make sure you have the correct access rights
and the repository exists.
排查问题步骤:
1、Ping 140.82.121.3
看一下这个ip能不能访问?
我想起我修改过host文件,看一下host文件有没有问题
140.82.121.3 github.com
140.82.121.3 ssh.github.com
通过debug查看为什么报错?
在Git Bash运行指令
ssh -v dreambirdXXX@github.com @符前面是github的用户名
$ ssh -v dreambird25@github.com
OpenSSH_9.0p1, OpenSSL 1.1.1o 3 May 2022
debug1: Reading configuration data /c/Users/Administrator/.ssh/config
debug1: /c/Users/Administrator/.ssh/config line 1: Applying options for github.
目录
一、Docker镜像操作
1、搜索镜像:docker search 关键字
2、拉取镜像:docker pull 镜像名称[:tag(标签)]
3、 查看所有镜像:docker images [选项]
4、根据镜像ID号获取镜像详细信息:docker inspect 镜像ID
5、为本地镜像添加新的标签:docker tag 名称 :[标签] 新名称:[新标签]
6、 删除镜像:docker rmi 仓库名称:标签 或者 docker rmi 镜像ID
7、存出镜像和存入镜像
7.1、存出镜像 docker save -o 存贮的文件名 存储的镜像
7.2、导入镜像 docker load < 存出的文件
8、上传镜像 docker push 仓库名称:标签
9、删除本地所有镜像 docker rmi `docker images -q`
二、容器操作
1、容器的创建与启动
1.1、容器的创建: docker creat [选项] 镜像 运行的程序
1.2、容器的启动:docker start 容器的ID
1.3、创建并启动容器:docker run [选项] 镜像名 /bin/bash
ps: docker run [参数] /bin/bash
ELK是Elasticsearch 、Logstash 、Kibana 的首字母缩写。
Elasticsearch是一个实时分布、开源的搜索引擎,它被用作全文检索、结构化搜索、分析以及这三个功能的组合。
Logstash是一个轻量级、开源的服务器数据处理管道,可以将收集的数据的进行动态转化,并将其发送到你规定的目标。通常Logstash是将数据加载到Elasticsearch的常用工具。
Kibana是一款免费开源应用程序。可以为 Elasticsearch 中索引的数据提供搜索和数据可视化功能。尽管人们通常将 Kibana 视作 Elastic Stack(之前称作 ELK Stack,分别表示 Elasticsearch、Logstash 和 Kibana)的制图工具,但也可将 Kibana 作为用户界面来监测和管理 Elastic Stack 集群并确保集群安全性,还可将其作为基于 Elastic Stack 所开发内置解决方案的汇集中心。Elasticsearch 社区于 2013 年开发出了 Kibana,现在 Kibana 已发展成为 Elastic Stack 的窗口,是用户和公司的一个门户。
一、ESP2插件下载
http://research.enjoymaps.ro/downloads/#
二、打开易康软件加载插件
三、使用ESP2插件
参数说明:
(1)Select map:本次计算的对象图层,默认为main.
(2)Use of Hierarchy(0=no;1=yes):是否使用多层次流程,不使用为0,使用为1,默认为1.
(3)Hierarchy:TopDown=0 or Bottom…=1:自上而下参数为0,自下而上参数为1,默认为1.
(4)Starting scale_Level 1:第1层分割起始尺度,默认为1.
(5)Step size_Level 1:第1层分割尺度的增长步长,默认为1.
(6)Starting scale_Level 2:第2层分割起始尺度,默认为1.
(7)Step size_Level 2:第2层分割尺度的增长步长,默认为10.
(8)Starting scale_Level 3:第3层分割起始尺度,默认为1.
(9)Step size_Level 3:第3层分割尺度的增长步长,默认为100.
(10)Shape(between0.1 and 0.9):形状因子,默认为0.1.
(11)Compactness(between0.1 and 0.9):紧致度因子,默认为0.5.
(12)Produce LV Graph(0=不生成;1=生成):生成LV图,默认为0.
(13)Number of loops:循环次数,默认为100次.
注:scale_Level、Shape、Compactness可以自己根据影像反复调节。Produce LV Graph一定要改成1,它会在影像同目录下生成一个文本,便于下一步确定最佳尺度。
四、查看最佳尺度图
1.打开软件
2.加载刚才生成的文本
3.计算
即可查看LV和RoF曲线图,确定影像最佳分割尺度。
目录
1.1 创建并使用空的数据库
2.1 增添数据记录
3.1 数据记录的删除
4.1 数据记录的修改 5.1 数据记录的查询
(关于mysql数据库、数据表的增、删、改、查链接:)点击本链接即可跳转https://mp.csdn.net/mp_blog/creation/editor/123970880
1.1 创建并使用空的数据库 create database topic(空的数据库名称);
use topic;
1)我们成功创建好数据库以后,将数据表的字段输入进去;
2)查看字段
2.1 增添数据记录 先用修改数据表下记录的方法增添自己需要的字段,按需要添加即可(此处不是增添记录)
2)添加记录
关键字: (单行)insert mydb(数据表名) values(); //单行用“;”结束
(多行)insert mydb(数据表名)values(),(),(); //多行用”,”隔开,“;”结束
values中的数据要与mydb表里的字段一一对应
注意:本篇文章 id 设置了 主键约束、自动增量,
username 设置了唯一约束、非空约束, reg_time 使用了系统时间的数据类型,为null时,默认使用系统时间
我们添加几条记录,并查看
(注意,因为我们设置的是自动增量,当id为null时,自动增量会默认加一,当id为数字时,大于自动增量会使用当前数字,等于0自动增量就会默认使用当前的自动增量加一,输入当前小于表内数据值会自动进行排序)
3.1 数据记录的删除 关键字:delete from mydb(数据表名)where id=1(条件);
此处时用 id 和 mobile 做条件删除记录的
4.1 数据记录的修改 关键字:update mydb(数据表名)set *(修改记录)where id=2(条件);
5.1 数据记录的查询 关键字:select * from mydb(数据表名);
通过上面的栗子我们以及看到了查询的使用和方法,其中 * 是 查询的条件,是可以改变的 它等价于 all ,查询表内的所有记录,下面我们在举些不同栗子的查询方法:使用id,username,level查找等
目录
前言 前面学习了数据单表的查询,接下来我要继续进行多表的查询了。
一、连接查询
1.等值与非等值连接查询
2.自身连接
3.外连接
4.多表连接
二.嵌套查询 1.带有in谓词的子查询
2.带有比较运算符的子查询
3.带有any 或 all 的谓词的子查询
4.带有exists谓词的子查询
三、集合查询
四.基于派生表的查询
总结
以上就是这次复习的了,继续加油。
前言 https://mp.csdn.net/mp_blog/creation/editor/124282946(单表查询链接)
前面学习了数据单表的查询,接下来我要继续进行多表的查询了。 包括:
1)连接查询
a.等值与非等值连接查询
b.自身连接
c.外连接
d.多表连接
2)嵌套查询
a.带有in谓词的子查询
b.带有比较运算符的子查询
c.带有any 或 all 的谓词的子查询
d.带有exists谓词的子查询
3)集合查询
4)基于派生表的查询
一、连接查询 1.等值与非等值连接查询 连接查询的where子句中用来连接两个表的条件称为连接条件或连接谓词,其一般格式为:
[<表名1.>] <列名1><比较运算符>[<表名2.>] <列名2>
举个栗子:select student.sname,sc.sno from student,sc where student.sno=sc.sno;
使用连接谓词的格式:
[<表名1.>] <列名1> between [<表名2.>] <列名2> and [<表名2.>]<列名3>
举个栗子:select student.sname,sc.sno from student,sc where student.sno=sc.sno and sc.cno="22" and sc.grade>90;
LeetCode 454 看到题目的第一想法
看到题目的第一想法就是先算前两个数,然后再求后两个数的相反数就是等于前两个数,是不是包含。一开始的想法是使用set来做,但是没有考虑到还要保存出现的次数。为什么?
