目录
预备知识
步骤
第一步:完成设备基本配置
第二步:交换机VLAN配置
第三步:检查VLAN配置信息
第四步:交换机管理VLAN配置
第五步:交换机接口类型及VLAN配置
命令
预备知识 (1)交换机接口工作状态有Access和Trunk。Access端口仅属于一个VLAN,进入和离开该接口时数据帧无变化(不增加或删除标签);Trunk端口默认允许所有VLAN通过,进入Trunk链路时,除本征VLAN (Native VLAN)外都需要增加相应的VLAN标记,离开Trunk链路进入设备时,收到不带标记的数据包将被认为是属于本征VLAN的数据包,其它VLAN的数据帧通过识别VLAN标签字段送向不同的子网接口。
(2)思科交换机端口默认工作在dynamic模式(DynamicAuto和DynamicDesirable),通过DTP协议协商确定端口的工作状态(Trunk或者Access)。
步骤 参考配置网络拓扑图:
完整拓扑图资源已上传。
第一步:完成设备基本配置 SWA、SWB、SWC设备更名,enable、telnet、console口令配置等
参考命令:
Switch>enable Switch#configure terminal Switch(config)#hostname SWA SWA(config)#enable secret cisco SWA(config)#line vty 0 15 SWA(config-line)#password cisco SWA(config-line)#login SWA(config-line)#line console 0 SWA(config-line)#password cisco SWA(config-line)#login SWA(config-line)#exit SWA(config)#service password-encryption 第二步:交换机VLAN配置 参考命令:
/* 创建vlan 配置vlan名 */ Switch(config)#vlan id Switch(config-vlan)#name word 配置任务:配置三个VLAN,VLAN信息如下:
(1)VLAN10:Computer,192.168.10.0/24
(2)VLAN20:Network,192.168.20.0/24
(3)VLAN100:Management,192.168.100.0/24
【交换机SWA参考配置】
SWA(config)#vlan 10 SWA(config-vlan)#name computer SWA(config-vlan)#vlan 20 SWA(config-vlan)#name network SWA(config-vlan)#vlan 100 SWA(config-vlan)#name management 第三步:检查VLAN配置信息 分别在每一台交换机上使用show vlan brief查看VLAN配置信息。
概述 百度今年更改了规则,每次打开百度首页,都会默认显示推荐。
像我这种,不想被外界事物干扰,特别不想看推荐新闻的人来说,非常痛苦。
今天就教教大家如何屏蔽这玩意
安装插件 首先我们需要安装插件:AdGuard
安装插件这里就不教了,很简单。
图标长这样:
添加拦截规则 安装好插件后,打开插件的设置页面:
用户过滤器规则如下:
baidu.com##div.cr-content.new-pmd > div.FYB_RD baidu.com###title-content baidu.com###s_xmancard_news_new > div.s-news-wrapper.clearfix > div.s-news-rank-wrapper.s-news-special-rank-wrapper.c-container-r:first-child > div.san-card:last-child > div.hot-news-wrapper > div.s-rank-title.s-opacity-border1-bottom:first-child baidu.com##div.s-news-list-wrapper.c-container.c-feed-box baidu.com###s_menus_wrapper > span.s-menu-item:last-child 第一行是屏蔽百度搜索右侧的热搜。
其余的都是屏蔽百度首页推荐新闻和热搜。
效果如下图:
至此结束;
目录
1. 操作系统版本
2. 安装环境准备
3. 安装
4. 测试
DolphinDB是由浙江智臾科技有限公司自主研发的高性能的磁盘与内存混合型和列式分布式数据库,集成了功能强大的编程语言和高容量高速度的流数据分析系统,为海量数据(特别是时间序列数据)的快速存储、检索、计算及分析提供一站式解决方案。
本文介绍KeyarchOS上安装DolphinDB数据库的基本步骤。
1. 操作系统版本 [root@localhost ~]# cat /etc/kos-release kos release 5.8 2. 安装环境准备 磁盘文件系统:XFS
架构:X86
版本:DolphinDB V2.0 (JIT)
下载社区版本:DolphinDB_Linux64_V1.30.21.5调整xfs文件系统inode数量 调整前的数量:xfs_info /dev/mapper/kos00-home
调整前查看inode数量:df -i | grep /dev/mapper/kos00-home
调整inode数量 xfs_growfs -m 30 /dev/mapper/kos00-home
调整后查询 xfs_info /dev/mapper/kos00-home | grep imaxpct
安装依赖 yum install ncurese*
3. 安装 unzip 解压 DolphinDB
切换到解压后的server文件夹
使用chmod +x dolphindb 增加执行权限
4. 测试 启动数据库:./dolphindb -maxMemSize 16 使用网页方式登录数据库localshost:884 登录数据库后,测试测试数据库表的创建、删除、更新等操作,如无异常表明安装成功。
主要提示这两个信息:
Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/ ERROR: Could not build wheels for psutil, which is required to install pyproject.toml-based projects 复制代码 解决:
进入 vs官网,下载安装
成功安装后,还要安装以下内容:
重新执行 pip, 成功下载!