看完题解后的想法
比如下面的例子,要考虑使用
nums1[1]+nums2[2]=5 nums1[2]+nums2[3]=5 nums1[3]+nums2[4]=5 那么这里5就出现了三次 如果后面 nums3[1]+nums4[2]=-5 那么这个组合可以和前面三个都能进行组合,都是符合要求的。 所以对于前面两个数,求和之后一定要记录次数 通过上面的例子那么就要使用map来保存。
看完题解后,就是使用map来保存
class Solution { public int fourSumCount(int[] nums1, int[] nums2, int[] nums3, int[] nums4) { int result=0; int count=0; Map<Integer,Integer> map1= new HashMap<>(); for(int i=0;i<nums1.length;i++){ for(int j=0;j<nums2.length;j++){ int temp = nums1[i]+nums2[j]; if(map1.containsKey(temp)){//计算前两个数的和然后看在map1里面嘛,在的话找到那个数,并给对应的次数+1 map1.put(temp,map1.get(temp)+1); }else{//不在的话,就给对应的次数赋1 map1.put(temp,1); } } } for(int i=0;i<nums3.length;i++){ for(int j=0;j<nums4.length;j++){ int target=(0-(nums3[i]+nums4[j])); if(map1.containsKey(target)){//是否在map中在的话,求对应的次数然后相加 result+=map1.get(target); } } } return result; } } 遇到的困难
今天更新数据库时出现了java.sql.DataTruncation Data truncation的异常,经过检查发现,某个字段数据库设置长度为3,实际值是5,导致异常。
经过搜索发现,除了长度以外,精度,范围,大小等都有可能出现该异常。
平台功能:在平台上录入相机后台设置的onvif信息,对外提供webapi接口,如获取播放地址,ptz控制,预置点控制等功能
开发环境:NetCore 6.0 + Sqlite
一、相机管理
1. 添加相机
2. 控制面板
2.1 获取播放地址,并播放rtsp流
2.2 PTZ控制
2.3 预置点管理(获取,前往,添加,删除)
rtsp转webrtc程序,用于html页面播放rtsp地址流
二、日志信息
三、 Swagger
四、程序结构
五、部分接口代码
using HappyOnvif.Utility; using HappyOnvif.Utilty; using HappyOnvif.Utilty.db; using HappyOnvif.Utilty.db.model; using Microsoft.AspNetCore.Http.Extensions; using Microsoft.AspNetCore.Mvc; using Newtonsoft.Json; using System; namespace HappyOnvif.Controllers { [Route("api/onvif/[action]")] [ApiController] public class OnvifController : ControllerBase { /// <summary> /// 设备初始化 /// </summary> /// <param name="model"></param> /// <returns></returns> [HttpPost] public ResponseExtend init([FromBody] Camera model) { string ip = model.
PowerShell脚本学习 前言1. PowerShell与cmd的区别2. PowerShell脚本2.1 xxx-Item2.1.1 创建目录2.1.2 创建文件2.1.3 删除文件2.1.4 删除目录 2.2 文件操作2.2.1 添加内容2.2.2 查看内容2.2.3 设置内容2.2.4 添加内容 2.3 PowerShell执行策略2.3.1 查看当前执行策略2.3.2 设置策略 2.4 变量操作2.4.1 定义变量- $x方式(推荐)/Set-Variable2.4.2 查看变量2.4.3 清空变量2.4.5 删除变量2.4.6 计算变量2.4.7 常量2.4.7 变量不同类型自带API的使用 PowerShell自带的变量3.1 系统变量3.1.1 表值类型3.1.2 数组对象 将文件复制到另一个文件夹下 待续 前言 运行Bamboo的时候,有script需要用到PowerShell,记录一下学习过程。
1. PowerShell与cmd的区别 Windows PowerShell® 是基于任务的命令行管理程序和脚本语言,专为进行系统管理而设计。 在 .NET Framework 的基础上构建的 Windows PowerShell 可帮助 IT 专业人士和高级用户控制和自动执行 Windows 操作系统以及在 Windows 上运行的应用程序的管理。
powershell和cmd区别:1、CMD写的BAT脚本我们看作是面向过程的,而PowerShell则是面向对象的,是一种站在使用者的角度进行脚本的编写;2、CMD只能执行基本的任务,PowerShell因为是基于【.NET】面向对象的。
2. PowerShell脚本 2.1 xxx-Item 2.1.1 创建目录 对大小写不敏感
New-Item test -ItemType Directory 2.1.2 创建文件 cd .
今天用python写代码的时候,发现代码没有高亮提示,不太友好
通过查询,可安装 Shader languages support for VS Code 插件,实现代码高亮显示
最终效果如下
看了下说明,C,C++应该也是通用的高亮显示
在 Linux 终端上执行命令的通常风格是简单地运行它并等待它正常退出,命令退出后,可以继续连续执行其他命令,这就是所谓的在前台运行命令。正如这个词所暗示的那样,您可以在终端上直观地看到命令的输出。
而有时候我们并不在意命令的输出,而是要求命令执行的同时,在终端执行其他任务,这时候就要用到后台运行命令,nohup和&就是两个比较常用的后台运行命令。
1.本节用到的其他知识1)重定向2)两种中断信号 2.& 命令3.nohup 命令4.结合使用后记——screen 1.本节用到的其他知识 1)重定向 通常情况下我们想要后台挂起的任务都会产生输出打印在当前屏幕上,这会影响后面再当前shell执行其他操作,我们可以使用< << 重定向命令将输出日志进行转移。
重定向的具体知识详见这篇文章:commond >/dev/null 2>&1 命令详解
2)两种中断信号 关闭屏幕,执行CTRL+C等原因造成ssh断开造成正在运行程序退出,常常会使我们的工作功亏一篑。
其背后的主要原因在于上述的相关操作,shell默认会发送中断信号给该终端session关联的进程,从而导致进程跟随终端退出,为了弄清这个问题我们首先要了解两种中断信号:
sigint:signal interrupt,ctrl+c会发送此信号,主动关闭程序sighup:signal hang up,关闭终端,网络断线,关闭屏幕会发送此挂断信号。 了解了程序退出的原因,接下来就是对这两种中断信号对应的解决办法。
用到的示例程序:test.sh
while true do echo "I'm still here!" sleep 1 done 2.& 命令 将 &放在执行命令的最后,此时执行ctrl+c关闭就不会关闭此进程,但是当屏幕关闭、断网仍然会造成进程退出。
也就是免疫sigint信号,无法免疫sighup信号。
关闭当前shell会话,重新打开一个会话,查看进程会发现test.sh已经不在:
3.nohup 命令 nohup(no hang up),即不挂断运行,用nohup运行命令可以使命令永久执行下去,和用户终端没有关系,断开SSH不影响运行,nohup捕获了SIGHUP,并做了忽略处理,因此当屏幕关闭,断网等造成ssh中断时进程不会退出。但是ctrl+c可以关闭关闭该进程。
也就是也就是免疫sighup信号,无法免疫sigint信号。
此时关闭当前shell会话,在其他会话查看进程:
此时进程依旧存在。
还有一点需要提及,使用nohup默认会将标准输出重定向到~/nohuo.out文件中,shell窗口不在打印输出信息,此时我们读取一下nohup.out文件:
nohup.out可以自定义其他文件
nohup commond >file 4.结合使用 sigintsighup&免疫不免疫nohup不免疫免疫 既然两种命令分别对两种信号免疫,那将他们一起使用会是什么效果呢?执行 Ctrl + C:
关闭当前会话,检测进程:刚刚显示的[1]403进程依旧存在,最强钉子户诞生!
此时想要关闭进程的话,只能使用kill命令杀死进程了:
后记——screen 使用nohup + & 的方法是比较常用的后台运行手段,但也有它的局限性,如果一个进程需要与用户进行交互,等待用户输入,那就无法使用nohup + & 的方法了。对于这个需求,我的解决办法是使用screen,篇幅问题,在这里只说一下简略使用方法,下一篇文章再进行具体介绍吧。
1.简介
帮助前端开发人员便捷调用后端api的,减少不必要的沟通联调,自动生成接口文档,并且也可以像postman一样发送https请求的一款自带UI的插件
2.注解
@Api():用在请求的类上,表示对类的说明,也代表了这个类是swagger2的资源
参数:
tags:说明该类的作用,参数是个数组,可以填多个。 value="该参数没什么意义,在UI界面上不显示,所以不用配置" description = "用户基本信息操作" @ApiOperation():用于方法,表示一个http请求访问该方法的操作
参数:
value="方法的用途和作用" notes="方法的注意事项和备注" tags:说明该方法的作用,参数是个数组,可以填多个。 格式:tags={"作用1","作用2"} (在这里建议不使用这个参数,会使界面看上去有点乱,前两个常用) @ApiModel():用于响应实体类上,用于说明实体作用
参数:
description="描述实体的作用" @ApiModelProperty:用在属性上,描述实体类的属性
参数:
value="用户名" 描述参数的意义 name="name" 参数的变量名 required=true 参数是否必选 @ApiImplicitParams:用在请求的方法上,包含多@ApiImplicitParam
@ApiImplicitParam:用于方法,表示单独的请求参数
参数:
name="参数ming" value="参数说明" dataType="数据类型" paramType="query" 表示参数放在哪里 · header 请求参数的获取:@RequestHeader · query 请求参数的获取:@RequestParam · path(用于restful接口) 请求参数的获取:@PathVariable · body(不常用) · form(不常用) defaultValue="参数的默认值" required="true" 表示参数是否必须传 @ApiParam():用于方法,参数,字段说明 表示对参数的要求和说明
参数:
name="参数名称" value="参数的简要说明" defaultValue="参数默认值" required="true" 表示属性是否必填,默认为false @ApiResponses:用于请求的方法上,根据响应码表示不同响应
一个@ApiResponses包含多个@ApiResponse
@ApiResponse:用在请求的方法上,表示不同的响应
参数:
code="404" 表示响应码(int型),可自定义 message="状态码对应的响应信息" @ApiIgnore():用于类或者方法上,不被显示在页面上
3.配置
面试官:项目开发中有遇到什么苦困难吗?你是如何解决这个困难的?
我:在这个项目的开发过程中,大大小小遇到过不少困难,从易到难大体可以分为三类:
语法、语义、编译等bug;独立开发新的功能(日志库、定时器、数据库连接池等);定位排查解决程序的重大bug; 像函数调用错误啊导致的错误排查,这些都不赘述了,只要是写代码的都会遇到。我说说我项目开发中让我印象比较深刻的几个问题吧,同时我也会阐述我针对项目出现的问题我是如何分析的,采用什么方式解决的,最后说说我的心得体会.
面试官:好的,请开始你的表演
Web服务器开发之踩过的坑(一) 在我对项目拓展了定时器和日志库模块之后,某一次我访问我的web服务器时,发现网页无法加载。在浏览器输入框内,输入服务器地址,网页会一直转圈圈但是就加载不出来。
正常的访问过程【图片】
服务器出现bug后的访问过程:【图片】
我对项目进行开发时,都是使用git进行版本管理和控制的。在服务器出现问题之后,我首先想到的就是回退一个版本。回退之后并没有解决问题,尝试了回退其他版本吗,也没有解决问题。那么说明,这个bug是很早之前就埋藏在程序中了,但是由于我专注于日志库模块、定时器模块的开发,并没有及时发现。
那么现在的问题就是:我并不知道bug在哪,也不知道bug在哪一个版本的程序中就产生了,所以,我需要做的就是:对整个服务器程序的运行过程进行一个梳理,试图分析出哪些环节的错误可能会导致现在这个局面
我的分析是从三个方面进行的:
检查服务器程序是否有问题(同最早的一版,能够正常访问的程序相比);客户端和服务器之间的网络连接是否正常;客户端浏览器是否有什么限制之类的其他因素。(比如涉及到前端的我不了解的知识); 定位问题 1. 服务器程序BUG检查 1.1 判断程序运行是否产生了错误? 网页无法加载,首先想到的就是程序运行出问题了。打开Linux的终端,重新运行服务器程序,浏览器访问服务器IP,观察服务器程序是否发生了崩溃。这里发现服务器程序没有崩溃
于是我就想到,程序虽然没有崩溃,但是页面没有加载出来,是否是因为程序在某个函数模块中陷入了死循环,这里我采用了两个办法:
gdb调试 有Windows平台下写程序遇到bug后我们都知道在IDE中打断点进行调试。在Linux环境下,由于没有图形化的界面,调试相对而言比较麻烦,需要借助GDB调试工具。
我尝试使用GDB对程序执行的函数进行打断点,然后挨个分析是不是哪个函数由问题。但是使用GDB调试有两个问题:第一是退出GDB调试后,下次再次调试需要重新打断点,程序的函数模块那么多,每一次这样的重复工作太折腾时间了;第二是程序遇到断点后被阻塞住了,无法通过GDB调试并发情况,这也是GDB调试的一个缺点。
日志输出 基于GDB调试的缺点,我紧接着采用了第二种方法:输出日志判断程序的运行逻辑和状态。我在每一个会被执行的程序的入口和出口都打上了日志。
在后台我打开日志文件,通过逐行的比对,就能得知函数运行的一个状态,是否发生了死循环等问题。
遗憾的是,通过日志输出,程序运行是一切正常的。
1.2 比较前后两个版本代码的差异? 整个服务器的代码行数差不多是3~4K行,分成了多个子目录,很多的文件。如果要检测比对服务器的代码,没有章法,一行一行的对比肯定是不行的。所以我首先对服务器的执行过程进行一次梳理:
epoll监听客户端的访问,并且有新连接时分配连接;读取客户端发送的请求报文;线程池的线程获取任务,进行业务逻辑的处理,也就是HTTP报文的解析、查找客户端请求的资源,装填响应报文;服务器发送响应报文。 把这四个部分所包含的程序代码,拿出来进行比对,试图找到错误产生的地方。但是由于两个版本的程序差异比较大,尝试了一两次之后,没有找到bug所在之处。
自然而然的,我认为bug不出现在程序上,而是出现在TCP连接或者客户端浏览器上。
2.TCP连接的检查 客户端和服务器之间的网络连接,在传输层采用的TCP协议,我是通过编写socket完成两者之间的连接的。一开始,我认为我的服务器跑在购买的云服务器上,正巧发生bug的那段时间,我给云服务器申请了域名,做了DNS解析,我分析是否是云服务器在网关、端口等方面对客户端的连接做了限制。
但是当我检查了云服务器的设置之后,发现并没有问题。我索性将程序打包发在Ubuntu的虚拟机上运行,但是发现问题依旧存在,那问题的根源应该不是我认为的那样。
为了验证客户端是否和服务器建立了正确的TCP连接,我之后使用wiresharks抓包软件对网络进行抓包分析。通过抓包结果发现TCP的连接是正确的,客户端也向服务器发送了数据。
并且,在Windows的主机上,我还使用了telnet工具进行网络连通性的测试。测试结果表明能够收到服务器发送的响应报文。所以,客户端和服务器之间的TCP通信是正常的。项目的BUG也不是在这里。
3. 浏览器前端的检查 排除了后端服务器代码的问题、底层通信的问题,最后一项就是前端网页的检查了。但我作为一名后端开发人员,对前端的了解甚少。我的项目中借鉴了一些别人的CSS组件和HTML网页。在网页加载不出来的时候,我从以下这两个方面进行问题的排查:
第一:首先是将我不熟悉的CSS组件换成一个简单的额HTML网页: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>首页</title> </head> <body> <h1>欢迎来到首页~~~</h1> </br> <img src="image.jpg" alt="ces" /> </body> </html> 第二:按F12,打开浏览器的开发者工具,分析问题是出在了哪里 访问一个包含文件、图片等资源的网页时,客户端会向服务器发送多条HTTP请求,每一个请求负责请求一张图片或者其他资源。如果有多张图片,客户端就会发送多条HTTP请求。
现代控制理论课程实验二:利用状态观测器实现状态反馈的系统设计 一、实验目的二、实验设备与软件三、实验模块四、实验原理4.1、若受控系统完全能控,则通过状态反馈可以任意配置极点。4.2、 时不变线性连续系统的状态反馈控制与观测器 五、实验内容5.1、系统模型建立5.2、建立状态观测器实现极点配置的仿真模型5.3、建立状态观测器模型 六、实验总结 一、实验目的 1、理解并掌握线性状态反馈控制的原理和方法;
2、理解并掌握线性观测器的设计方法;
3、练习控制性能比较与评估的方法。
二、实验设备与软件 1、MATLAB软件
2、Multisim软件
3、leaSaC实验箱
三、实验模块 函数信号发生器模块、有源模块A1-A7、阻容库模块和可变阻容库模块
四、实验原理 4.1、若受控系统完全能控,则通过状态反馈可以任意配置极点。 受控系统如下图所示
4.2、 时不变线性连续系统的状态反馈控制与观测器 对时不变线性连续系统
以系统状态为反馈变量产生控制
这种控制方式称为状态反馈控制,
如下图所示
考虑到控制系统的性能主要取决于系统极点在根平面上的分布,状态反馈控制通常通过极点配置法实施,将闭环系统极点配置在期望的位置上,从而使系统满足瞬态和稳态性能指标。
应用极点配置方法实现任意极点的配置,要求原系统可控。对于高阶系统(大于二阶),常将闭环系统设计成具有两个主导极点和非主导极点组成的系统,这样可以用二阶系统的分析方法确定参数。
但是,状态作为系统内部变量组,或由于不可能全部直接测量,或由于量测手段在经济性和适用性上的限制,使状态反馈的物理实现在有些情况下成为不可能或很困难的事。
为此引入状态观测器,以重构状态代替系统状态实现状态反馈,系统必须能观,才能设计观测器。
基于观测器的状态反馈控制系统由受控系统、状态反馈和观测器三部分构成。
如下图所示
观测器设计时需要满足观测的状态与原始状态在渐近意义下等价。
全维状态观测器的动态方程为
实际上,若系统输出矩阵C为满秩时,可以认为已代表了一部分状态,所以可以设计较简单的降维状态观测器,其最小维数为 (n代表状态个数,q代表输出个数)。
五、实验内容 5.1、系统模型建立 用Multisim建立系统模型
系统模型仿真波形如下所示
5.2、建立状态观测器实现极点配置的仿真模型 状态观测器实现极点配置的仿真模型如下所示
状态观测器实现极点配置的仿真模型仿真波形如下所示
5.3、建立状态观测器模型 建立状态观测器模型如下所示
建立状态观测器模型的仿真波形如下所示
六、实验总结 通过本次实验:利用状态观测器实现状态反馈的系统设计,总结如下几点所示
1、理解并掌握线性状态反馈控制的原理和方法;2、理解并掌握线性观测器的设计方法;3、练习控制性能比较与评估的方法。
酷狗音乐怎么转换mp3格式?使用酷狗音乐听歌的人比较多,通常我们都是在手机、电脑等有联网的情况听的,而一旦想下载下来在其他设备上听的话,就会碰到问题了。
在酷狗上下歌曲的时候,发现下的是kgm、kgma格式,查了一下才知道这是酷狗音乐的一种专用加密格式,只能在酷狗里面听,这就很扯淡了,即使我已经开通了vip会员,还要来这种限制就有点不地道了,没办法只能想办法把酷狗kgm、kgma格式转换成flac无损、mp3格式的。
这个方法同样适用于网易云音乐(ncm)、QQ音乐(qmc, mflac, mgg)、酷狗音乐(kgm)、虾米音乐(xm)、酷我音乐(.kwm)转换成mp3、flac无损音质的,而且都是在线操作的,无需下软件的。