注意一定勾选上“使用C++的桌面开发”,只安装 MSBuild工具 是没用的, 我已经帮大家验证过了,然后“使用C++的桌面开发”中的可选内容,我没有测试需要哪一个,我使用的是默认的前五个,你们有兴趣可以自己试试不勾选,然后看看报不报错。
参考链接:https://juejin.cn/post/7162815725239795742
Control System Toolbox(控制系统工具箱):这个工具箱提供了用于分析和设计控制系统的函数和工具。你可以使用它来进行系统建模、控制器设计、稳定性分析等。
Simulink(仿真工具):Simulink 是 MATLAB 的一个附加功能,它提供了一个图形化环境,用于建模、仿真和分析动态系统。你可以使用 Simulink 进行系统建模、控制设计、系统验证等。
Robotics System Toolbox(机器人系统工具箱):如果你对机器人控制和机器人学感兴趣,这个工具箱可以为你提供相关的功能和工具,如运动规划、运动控制、传感器模拟等。
Image Processing Toolbox(图像处理工具箱):这个工具箱提供了用于图像处理和分析的函数和工具。你可以使用它进行图像增强、分割、特征提取等操作。
Signal Processing Toolbox(信号处理工具箱):这个工具箱包含了用于信号处理和分析的函数和工具。你可以使用它进行滤波、频谱分析、信号重构等操作。
Optimization Toolbox(优化工具箱):如果你需要进行数学优化、参数估计或者最优化问题的求解,这个工具箱可以提供相应的函数和算法。
Stateflow(状态图工具):Stateflow 是一个用于建模和仿真离散事件系统的工具。它可以帮助你建立状态机、逻辑控制和事件驱动系统。
Simscape(物理建模工具箱):Simscape 提供了一种建模和仿真物理系统的方式,包括机械、电气、液压和热系统等。你可以使用 Simscape 进行系统级建模和分析。
1、修改数据库字符集
alter database db_new(数据库名) charset utf8mb4;
2、修改表字符集
alter table tb(表名) charset=utf8mb4;
3、修改表字符集和校验规则
alter table tb(表名)charset=utf8mb4 collate=utf8mb4_general_ci;
4、修改表字段的字符集和校验规则
alter table tb(表名)modify name varchar(50)(字段名+字段数据类型) character set utf8 collate utf8_general_ci
一、什么是Binlog?
Mysql的二进制日志可以是Mysql最重要的日志, 记录了所有的DDL和DML语句(除了数据查询语句之外的语句)语句,以事件形式记录,还包含语句所执行的消耗时间,Mysql的二进制日志是事务安全型的。
二进制日志包含两类文件:
1、二进制日志索引文件(文件后缀为".index")用于记录有所的二进制文件;
2、二进制日志文件(文件后缀为“.00000*”)记录了数据库所有的DDL和DML(除了数据查询语句之外的语句)
二、Binlog类型
Mysql Binlog种类有三种:Statement、Mixed、Row。
1、Statement:语句级,binlog会记录每次执行写操作的语句。
优点:节省空间。
缺点:有可能造成数据不一致。
2、row:行级,binlog会记录每次操作后每行记录的结果。
优点:保持数据的绝对一致性。
缺点:占用较大空间。
3、mixed:statement的升级版本,一定程度上解决了因为一些情况而造成的statement模式不一致问题,默认还是statement,在某些情况下,譬如:当函数中包含UUID()时,包含AUTO_INCREMENT字段的表被更新时;执行INSERT DELAYED语句时;用UDF时;会按照ROW的方式进行处理
优点:节省空间,同时兼顾了一定的一致性。
缺点:还有些极个别情况依旧会造成不一致,另外statement和mixed对于需要对binlog的监控的情况都不方便。
三、主从同步机制
1、从数据库执行start slave,开启主从复制开关,slave服务器的IO线程请求从master服务器读取binlog(如果该线程追赶上了主库,会自动进入休眠状态)。
2、主数据库的更新SQL(update、insert、delete)被写到binlog,主库的binlog dump thread会把binlog的内容发送到从库。