1.打开网址https://demo.unlock-music.dev/
2.将下载下来的加密音乐文件上传即可成功解密并下载。
3.详情可以自行查看项目域名:https://unlock-music.dev/
GitHub地址:https://github.com/unlock-music/unlock-music/
其他在线解密转换网站:
转换云(ncm等格式转MP3):https://www.zhuanhuanyun.cn/
音频编辑工具(大部分格式转换以及截取,变调):https://audio.worthsee.com/convert
硕鼠音频下载(支持100多个主流平台的音视频解析):https://www.flvcd.com/
WORTHSEE网(ncm等格式转MP3):https://ncm.worthsee.com/
OpenYYY 开源云音乐(多种云音乐格式转MP3):https://openyyy.com/
迅捷音频:https://www.xunjieshipin.com/audio-converter?zhljj220817-306630653
人生与命运无关,但与自己的选择有关。
本文转载自天乐博客:https://blog.361s.cn/128.html
Introduction 预训练的语言模型,在改进自然语言处理任务方面非常有效。包括句子级别的任务(自然语言推理和释义)也包括分词级别的任务(NER和问答)。
将预训练的语言表示应用于下游任务有两种现有策略:基于特征(feature-based)与微调(fine-tuning)。(这两种方法在预训练期间共享相同的目标函数,它们使用单向语言模型来学习通用语言表示。)
基于特征:例如 ELMo使用特定于任务的架构,其中包括预训练的表示作为附加特征。
微调:引入了最少的任务特定参数,并通过简单地微调所有预训练参数来对下游任务进行训练。
但是,当前的技术限制了预训练表示的能力,特别是对于微调方法。主要限制是标准语言模型是单向的,这限制了可在预训练期间使用的架构的选择。这样的限制对于句子级任务来说是次优的,并且在将基于微调的方法应用于令牌级任务(例如问答)时可能非常有害。(提出问题)
BERT 所有总结的bert的知识点都在这:http://t.csdn.cn/YsF9N
Experiment 我们展示了 11 个 NLP 任务的 BERT 微调结果。(属于4类)
第一类任务运行结果:
Ablation Studies(消融实验) 我们首先考察 NSP 任务带来的影响。在表 5 中,我们表明移除 NSP 会显着损害 QNLI、MNLI 和 SQuAD 1.1 的性能。接下来,我们通过比较“No NSP”与“LTR & No NSP”来评估训练双向表示的影响。 LTR 模型在所有任务上的表现都比 MLM 模型差,在 MRPC 和 SQuAD 上的下降幅度很大。
在本节中,我们探讨了模型大小对微调任务准确性的影响。我们训练了许多具有不同层数、隐藏单元和注意力头的 BERT 模型,同时使用与前面描述的相同的超参数和训练过程。选定 GLUE 任务的结果如表 6 所示。可以看到,更大的模型会导致所有四个数据集的准确度得到严格的提高。
最近由于使用语言模型进行迁移学习的经验改进表明,丰富的、无监督的预训练是许多语言理解系统不可或缺的一部分。特别是,这些结果使即使是低资源任务也能从深度单向架构中受益。我们的主要贡献是将这些发现进一步推广到深度双向架构,允许相同的预训练模型成功处理广泛的 NLP 任务。
我们知道docker可将应用程序和基础设施层隔离,可更快地打包、测试以及部署应用程序。本文主要介绍SpringBoot项目如何构建docker镜像以及推送到私服或者docker hub服务器上。
本文介绍的方式是使用docker-maven-plugin的方式构建SpringBoot的docker镜像以及推送到私服或docker hub服务器上。
Docker环境配置 本地环境配置 docker-maven-plugin 插件默认连接本地 Docker 地址为:localhost:2375,如果我们本地开发环境有docker环境并准备使用本地开发环境的docker,只需要先设置下本地开发环境的环境变量。
DOCKER_HOST=tcp://<host>:2375 服务器环境配置 如果使用CentOS服务器上的docker环境 (CentOS上安装docker环境),则需要在服务器上修改 docker 配置,开启允许远程访问 docker 的功能,开启方式很简单,修改 /usr/lib/systemd/system/docker.service 文件,ExecStart中加入如下内容:
-H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock 修改好配置后,使用如下命令重启docker生效:
systemctl daemon-reload systemctl restart docker IDEA测试docker连接 IDEA 中我们可以测试服务器上的docker环境是否连接成功,打开 File->Settings->Build,Execution,Deployment->Docker ,然后配置一下 Docker 的远程连接地址:
配置一下 Docker 的地址,配置完成后,提示 Connection successful 信息,表示 Docker 已经连接上了。
SpringBoot项目引入docker-maven-plugin插件 pom.xml配置 项目中引入docker-maven-plugin插件,在pom.xml引入插件并做相应的配置:
<project> <!-- other setting--> <build> <plugins> <plugin> <!-- https://mvnrepository.com/artifact/com.spotify/docker-maven-plugin --> <groupId>com.spotify</groupId> <artifactId>docker-maven-plugin</artifactId> <version>1.2.2</version> <executions> <!-- 当mvn执行install操作的时候,执行docker的build和push --> <execution> <id>buildAndPush</id> <phase>install</phase> <goals> <goal>build</goal> <goal>push</goal> </goals> </execution> </executions> <configuration> <!
目录
一、前提
二、文件目录含义
三、运行tomcat
四、运行成功效果
五、使用tomcat打开本地端口为8080的网页
六、用tomcat打开自己的.html文件
七、用tomcat打开.html文件和鼠标右键打开.html文件的区别
八、tomcat点击运行,cmd窗口出现后闪退解决
九、附:修改端口号的方法
一、前提 我的idea的版本是:IntelliJ IDEA 2021.1.2 x64
我在apache官网下载的apache-tomcat版本是:apache-tomcat-9.0.68
apache-tomcat下载官网:Apache Tomcat® - Apache Tomcat 8 Software Downloads
选择版本,下载压缩包,到本地解压。【注意路径不要有中文和空格】
我的存放路径为:D:\programfiles\apache-tomcat-9.0.68
二、文件目录含义 打开文件,如下:
文件目录含义如下:
三、运行tomcat 方式一:点击bin目录下的startup.bat即可
方式二:在安装路径下,打开cmd,输入catalina run回车
四、运行成功效果 我的中文是乱码,但影响不大。
五、使用tomcat打开本地端口为8080的网页 六、用tomcat打开自己的.html文件 在apache-tomcat安装目录下的webapps下,新建文件夹,命名为javascript,里面粘贴里我的1.html文件
我的1.html文件内容如下:
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title></title> <script> //全选 function checkAll() { // document.getElementsByName()根据指定的name属性查询返回多个标签对象的集合 var hobby = document.getElementsByName("hobby"); // 将所有的hobby的chekbox的checked属性修改为true 被选中状态 for (var i = 0; i < hobby.length; i++) { hobby[i].