3、从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写到relaylog(会记录位置信息,一遍下次继续读取)。
4、从服务器的sql线程会实时检测relaylog中新增的日志内容,把relaylog解析成sql语句并执行。
四、主从同步配置
1、主数据库
1)登入MySQL,创建用于同步的账号(主数据库上创建)
[root@centos7-192.168.1.40 opt]# grant replication slave on *.* to replication@'从库IP地址/IP地址段' identified by '123456'; 2)查看master状态,并记录File:xxx、Position:yyy
[root@centos7-192.168.1.40 opt]# show master status \G; 2、从数据库
1)登入MySQL,指定主数据库服务器信息
mysql>change master to master_host='192.168.1.40', #主数据库IP地址 master_user='replication', #主数据库上的同步账户账号 master_password='starcor', #同步账号密码 master_log_file='mysql-bin.000007', #日志文件(主库:show master status) master_log_pos=341; #偏移位置(主/从库位置偏移了多少) 2)修改auto.cnf配置文件的server-uuid配置
mysql>show variables like 'datadir'; #查看auto.
一、安装
[root@centos7-192.168.1.40 opt]# yum install mariadb-server [root@centos7-192.168.1.40 opt]# yum install mariadb 二、启动
[root@centos7-192.168.1.40 opt]# systemctl start mariadb 三、初始化
[root@centos7-192.168.1.40 opt]# mysql_secure_installation 四、授权
[root@centos7-192.168.1.40 opt]# grant all on *.* to root@'192.168.1.%' with grant option;
实验背景:为了测试其局限性,让一台DNS服务器同时为两台及以上的主机提供域名解析服务。
(在原来的一台DNS服务器为一个IP地址提供域名解析的基础上,让一台DNS服务器同时为两个IP提供DNS服务。)
一、实验拓扑
二、配置DNS服务器
(1)修改区域配置文件/etc/named.rfc1913.zones,新增lisi.com条目;
(2)在/var/named/下新增正向解析条目文件lisi.com.zone;
(3)重启DNS服务;
(4)修改DNS主机网卡配置;
三、配置PC1、PC2网卡
(1)修改192.168.3.201(PC1)网卡配置;
(6)修改192.168.3.1(PC2)网卡配置。
四、验证实验结果
(1)192.168.3.201(PC1) ping 192.168.3.1(PC2);
(2)192.168.3.201(PC1) ping 192.168.3.200(DNS);
(3)192.168.3.1(PC2) ping 192.168.3.200(DNS);
(4)192.168.3.201(PC1) ping www.zhangsan.com(DNS);
(5)192.168.3.201(PC1) ping www.lisi.com(PC2);
(6)192.168.3.1(PC2) ping www.zhangsan.com(DNS);
(7)192.168.3.1(PC2) ping www.lisi.com(PC2);
(8)192.168.3.200(DNS) ping www.zhangsan.com(DNS);
(9)192.168.3.200(DNS) ping www.lisi.com(PC2);
(10)192.168.3.201(PC1) ping www.baidu.com;
(11)192.168.3.1(PC2) ping www.baiduc.om;
(12)192.168.3.200(DNS) ping www.baidu.com.