Spring BeanUtils 实现了Bean实例之间的属性拷贝,但是实现的浅拷贝,对于不同类型属性转换的时候会有些问题。
问题 测试代码 测试Bean A
package com.bean; import lombok.Data; import lombok.experimental.Accessors; import java.util.List; @Data @Accessors(chain = true) public class A { private String name; private InnerClass innerClass; private List<InnerClass> inners; @Data @Accessors(chain = true) static class InnerClass { private String name; } } 测试Bean B
package com.bean; import lombok.Data; import lombok.experimental.Accessors; import java.util.List; @Data @Accessors(chain = true) public class B { private String name; private InnerClass innerClass; private List<InnerClass> inners; @Data @Accessors(chain = true) static class InnerClass { private String name; } } 测试代码
IOU IOU就是两个图像的交并比,这是一个图像检测中很重要的概念,想要构建YOLO系列的目标检测对应函数,就必须要先写一个计算交并比的程序,什么是交并比,就是两个图像交集的面积比上并集的面积,如果用下面的图来举例子的话。
I O U = S 3 S 1 + S 2 − S 3 IOU = \frac{S_3}{S_1+S_2-S_3} IOU=S1+S2−S3S3
由于目标检测的过程中我们大部分用的都是矩形框,根据算法我们都是知道两个矩形的左上角点的坐标和矩形的高和宽
根据计算IOU的通用办法我们只需要再算出两个矩形的右下角坐标,用这四个坐标就可以确定并算出交集部分的左上角坐标和右下角坐标,这样就可以得到交集区域的宽和高,进一步就能算出交集区域的面积,算出了交集区域的面积,就可以算出交并比。
这里会有一个很明显的问题就是随着求交并比的两个大的矩形的位置的不同,交集矩形的坐标的表示方式也会有不同,接下来我们遍历一下所有的情况,最后找出一个规律。下面这个图画的累死我了,公式还各种变形,就这样吧哪天再改。
好的接下来看一下规律,交集区域的左上角坐标都是由两个相交矩形的左上角坐标决定的,同理右下角的坐标都是由相交矩形的右下角坐标决定的,这里可以停下来仔细看一下上面的图思考一下,验证一下下面的规律,这样有助于代码的理解。
左上角点的横坐标 x _ b o x x\_box x_box是 x x x与 x 1 x_1 x1的最小值左上角点的纵坐标 y _ b o x y\_box y_box是 y y y与 y 1 y_1 y1的最小值右下角点的横坐标 x _ w _ b o x x\_w\_box x_w_box是 x _ w x\_w x_w与 x 1 _ w 1 x_1\_w_1 x1_w1的最大值右下角点的纵坐标 y _ h _ b o x y\_h\_box y_h_box是 y _ h y\_h y_h与 y 1 _ h 1 y_1\_h_1 y1_h1的最大值 在知道了左上角标和右下角标之后就可以算出交集的宽和高,然后就可以算出交集的面积,则就能求出总体的IOU
目录
一、java+MySQL,java对数据库表进行增删改查任务前提:
要求一:创建lib文件夹
要求二:添加druid.properties
要求三:创建四个子文件夹
二、具体要求如下:
1、编写DbUtils类,连接数据库;
2、写一个实体类Product.java
3、写一个产品表数据访问类ProductDao.java
4、写一个测试类TestProDao.java
三、数据库表配置和java完整代码如下:
1、在MySQL数据库中,我创建的数据库,命名为mydata1
2、DbUtils.java连接数据库的类:
3、实体类Product.java
4、ProductDao.java包含增删改查的方法
5、TestProDao.java调用方法,对数据库表进行增删改查
四、运行结果
1、添加产品:
2、修改产品:
3、根据pro_Id查询一个产品:
4、查询所有产品,返回一个list列表:
5、删除产品
一、java+MySQL,java对数据库表进行增删改查任务前提: 要求一:创建lib文件夹 已在项目路径下,创建了一个lib文件夹,粘贴两个jar包:duruid-1.0.9.jar和mysql-connector-java-5.1.37-bin.jar;
并分别鼠标右键,选中add as library,添加到环境配置中;
要求二:添加druid.properties 在本项目的src目录下,粘贴druid.properties;
要求三:创建四个子文件夹 在本项目的src目录下创建四个文件夹,分别命名为com.qingruan.dao、com.qingruan.entity、com.qingruan.test、com.qingruan.util(com后面的是公司名,可替换):
文件夹下分别放相应功能的java文件,这样分工明确,不会混乱。
com.qingruan.dao:创建包含增删改查的方法的类,命名为:ProductDao.java
com.qingruan.entity:创建实体类,命名为:Product.java
com.qingruan.test:创建测试类,命名为:TestProDao.java
com.qingruan.util:创建java连接数据库的类,命名为:DbUtils.java
分割线————————————————————————————
二、具体要求如下: 1、编写DbUtils类,连接数据库; java连接MySQL的具体讲解在上一篇。
2、写一个实体类Product.java 同时在MySQL创建产品表product,注意数据类型和属性要一致;在实体类应有三个私有属性:
产品序号pro_Id、产品名称pro_name、产品价格pro_price,其中pro_Id要设置为主键,并自增;
最后创建get/set方法;
3、写一个产品表数据访问类ProductDao.java 包含增删改查的方法:
(在这个类中先抛出异常,在测试类调用方法时,再进行try..catch...)
提示如下:
增加产品的方法:public int addProd(Product p)throws Exception;
删除产品的方法:public int delProd(int pro_Id) throws Exception;
修改产品的方法:public int updateProd(Product p)throws Exception;
查询所有产品的方法,并返回产品集合:public List selectAll() throws Exception;
全套资源下载地址:https://download.csdn.net/download/sheziqiong/86770095
全套资源下载地址:https://download.csdn.net/download/sheziqiong/86770095
目录
数据可视化 Final Project 1
项目介绍 1
1.1. 人脸互换(face swap) 2
1.2 人脸融合(face morph) 2
1.3 本征脸(eigen face) 2算法结构与处理过程 2
2.1 人脸变换 2
2.1.1 人脸关键点检测 2
2.1.2 计算凸包 3
2.1.3 德劳内(Delaunay)三角划分 3
2.1.4 进行仿射变换 3
2.1.5 无缝融合 3
2.2 人脸融合 3
2.2.1 人脸关键点检测 3
2.2.2 定义融合度 4
2.2.3 采样点加权 4
2.2.4 德劳内三角划分 4
2.2.5 图像融合 4
2.3 本征脸 5
2.3.1 数据预处理 5
2.3.2 主成分分析 5
2.3.3 获得本征脸 5代码结构 5
先贴上Protobuf的资料:
Protobuf官方资料:Developer Guide
Protobuf gitbub地址:protocolbuffers/protobuf
ProtoBuf3官方文档:
Language Guide (proto3) | Protocol Buffers | Google Developers
ProtoBuf3 Go语言教程:
Protocol Buffer Basics: Go | Protocol Buffers | Google Developers
注意:Proto2和Proto3其语法定义会有很大的差别,初学者建议学习ProtoBuf3,
本文将详细讲解如下问题:
ProtoBuf协议是什么协议,优缺点是啥?为什么它比json、XML效率都要高?
在go语言中怎么实现ProtobufBuf协议 ?
如何生成和定义proto文件?
怎么使用ProtoBuf编译器编译proto文件,自动生成go代码?
怎么使用Go第三方库实现ProtoBuf编程?
ProtoBuf协议 ProtoBuf是通过对传输字段的名称、顺序进行预定义,从而在传输结构中只需要顺序的记录每个字段的类型标签和二进制值,所以性能比JSON、XML强很多。
优点: 性能好、效率高 相对于json和xml解析方式,快速高效非常多,因为他会编译成一种二进制文件
代码生成机制 能通过Protobuf协议定义一种文件,一种机制,自动生成go文件,生成结构体
支持向前兼容和向后兼容 支持多种编程语言 缺点: 可读性较差 因为Protobuf采用的是二进制格式进行编译。
缺乏自描述 开发者面对二进制格式的Protobuf,没有办法知道所对应的真实的数据结构,因此在使用Protobuf协议传输时,必须配备对应的proto配置文件。
ProtoBuf实现步骤 1、安装protobuf编译器。 可以在如下地址: https://github.com/protocolbuffers/protobuf/releases 选择适合自己系统的Proto编译器程序进行下载并解压,
下载解压成功后,需要将bin文件夹路径添加到环境变量中,如下图所示。
添加环境变量:
查看版本:protoc --version
protoc --version 出现上述说明编译器安装好了
2.下载go语言中需要使用到的protobuf源码库(相当于protobuf解释器) go get下载命令:go get github.com/golang/protobuf/protoc-gen-go (二选一)
git 下载命令:git clone https://github.