一、实验背景
某公司内网需要搭建一台DNS服务器用于对机房内设备经行域名解析。例如:有一台服务器的内网IP地址为192.168.3.200,现要求为其添加一个域名www.zhangsan.com,方便公司管理。
二、思路步骤
1、下载并安装DNS服务提供包bind-chroot
[root@centos7-10-0-0-150 opt]# yum install bind-chroot -y 2、修改主配置文件
(1)vim /etc/named.conf ;
(2)在所有接口上监听DNS数据包;
(3)允许任何IP都可以进行DNS解析请求。
3、修改区域配置文件
[root@centos7-10-0-0-150 opt]# vim /etc/named.rfc1912.zones 4、修改正向解析文件
[root@centos7-10-0-0-150 opt]# vim /var/named/zhangsan.zone [root@centos7-10-0-0-150 opt]# systemctl stop firewalld [root@centos7-10-0-0-150 opt]# systemctl status firewalld 5、修改反向解析文件
[root@centos7-10-0-0-150 opt]# /var/named/192.168.3.rapa 6、修改解析文件的访问权限
[root@centos7-10-0-0-150 opt]# chmod 640 /var/named/zhangsan.zone [root@centos7-10-0-0-150 opt]# chmod 640 /var/named/192.168.3.rapa 7、关闭防火墙等服务
[root@centos7-10-0-0-150 opt]# systemctl stop firewalld [root@centos7-10-0-0-150 opt]# systemctl status firewalld 8、启动DNS服务
[root@centos7-10-0-0-150 opt]# systemctl start named [root@centos7-10-0-0-150 opt]# systemctl status named 三、实验环境搭建
1. 【字符串首字母转换为大写】capitalize()方法 语法参考 capitalize()方法用于将字符串的首字母转换为大写,其他字母为小写。capitalize()方法的语法格式如下:
str.capitalize() 锦囊1 将字符串的首字母转换为大写 将字符串“hello word!”的首字母转换为大写,代码如下:
str1 = 'hello word!' print (str1.capitalize()) 锦囊2 字符串全是大写字母只保留首字母大写 字符串全是大写字母的情况下,只保留首字母大写,需要先将大写字母转换为小写字母,然后将首字母大写,代码如下:
cn = '没什么是你能做却办不到的事。' en = "THERE'S NOTHING YOU CAN DO THAT CAN'T BE DONE." print(cn) print('原字符串:',en) #字符串转换为小写后首字母大写 print('转换后:',en.lower().capitalize()) 锦囊3 对指定位置字符串的首字母大写 下面实现对指定位置字符串的首字母大写,先对字符串截取,然后使用capitalize()方法将该字符串首字母转换为大写,之后再进行字符串拼接,代码如下:
cn = '没什么是你能做却办不到的事。' en = "There's nothing you can do that can't be done." print(cn) print('原字符串:',en) #对指定位置字符串转换为首字母大写 print(en[0:16]+en[16:].capitalize()) 2. 【所有大写字符转换为小写】casefold()方法 语法参考 casefold()方法是Python3.3版本之后引入的,其效果和lower()方法非常相似,都可以转换字符串中所有大写字符为小写。
两者的区别是:lower()方法只对ASCII编码,也就是‘A-Z’有效,而casefold()方法对所有大写(包括非中英文的其他语言)都可以转换为小写。casefold()方法的语法格式如下:
str.casefold() 锦囊1 将字符串中的大写字母转换为小写 下面使用casefold()方法对输入的大写字母进行转换,代码如下:
while 1: # 循环输入 str1=input('请输入英文:') print(str1.
由于nanopb在资源受限平台的应用很适合,很多人就考虑使用nanopb进行数据消息的编解码,但是由于RAM受限,不像protobuf-c的实现,可以随意使用RAM,nanopb对于repeated消息的处理,可以分为两种方案,一种是通过额外的*.options描述文件来指定特殊成员的max_size大小,另外一种方案,就是callback的方式来实现,不指定大小,而是由编码阶段决定具体的大小。nanopb官方提供的test以及example示例程序,都没有提到repeated消息包含多层repeated消息时,如何使用callback的方式实现encode和decode,这里给大家演示一下具体的实现方案,详细代码已经放到gitcode比如,这里的测试程序,gwDevSceneInfo消息里面包含的btActionMsg消息就是repeated,这都很正常,一层repeated很容易就使用callback实现,但是btActionMsg消息里面,又包含了repeated Datapoint 消息,这样在encode和decode时候,很多人就不知道怎么实现了。 syntax = "proto3"; enum messageDpType{ DP_TYPE_RAW=0; DP_TYPE_BOOL=1; DP_TYPE_VALUE=2; DP_TYPE_STRING=3; DP_TYPE_ENUM=4; } message Datapoint{ uint32 dpid=1; messageDpType type=2; uint32 len=3; oneof t_value{ string v_raw=4; bool v_bool=5; int32 v_value=6; string v_string=7; int32 v_enum=8; } } message btActionMsg{ oneof actionId{ string deviceId=1; int32 groupId=2; string sceneId=3; } string deviceName=4; string devicePid=5; bool online=6; int32 dp_size=7; repeated Datapoint dp=8; } message gwDevSceneInfo{ string sceneId=1; string sceneName=2; repeated btActionMsg sceneAction=3; }
先说现象 很多人使用LD2410都是使用其1脚的OUT信号对外设进行控制,如果使用继电器的话,注意,继电器不能放在LD2410背后比较近的地方(比如 2cm 1cm的地方),这样会导致LD2410 检测信号频繁触发,就会导致后端接的继电器反复动作,究其原因,笔者也是探索了很久去年11月份的时候,入手了两个LD2410的板子,用于验证技术方案的可行性,由于空间受限,不得不所有元器件密集排放,结果验证以后,就发现继电器会反复触发,当时也试了用屏蔽铜箔把LD2410后面遮挡起来,但是基本没有效果,联系了原厂技术支持,也是云里雾里的,最后放弃了,然后就放下了半年时间没动。
技术分析 最近重拾起来,继续分析误触发的原因在哪里,然后经过分析,原来是LD2410背面的一定区域内,也会有雷达天线的电磁辐射区域,然后也会被天线接收到,在手机端APP看到的现象是,检测到有运动目标,其实能量值没有任何变化,然后就间歇性反复触发,因为检测到了运动目标,原因就是背后的继电器,里面触点吸合时会有运动,就这轻微的运动,也被雷达天线接收到了,然后就做了一个屏蔽罩,完全给继电器屏蔽起来,当然,屏蔽罩也没有接地,其实也不用接地。再测试,就正常了,再也没有误触发动作了。
文章目录 1、我们使用浏览器打开谷歌邮箱官网(gmail.google.com),进入谷歌邮箱的登录主页,我们点击左下方的创建账号按钮,选择个人用途
2、在进入的界面我们不要着急填写资料,我们先修改语言,点击左下方的简体中文。这个时候,会弹出国家语言列表,我们选择“English(United States)”。
3、这个时候,界面会变成英语。输入姓氏和名字,点击 Next
4、选择月份、日、年、性别,点击Next
5、选择Gmail邮箱地址,前两个是随机出的邮箱地址,可以勾选第三个自定义邮箱地址,输入邮箱地址后,点击 Next
6、输入密码,确认密码后,点击 Next
7、添加恢复电子邮件,账号异常或锁定时,Google 可以通过恢复电子邮件联系您。直接点击 Skip 跳过
8、选择中国,填写自己的手机号,点击Next
9、确认账户信息页面,没问题的话,点击 Next
10、隐私条款确认,拉取到底部,点击 I agree 我同意
11、如图,出现此界面,说明 Google 邮箱创建成果
注:创建失败时
手机号码已经注册过在注册时,将语言设置为英语,成功率高
数据库准备 在数据库新建一个库students,然后创建如下一个表,这里演示使用的是MySQL
CREATE TABLE `student` ( `id` int NOT NULL, `class` varchar(255) DEFAULT NULL COMMENT '班级', `name` varchar(255) DEFAULT NULL COMMENT '姓名', `age` int DEFAULT NULL COMMENT '年龄', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci; 项目 新建一个空项目,安装如下三个nuget包
打开终端,到当前项目路径下,输入如下命令
dotnet ef dbcontext scaffold "server=127.0.0.1;uid=root;pwd=123456;database=students" Pomelo.EntityFrameworkCore.MySql
项目中就会自动创建这两个类
public partial class Student { public int Id { get; set; } /// <summary> /// 班级 /// </summary> public string? Class { get; set; } /// <summary> /// 姓名 /// </summary> public string?
我想左连接某表,plus有没有提供api?类型leftJoin方法?