1、安装淘宝镜像:npm install -g cnpm --registry=https://registry.npm.taobao.org
2、cnpm -v输入验证
3、全局安装webpack:cnpm install webpack -g
4、 安装脚手架:npm install -g vue-cli,验证vue -V (V要大写)
5、 这里的路径要和安装盘符一致。
6、
等下面的进度条走完之后,一个基本的项目就搭建好了。
7、终端输入vue add router安装路由,之后打n即可
8、输入vue add vuex安装vuex,之后打y,方法同上。
9、最后输入cnpm install axios --save
这样,项目就搭建好啦
用过多年的tomcat,从来都没有真正的了解过,重新学习一下(一) 什么是tomcatserver.xml配置项contextHostEngineWrapperConnectorserverservice tomcat启动时,这些配置是什么时候加载的 人有时候就是这样,总会在某个时间点自信心爆棚想着要去追一个梦~ 而现在我也要追一个梦,我要当大牛!当然了,一口吃不成大胖子,所以决定一步一个脚印。
先进一步重新学习下tomcat吧。
什么是tomcat tomcat是一个java语言开发的web应用服务器,或者说是一个servlet(servlet写在后面)容器,适用于中小型系统和并发访问用户不是很多的场合。
在tomcat中平时工作用到最多得到文件应该就是server.xml了,就先重新了解下server配置文件吧
server.xml配置项 用一张图来表示这些配置项的关系
context 一个 context 通常代表一个web应用,一个web应用中可以包含多个servlet,context中可以有多个servlet
Host 表示一个虚拟主机,一个虚拟主机中可以包含多个web应用
Engine Engine容器可以包含若干Host容器,Engine可通过defaultHost配置默认访问的虚拟主机
Wrapper servlet默认是单例的。在将servlet设为多例的情况下,所有不同的servlet都放在context容器中会很混乱,wrapper就是用来解决这一问题
Wrapper容器会包含相同servlet的集合,在这种情况下Context中存放的不再是servlet集合,而是Wrapper集合
Connector 处理与客户端的通信,用于监听端口,接受请求并转交给Engine处理,同时将来自Engine的答复返回给客户端
server 表示tomcat服务器
service 表示一个服务器中的一个服务
tomcat启动时,这些配置是什么时候加载的 记得比较笼统,没有很深入
补充:server还有一个配置项为Valve,可以理解为阀门。可以配置在Engine、Wrapper、Host、Context中
下一篇:tomcat http通信过程
本文内容 解决Unity WebGL游戏保存数据到Application.persistentDataPath不生效的问题 问题简述 WebGL游戏保存到Application.persistentDataPath有时不生效。
问题成因 Unity的Application.persistentDataPath在WebGL游戏中会映射至/idbfs/[文件路径的md5哈希值](URL查询字符串前的字符计算md5哈希)
/idbfs是IndexedDB所处文件夹,用于客户端持久化存储文件。但是Unity对IndexedDB的写入并不是立即的,而是不可预知的(详见相关官方文档)。因此如果用户在保存后立刻刷新页面,这次保存往往不会持久化写入到硬盘中。
解决办法 我们需要在保存后显式写入数据到/idbfs中,这需要借助js脚本。
庆幸的是我们可以在Unity编辑器中嵌入js脚本!
注意:js脚本仅在WebGL构建中生效
首先在工程的/Assets/Plugins/目录下创建一个后缀为.jslib的文件。打开文件,加入如下JavaScript代码: mergeInto(LibraryManager.library, { //刷新数据到IndexedDB SyncDB: function () { FS.syncfs(false, function (err) { if (err) console.log("syncfs error: " + err); }); } }); 在需要使用js脚本的C#代码块中(此处则是负责保存的C#类),加入外部函数声明: #if UNITY_WEBGL && !UNITY_EDITOR [DllImport("__Internal")] private static extern void SyncDB(); #endif 在负责保存的C#代码后面加入外部函数调用: #if UNITY_WEBGL && !UNITY_EDITOR //刷新数据到IndexedDB SyncDB(); #endif 这样你的存档就会及时写入到IndexedDB中。
参考 File saved to IndexedDB lost unless we change scenes
1.下载浏览器 点击打开Google Chrome 网络浏览器,直接点击下载按钮
点击后,选择第一个即可
2.安装google 打开下载的目录地址,打开终端
执行命令
sudo dpkg -i google-chrome-stable_current_amd64.deb 3.运行浏览器 安装完成后,直接输入
google-chrome 即可运行
篇幅有限 完整内容及源码关注公众号:ReverseCode,发送 冲
目标 http://www.gsxt.gov.cn/corp-query-entprise-info-xxgg-100000.html
分析 POST http://www.gsxt.gov.cn/affiche-query-area-info-paperall.html?noticeType=21&areaid=100000¬iceTitle=®Org=110000
参数: noticeType=21 通知类型, 失信企业固定21areaid=100000 无论在哪个区域, 固定是100000noticeTitle= 通知标题, 可以为空regOrg= 通知的区域id, 可以从省份标签上获取 请求体数据: draw: 1 点击分页按钮的次数, 可以省略start: 0 起始索引号length: 10 长度, 固定是10, 设置多了也无效 直接访问该接口时,状态521,返回如下js混淆加密代码。
尝试给请求头中加上cookie__jsluid_h=f6db0fc02adff8425bebcd8ed1b5fffc; SECTOKEN=7445298838033400749; __jsl_clearance=1619443187.64|0|nGqWRKwajO%2BeHI6CP7Mt50EbdcU%3D;,正常返回如下结果。
__jsluid_h 打开fiddler,刷新页面抓包http://www.gsxt.gov.cn/corp-query-entprise-info-xxgg-100000.html,一共访问了三次该页面,前两次521第三次正场返回请求页面。
第一次请求时服务端向服务器塞入第一个__jsluid_h关键cookie
Set-Cookie: __jsluid_h=01737b0139a221e260d1061c68b4232f; max-age=31536000; path=/; HttpOnly 并向浏览器返回一段混淆过的js,内容如下,主要功能应该是设置cookie。
<script>document.cookie=('_')+('_')+('j')+('s')+('l')+('_')+('c')+('l')+('e')+('a')+('r')+('a')+('n')+('c')+('e')+('=')+((+true)+'')+((1+[2])/[2]+'')+(-~false+'')+(3+6+'')+(2+2+'')+(-~[2]+'')+(~~false+'')+((2)*[4]+'')+((1+[0])/[2]+'')+(9-1*2+'')+('.')+((2)*[2]+'')+(6+'')+(1+6+'')+('|')+('-')+(-~0+'')+('|')+('w')+('Y')+('p')+('A')+('F')+('R')+('%')+(1+1+'')+('B')+(-~(4)+'')+('X')+('x')+('m')+('W')+('Y')+((1<<2)+'')+('j')+('P')+('a')+('Q')+([3]*(3)+'')+('t')+('Q')+(1+7+'')+('T')+('P')+('Z')+('i')+('E')+('%')+(3+'')+('D')+(';')+('m')+('a')+('x')+('-')+('a')+('g')+('e')+('=')+(3+'')+(3+3+'')+(~~''+'')+(~~false+'')+(';')+('p')+('a')+('t')+('h')+('=')+('/');location.href=location.pathname+location.search</script> 我们将这段js放入浏览器中执行,如我们所料,正是返回第二个__jsl_clearance关键性cookie。
__jsl_clearance 第二次请求http://www.gsxt.gov.cn/corp-query-entprise-info-xxgg-100000.html时,浏览器发送了__jsl_clearance和__jsluid_h两个关键cookie,服务端接收后并返回了一段混淆后的js,这次没有向浏览器塞入cookie。
Cookie: __jsluid_h=01737b0139a221e260d1061c68b4232f; __jsl_clearance=1619430857.467|-1|wYpAFR%2B5XxmWY4jPaQ9tQ8TPZiE%3D SECTOKEN 第三次请求http://www.gsxt.gov.cn/corp-query-entprise-info-xxgg-100000.html时,浏览器携带了两个关键性Cookie,不过这次__jsl_clearance和之前的值发生变化,怀疑是第二次请求返回的js做了手脚。
Cookie: __jsluid_h=01737b0139a221e260d1061c68b4232f; __jsl_clearance=1619430857.529|0|WGn9gKxiPtYUHAGBZ1a%2B%2F3o9sJE%3D 这次请求不仅正常的返回了页面内容,而且还往请求头中塞入了第三个SECTOKEN关键性Cookie。
Set-Cookie: SECTOKEN=7448433543385710812; Expires=Sat, 14-May-2089 13:03:34 GMT; Path=/; HttpOnly 请求数据 在上面的三个cookie加持下,终于成功的返回了我们想要的数据,接下来就是分析这三个cookie在代码中如何拿到。
爬虫实现 通过requests的session对象,自动合并cookie信息,并设置请求头。
headers = { 'User-Agent': 'Mozilla/5.