是的,MyBatis Plus 提供了 API 来支持左连接查询。可以使用 leftJoin 方法进行左连接操作。
以下是一个示例代码:
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper; import com.example.demo.entity.User; import com.example.demo.entity.Order; import com.example.demo.mapper.UserMapper; import com.example.demo.mapper.OrderMapper; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; @Service public class UserServiceImpl implements UserService { @Autowired private UserMapper userMapper; @Autowired private OrderMapper orderMapper; public List<User> getUsersWithOrders() { QueryWrapper<User> queryWrapper = new QueryWrapper<>(); queryWrapper.eq("status", 1) .leftJoin("order", "user.id = order.user_id") .select("user.*", "order.order_name"); return userMapper.selectList(queryWrapper); } } 在上述示例中,使用 QueryWrapper 构建查询条件。通过 leftJoin 方法可以进行左连接操作,指定连接的表名和连接条件。通过 select 方法可以指定要查询的字段。
请注意,示例中的 user 表和 order 表是示意性的,实际使用时,请根据实际情况替换为相应的表名。
图像梯度处理 文章目录 图像梯度处理一、图像梯度-Sobel算子二、图像梯度-Scharr算子三、图像梯度-laplacian算子四、常用函数 计算梯度: 相当于划一竖线,计算该线左右两边的像素值的差 一、图像梯度-Sobel算子 Gx及Gy分别代表经横向及纵向边缘检测的图像灰度值,即水平、竖直方向的梯度
import cv2 import matplotlib.pyplot as plt import numpy as np %matplotlib inline #专有魔法指令,即时显示 def cv_show(name,img): cv2.imshow(name,img) cv2.waitKey(0) cv2.destoryAllWindows() sobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=3) cv_show(sobelx,'sobelx') 白到黑是正数,黑到白就是复数了,所有的负数会被截断成0,所以要取绝对值
img = cv2.imread('pie.png', cv2.IMREAD_GRAYSCALE) sobelx = cv2.Sobel(img, cv2.CV_64F, 1, 0, ksize=3) sobelx = cv2.convertScaleAbs(sobelx) cv_show(sobelx, 'sobelx') sobely = cv2.Sobel(img, cv2.CV_64F, 0, 1, ksize=3) sobely = cv2.convertScaleAbs(sobelx) cv_show(sobely, 'sobelx') 一般求出Gx和Gy后还要求一个总和G,G=根号下 (Gx²+Gy²)或 G=|Gx|+|Gy|
# 分别计算x和y,再求和 sobelxy = cv2.addWeighted(sobelx, 0.5, sobely, 0.5, 0) # 0.
❤️觉得内容不错的话,欢迎点赞收藏加关注😊😊😊,后续会继续输入更多优质内容❤️ 👉有问题欢迎大家加关注私戳或者评论(包括但不限于NLP算法相关,linux学习相关,读研读博相关......)👈 博主原文链接:https://www.yourmetaverse.cn/nlp/286/
1. anaconda介绍 1.1 个人对anaconda的理解 个人认为,anaconda就是一个包含python相关包和一些实用工具的集合,例如,我们可以使用anaconda进行Python环境的管理,使得在运行不同的程序时候使用不同的环境,极大避免了一些环境的依赖冲突;我们可以使用jupyter notebook或者jupyter lab等可视化地调试我们的代码;我们可以使用conda命令安装包,解决一些复杂包的依赖问题…
以上这些,不用anaconda,只依靠python我们也可以做到,但是这个过程可能会遇到一系列问题,如不同版本的冲突问题。anaconda将这些资源整合,统一到一个软件里面,安装了anaconda,本质上就是安装了上述的一系列软件,且一键安装,不会出错,减少了分析人员不必要的麻烦。
1.2 来自网络资源的介绍 Anaconda,中文大蟒蛇,是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。Anaconda是包管理器和环境管理器,Jupyter可以将数据分析的代码、图像和文档全部组合到一个web文档中。
Anaconda是一个免费开源的Python和R语言的发行版本,用于计算科学(数据科学、机器学习、大数据处理和预测分析),Anaconda致力于简化包管理和部署。Anaconda的包使用软件包管理系统Conda进行管理。超过1200万人使用Anaconda发行版本,并且Anaconda拥有超过1400个适用于Windows、Linux和MacOS的数据科学软件包。
总结Anaconda的三大特点:
内置python,高度集成python数据科学生态拥有强大的包管理工具-conda可用超过600个python数据科学库 默认环境 /用户名/anaconda3
已经安装了 Python,那么为什么还需要 Anaconda?有以下3个原因:
1)Anaconda 附带了一大批常用数据科学包,它附带了 conda、Python 和 150 多个科学包及其依赖项。因此你可以立即开始处理数据。
2)管理包
Anaconda 是在 conda(一个包管理器和环境管理器)上发展出来的。
在数据分析中,你会用到很多第三方的包,而conda(包管理器)可以很好的帮助你在计算机上安装和管理这些包,包括安装、卸载和更新包。
3)管理环境
为什么需要管理环境呢?
比如你在A项目中用了 Python 2,而新的项目B老大要求使用Python 3,而同时安装两个Python版本可能会造成许多混乱和错误。这时候 conda就可以帮助你为不同的项目建立不同的运行环境。
还有很多项目使用的包版本不同,比如不同的pandas版本,不可能同时安装两个 Numpy 版本,你要做的应该是,为每个 Numpy 版本创建一个环境,然后项目的对应环境中工作。这时候conda就可以帮你做到。
2. anaconda安装 2.1 anaconda软件包下载 点击标题链接即可进入anaconda官网的下载界面,然后下滑到最下面,看到如下界面:
老版本下载链接:https://repo.anaconda.com/archive/
命令行下载模式下可以使用如下方法获取到下载链接:
然后进入命令行输入:
wget $复制到的链接,如: wget https://repo.anaconda.com/archive/Anaconda3-2022.10-Linux-x86_64.sh 即可下载文件
2.2 图形界面安装 图形界面的anaconda的安装比较简单,都是一些图形化的界面,在图形化安装的过程中一直点击下一步即可,但是有几点需要注意的地方:
(1)Windows版本安装的时候目标路径中不能含有空格,同时不能是“unicode”编码。
(2)在“Advanced Installation Options”中不要勾选“Add Anaconda to my PATH environment variable.
目录
0. 前言
1. 普通多继承下,基类和派生类复制转换底层细节(切片)
2. 多继承下的复杂菱形继承
3. 菱形虚拟继承(虚基类)重点
3.1 菱形非虚拟继承对象存储模型
3.2 菱形虚拟继承对象存储模型
3.3 虚拟继承对象存储模型
3.4 多对象继承关系分析其虚基类&虚拟化继承位置
5. 继承的总结和反思
0. 前言 这篇文章主要接上篇文章,从更深层次理解普通继承切片切割以及虚拟继承切片切割,从底部虚拟内存分析,以及分析C++多继承带来的一些问题,和C++解决多继承带来问题采取的方式,并从底层内存观察其逐步实现及原理,最终更深层次感受多继承!并从软件工程分析继承和组合两个概念!!!
1. 普通多继承下,基类和派生类复制转换底层细节(切片) 派生类对象 可以赋值给 基类的对象 / 基类的指针 / 基类的引用。这里有个形象的说法叫切片或者切割。寓意把派生类中父类那部分切来赋值过去。
那么编译器在普通继承下,处理时如何切片,由上面一题目,看内存分析如下:
可知在编译阶段,对象实例化时,实例化对象只存储成员变量,而成员函数会根据其模板参数、所属类域存储在公共代码段,以便进行调用!
在对象实例化时,通过调试观察其虚拟内存得出,实例化对象会提前在栈区或者堆区开辟好空间,其成员变量在栈区先使用低地址在使用高地址,(如结构体,便于通过偏移量计算成员位置),因此可以绘制出对象d实例化时,内存存储数据模型:
而通过上篇文章可知,默认构造,先构造其基类,在构造子类,而对于多继承其根据继承顺序依次构造,因此先实例化_b1,在实例化_b2,其次实例化_d,因此可以看出由低地址到高地址使用实例化!!!
使用调试,观察其切割切片方式:
将&d派生类Derive地址赋值给Base* p1基类指针,此时便会进行切片,切割使用_b1,所以此时p1指向的地址便是原类Derive实例化对象d的地址,但是由于其进行切片,向后只能访问其基类大小个字节,只能访问_b1将&d派生类Derive地址赋值给Base* p2基类指针,此时便会进行切片,切割使用_b2,由于Base2实例化在中间,因此切片时从_b2地址进行切片赋值,向后只能访问其基类大小个字节,只能访问_b2将&d派生类Derive地址赋值给其所属类型的指针变量,此时未发生切片,p3所指向的地址便是整个实例化对象的地址,所以p3的地址便是最开始的地址!!! 最终结果:
p3和p1虽然向后访问数据的偏移量不同,但是所指向同一空间的起始地址&d,_d1,而p2指向同一空间基于Base2实例化的地址,即_b2地址,再根据派生类成员变量内存分布,即可以得出上图结果!!!