环境安装 Python 3(略)pyinstaller pip install pyinstaller 打包exe程序 命令:
pyinstaller -F -w *.py 说明:
*是.py的全部路径此命令在命令行窗口执行-F是打包单一文件,-w是运行时不弹出黑窗口打包成功,会显示exe程序的位置,找到运行
给exe程序添加图标 命令:
pyinstaller -F -w -i *.ico *.py 说明:
需要准备一张.ico后缀名的图片(可自行网上下载)需要注意的是,需要移动exe程序的位置,才可以显示图片 常用pyinstaller 命令 -i 给应用程序添加图标-F 指定打包后只生成一个exe格式的文件-D –onedir 创建一个目录,包含exe文件,但会依赖很多文件(默认选项)-c –console, –nowindowed 使用控制台,无界面(默认)-w –windowed, –noconsole 使用窗口,无控制台-p 添加搜索路径 文章转载:https://zhuanlan.zhihu.com/p/87211459
在使用xhell连接服务器,在配置了ip、端口、用户名和密码后,点击连接后,弹出窗口提示“没有找到匹配的outgoing encryption算法”错误,原因分析如下
原因: 由于xshell软件版太老,或者加密算法未勾选导致,请检查本地软件所有加密算法均已勾选。
1、选择属性 2、选择协议后的设置
3、高级选项中的<Cipher List> 后的编辑
4、把所有的加密算法全部勾选
5、确定,再次连接即可
把没勾选上的加密算法全部勾选上。 通过如上添加了加密算法后就能正常连接啦,大家快去试试把!
机器学习经典赛题:工业蒸汽量预测(5) 机器学习经典赛题:工业蒸汽量预测(5):模型验证(赛题实战)5.3 模型验证与调参实战5.3.1 模型过拟合与欠拟合5.3.2 模型正则化5.3.3 模型交叉验证5.3.4 模型超参空间及调参5.3.5 学习曲线和验证曲线 参考资料 机器学习经典赛题:工业蒸汽量预测(5):模型验证(赛题实战) 5.3 模型验证与调参实战 5.3.1 模型过拟合与欠拟合 基础代码
导入工具包,用于模型验证和数据处理。 import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from scipy import stats import warnings warnings.filterwarnings("ignore") from sklearn.linear_model import LinearRegression #从sklearn引入线性模型 from sklearn.neighbors import KNeighborsRegressor #k近邻回归模型 from sklearn.tree import DecisionTreeRegressor #决策树回归模型 from sklearn.ensemble import RandomForestRegressor #随机森林回归模型 from sklearn.svm import SVR #支持向量机 from lightgbm import LGBMRegressor #LightGBM回归模型 from sklearn.
项目运行
环境配置:
Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。
项目技术:
SSM + mybatis + Maven + Vue 等等组成,B/S模式 + Maven管理等等。
环境需要
1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。
2.IDE环境:IDEA,Eclipse,Myeclipse都可以。推荐IDEA;
3.tomcat环境:Tomcat 7.x,8.x,9.x版本均可
4.硬件环境:windows 7/8/10 1G内存以上;或者 Mac OS;
5.是否Maven项目: 否;查看源码目录中是否包含pom.xml;若包含,则为maven项目,否则为非maven项目 6.数据库:MySql 5.7/8.0等版本均可;
毕设帮助,指导,本源码分享,调试部署(见文末)
4.1功能结构 为了更好的去理清本系统整体思路,对该系统以结构图的形式表达出来,设计实现该高校学生网上请假系统的功能结构图如下所示:
图4-1 系统总体结构图
4.2 数据库设计 4.2.1 数据库E/R图 ER图是由实体及其关系构成的图,通过E/R图可以清楚地描述系统涉及到的实体之间的相互关系。在系统中对一些主要的几个关键实体如下图:
(1)辅导员信息E/R图如下所示:
图4-2辅导员信息E/R图
(2)学生信息E/R图如下所示:
图4-3学生信息E/R图
5.1学生功能模块 学生登录,学生通过输入用户名、密码、角色进行登录,如图5-1所示。
图5-1学生登录界面图
学生通过登录进入系统可查看个人中心、请假申请管理、销假申请管理等内容,如图5-2所示。
图5-2学生功能界图面
请假申请管理,学生可在请假申请管理页面查看学生学号、学生姓名、性别、学院、班级、专业、手机号、辅导工号、辅导姓名、请假日期、请假天数、申请时间、审核回复、审核状态等内容,还可进行新增、修改或删除等操作,如图5-3所示。
图5-3请假申请管理界面图
销假申请管理,学生可在销假申请管理页面查看学生学号、学生姓名、性别、学院、班级、专业、手机号、辅导工号、辅导姓名、请假日期、请假天数、申请时间、审核回复、审核状态等内容,还可进行修改或删除等操作,如图5-4所示。
图5-4销假申请管理界面图
5.2辅导员功能模块
辅导员通过登录进入系统可查看个人中心、学生管理、请假申请管理、销假申请管理等内容,如图5-5所示。
图5-5辅导员功能界面图
学生管理,辅导员可在学生管理页面查看学生学号、学生姓名、性别、手机号、班级、专业、学院、辅导工号、辅导姓名等内容,还可进行新增、修改或删除等操作,如图5-6所示。
图5-6学生管理界面图
请假申请管理,辅导员可在请假申请管理页面查看学生学号、学生姓名、性别、学院、班级、专业、手机号、辅导工号、辅导姓名、请假日期、请假天数、申请时间、审核回复、审核状态等内容,还可进行审核或删除等操作,如图5-7所示。
图5-7请假申请管理界面图
销假申请管理,辅导员可在销假申请管理页面查看学生学号、学生姓名、性别、学院、班级、专业、手机号、辅导工号、辅导姓名、请假日期、请假天数、申请时间、审核回复、审核状态等内容,还可进行审核或删除等操作,如图5-8所示。
1. 什么是Docker 在开篇之前考虑到阅读人群,我觉得有必要向各位读者朋友简单介绍一下Docker是什么,它解决了什么问题?Docker是基于Go语言实现的云开源项目。它对此给出了一个标准化的解决方案-----系统平滑移植,容器虚拟化技术。让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到Linux或Windows操作系统的机器上,也可以实现虚拟化,容器是完全使用沙箱机制,相互之间不会有任何接口。打破过去「程序即应用」的观念。透过镜像(images)将作业系统核心除外,运作应用程式所需要的系统环境,由下而上打包,达到应用程式跨平台间的无缝接轨运作。
Docker的主要目标是“Build,Ship and Run Any App,Anywhere”,也就是通过对应用组件的封装、分发、部署、运行等生命周期的管理,使用户的APP(可以是一个WEB应用或数据库应用等等)及其运行环境能够做到“一次镜像,处处运行”。
Docker官网 点击跳转 Docker Hub 点击跳转
(1) 更快速的应用交付和部署 传统的应用开发完成后,需要提供一套安装程序和配置说明文档,安装部署后需根据配置文档进行繁杂的配置才能正常运行,大大延迟了交付时间。Docker化之后只需要交付少量容器镜像文件,在正式生产环境加载镜像并运行即可,应用安装配置在镜像里已经内置好,大大节省部署配置和测试验证时间,这是也Docker的集装箱思想。
没有集装箱之前运输货物,东西零散容易丢失,有了集装箱之后货物不容易丢失,我们可以把货物想象成程序,目前我们要把程序部署到一台新的机器上,可能会启动不起来,比如少一些配置文件什么的或者少了什么数据,有了docker的集装箱可以保证我们的程序不管运行在哪不会缺东西,就像Docker的logo一样一只鲸鱼背着很多的集装箱。
(2) 更便捷的升级和扩缩容 随着微服务架构和Docker的发展,大量的应用会通过微服务方式架构,应用的开发构建将变成搭乐高积木一样,每个Docker容器将变成一块“积木”,应用的升级将变得非常容易。当现有的容器不足以支撑业务处理时,可通过镜像运行新的容器进行快速扩容,使应用系统的扩容从原先的天级变成分钟级甚至秒级。
(3) 更简单的系统运维 应用容器化运行后,生产环境运行的应用可与开发、测试环境的应用高度一致,容器会将应用程序相关的环境和状态完全封装起来,不会因为底层基础架构和操作系统的不一致性给应用带来影响,产生新的BUG。当出现程序异常时,也可以通过测试环境的相同容器进行快速定位和修复。
(4) 更高效的计算资源利用 Docker是内核级虚拟化,其不像传统的虚拟化技术一样需要额外的Hypervisor支持,所以在一台物理机上可以运行很多个容器实例,可大大提升物理服务器的CPU和内存的利用率,关于虚拟机,和虚拟化以及运行架构等相关概念可以参考小编的这篇文章 虚拟化|虚拟机运行架构。
2. Docker的安装与启动 在安装Docker的之前,首先要确认系统的环境问题,Docker 分为 CE 和 EE 两大版本。CE 即社区版(免费,支持周期 7 个月),EE 即企业版,强调安全,付费使用,支持周期 24 个月。
Docker CE 分为 stable test 和 nightly 三个更新频道。
小编这里主要演示 Docker CE 在 CentOS上的安装。
下面是本篇博客的安装演示环境。
// 本篇博客采用的软件版本 VMware Workstation 16.2.1 // 虚拟机软件 CentOS-7-x86_64-Minimal-1708 // 这里采用的是Minimal版 没有图形化界面 (1) 环境准备 Docker CE 支持 64 位版本 CentOS 7,并且要求内核版本不低于 3.
报错信息 在pytorch的代码中,可能会出现如下错误,
it/s]/pytorch/aten/src/ATen/native/cuda/Indexing.cu:702: indexSelectLargeIndex: block: [394,0,0], thread: [64,0,0] Assertion srcIndex < srcSelectDimSize failed.
问题 仔细阅读这个报错信息,就知道大概率是下标越界错误。比如我一个词表的大小是200,但是我在访问Embedding的时候,id大小超过了200,就会报这种错误。
常见于 index_selct(),
等语句下报错。
之前在介绍OpenCV的组件模块时,我是以OpenCV4来说明的,详情见链接 https://www.hhai.cc/thread-19-1-1.html
那为什么本文为什么要使用OpenCV3.0来搭建OpenCV的开发环境呢?这是因为OpenCV4的编译完成版本已经没有SIFT和SURF算法了。为什么没有呢?因为算法专利的原因。但像SIFT和SURF这样的算法又是我们图像处理中经常要用到的算法,所以本文还是以OpenCV3.0来搭建。
好了,闲言少叙,接下来就来看一看怎样搭建“Windows10+VS2013+OpenCV3.0”的开发环境吧。
第01步 下载并安装VS2013
VS2013百度网盘下载地址见链接 https://www.hhai.cc/thread-61-1-1.html
VS2013的安装方法很简单,下载下来之后,一路Next就行了,这里就先不多叙述了。
第02步 下载并安装OpenCV3.0
OpenCV3.0百度网盘下载地址见链接 https://www.hhai.cc/thread-33-1-1.html
下载得到的是一个exe类型的自解压文件,“Extract to” 你想要存放的文件夹就行了。
第03步 配置环境变量
打开Win10的设置→搜索环境变量
写入下面的环境变量值:
E:\Program Files\OpenCV3.0\build\x86\vc12\bin
当然,上面的这个环境变量路径根据你的OpenCV的保存位置不一样而不一样。
补充说明下,这里我们用32位的OpenCV程序,所以路径是“x86”。
另外关于\opencv\build\x86下的vc9,vc10、vc11、vc12文件夹的名字分别代表什么,详情见链接 https://www.hhai.cc/thread-58-1-1.html 第04步 配置VS2013
打开VS2013,然后新建一个Win32 控制台应用程序:
接着按下面的截图配置,这里我们作永久性配置,即以后新建的工程都按这个配置进行,一劳永逸。
这里要说明一下,如果您想配置只对单个项目(工程)有效,而不对所有的项目(工程)有效,可参考文章 https://www.hhai.cc/thread-59-1-1.html
然后配置包含目录和库目录的路径。
首先是包含目录的设置,截图如下:
E:\Program Files\OpenCV3.0\build\include
E:\Program Files\OpenCV3.0\build\include\opencv
E:\Program Files\OpenCV3.0\build\include\opencv2 然后是库目录的设置,截图如下:
E:\Program Files\OpenCV3.0\build\x86\vc12\lib 最后配置“链接器→输入→附加依赖项”,截图如下:
具体的文件名如下:
Debug版的lib文件:
opencv_ts300d.lib
opencv_world300d.lib
Release版的lib文件:
实际上就是路径D:\OpenCV3.0\opencv\build\x86\vc12\lib 下面不带d后缀的lib文件。
opencv_ts300.lib
opencv_world300.lib
二者的区别:使用Debug版的lib文件支持程序的调试,但是使用Release版的lib文件不支持程序的调试。
还有一个可选配置操作,即要不要禁用VS的4819号警告,如果不禁用这个警告,编译时会出现如下警告提示:
禁用方法详见文章 https://www.hhai.cc/thread-60-1-1.html
用VS的编辑器写入测试代码:
#include <opencv2/opencv.hpp> #include <iostream> using namespace cv; int main() { Mat src_image = imread("
项目运行
环境配置:
Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。
项目技术:
SSM + mybatis + Maven + Vue 等等组成,B/S模式 + Maven管理等等。
环境需要
1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。
2.IDE环境:IDEA,Eclipse,Myeclipse都可以。推荐IDEA;
3.tomcat环境:Tomcat 7.x,8.x,9.x版本均可
4.硬件环境:windows 7/8/10 1G内存以上;或者 Mac OS;
5.是否Maven项目: 否;查看源码目录中是否包含pom.xml;若包含,则为maven项目,否则为非maven项目 6.数据库:MySql 5.7/8.0等版本均可;
毕设帮助,指导,本源码分享,调试部署(见文末)
3.1系统功能 通过前面的功能分析可以将本科生外出请假管理信息系统的功能分为管理员,学生,辅导员三个部分,系统的主要功能包括管理员管理:个人中心、学生管理、辅导员管理、请假信息管理、销假申请管理、系统管理等内容。
1、一般用户的功能及权限
所谓一般用户就是指还没有注册的过客,他们可以浏览主页面上的信息。但如果有想要查找的请假信息时,要登录注册,只有注册成功才有的权限。
2、管理员的功能及权限
用户信息的添加和管理,本科生外出请假信息详细信息添加和管理和文档信息添加和管理以及网站信息管理,这些都是管理员的功能。
3、系统功能结构图
系统功能结构图是系统设计阶段,系统功能结构图只是这个阶段一个基础,整个系统的架构决定了系统的整体模式,是系统的根据。本科生外出请假管理信息系统的整个设计结构如图3-1所示。
图3-1系统功能结构图
3.4系统用例图 系统用例图如下图3-2所示:
图3-2 系统业务用例图
4.1数据库设计 信息管理系统的效率和实现的效果完全取决于数据库结构设计的好坏。为了保证数据的完整性,提高数据库存储的效率,那么统一合理地设计数据库结构是必要的。数据库设计一般包括如下几个步骤:
(1)根据用户需求,确定数据库信息进行保存
对用户的需求分析是数据库设计的第一阶段,用户的需求调研,熟悉企业运作流程,系统要求,这些都是以概念模型为基础的。
(2)设计数据的概念模型
概念模型与数据建模用户的观点一致,用于信息世界的建模工具。通过E-R图可以清楚地描述系统涉及到的实体之间的相互关系。
销假申请实体图如图4-1所示:
图4-1销假申请实体图
辅导员信息实体图如图4-2所示:
图4-2辅导员信息实体图
学生信息实体图如图4-3所示:
图4-3学生信息实体图
4.2.2系统流程图 下图是用户进入这个本科生外出请假管理信息系统后,基本的操作流程。一进入首页便可以进行各种本科生外出请假信息的浏览,包括本科生外出请假信息等,用户可以根据自身的需求来找适合自己的本科生外出请假信息,如果有合适的本科生外出请假信息时,就能进行相应的操作,但前提是必须是登录的用户,不然系统会提示需重新登录才可操作。用户也可通过公告的消息,了解实时的情况,这样有助于结合自身,更好的适应本科生外出请假信息的分享需求,最后用户可以根据自己获得信息的满意程度来进行操作。
图4-4系统操作流程图
5.1学生功能模块 学生注册,学生通过输入学号、密码、学生姓名、专业、年级、班级、联系方式进行注册,如图5-1所示。