总结:
对于派生类引用赋值给基类,底层是对指针和解引用的封装,含义不同,内存操作相同!!!对于派生类直接赋值给基类,会直接进行切割赋值 2. 多继承下的复杂菱形继承 单继承:一个子类只有一个直接父类时称这个继承关系为单继承
多继承:一个子类有两个或以上直接父类时称这个继承关系为多继承
菱形继承:菱形继承是多继承的一种特殊情况。
什么是二义性:(多继承和菱形继承都会导致二义性)
如上图:在多继承中class A和class B若是有多个相同数据成员,此时对于class C而言同名的数据成员会产生二义性的问题,需要通过类域对其进行区分,如下代码:
class A { public: A() :_a(1), _same(10) { } int _a; int _same; }; class B { public: B() :_b(1), _same(1) { } int _b; int _same; }; class C : public A,public B{ public: void Print() { //cout << _same << endl;//err _same无法确定是属于哪个类,二义性 } int _c; }; void test() { C c; //cout << c.
一、使用docker部署minio 1、拉取镜像 docker pull minio/minio 2、创建目录 mkdir -p /home/minio/config mkdir -p /home/minio/data 3、创建Minio容器并运行 docker run -p 9000:9000 -p 9090:9090 \ --net=host \ --name minio \ -d --restart=always \ -e "MINIO_ACCESS_KEY=minioadmin" \ -e "MINIO_SECRET_KEY=minioadmin" \ -v /home/minio/data:/data \ -v /home/minio/config:/root/.minio \ minio/minio server \ /data --console-address ":9090" -address ":9000" 4、登录minio控制台 5、创建buckets存储桶测试 创建一个名为public的存储桶(名字可自定义),上传文件。
通过http://ip:9000/存储桶名/文件名访问文件
若出现:
可以将存储桶的访问权限设置为public.
二、SpringBoot整合minio 1、创建minio-demo项目 2、引入pom依赖 <dependency> <groupId>io.minio</groupId> <artifactId>minio</artifactId> <version>7.0.2</version> </dependency> 3、编写配置文件 在application.yml文件中编写相关配置。
server: port: 8081 spring: # 配置文件上传大小限制 servlet: multipart: max-file-size: 200MB max-request-size: 200MB minio: host: http://127.
一、思想介绍 (1)背景 中缀表达式是最常用的算术表达式形式——运算符在运算数中间。但运算时需要考虑运算符优先级。
后缀表达式是计算机容易运算的表达式,运算符在运算数后面,从左到右进行运算,无需考虑优先级,运算呈线性结构。
1 + 2 * 3// 中缀表达式 1 2 3 * +// 后缀表达式 计算机直接处理中缀表达式是比较困难的,以表达式1 + 2 * 3为例:当计算机读取到1 + 2后就可以直接得出结果3了吗?答案是否定的,因为后面可能会有优先级更高的运算符。
就拿2来说,究竟是先和左操作数计算还是先与右操作数计算?这才是解决这类问题的核心与本质。
(2)中缀表达式转后缀表达式 1.最简单的情况: 后缀表达式也叫逆波兰表达式,我们可以通过以下的方法将中缀表达式转化为后缀表达式(我们用一个栈来临时存储中间遇到的操作符):
遇到操作数,直接存储/输出
遇到操作符
栈为空 or 该操作符的优先级比栈顶的操作符的优先级高 → 将该操作符压栈该操作符的优先级比栈顶的操作符优先级低 or 相同 → 弹出栈顶操作符存储,并将该操作符压栈 遍历结束后将栈里的操作符依次全部弹出
2.分析: 我们以 n1 <O1> n2 <O2> n3 <O3> n4…… 为例加以说明,其中 ni 表示操作数,Oi 表示操作符。
(1)如果 O1 的优先级高于 O2,那么毫无疑问,n2 会先与左操作数运算。
(2)如果 O1 的优先级低于 O2,那么可以让 n2 与右操作数 n3 发生运算吗?答案是否定的!因为n3 能不能先与 n2 运算还取决于 O2 O3 运算符优先级的高低。但是目前我们可以确定 O2 运算符肯定在 O1 运算符前被使用。
tensorRT部署之 代码实现 onnx转engine/trt模型 前提已经装好显卡驱动、cuda、cudnn、以及tensorRT下面将给出Python、C++两种转换方式 1. C++实现 项目属性配置好CUDA、tensoeRT库通常在实际应用中会直接读取onnx模型进行判断,如果对应路径已经存在engine模型,将直接通过tensorrt读入engine,如果没有,则对onnx进行编译生成engine模型后在进行读入TensorRT在线加载模型,并序列化保存支持动态batch的引擎,实现源码可参考 TextandCode一篇超级详细的onnx基础教程(非常好):TextandCode代码实现: #include <iostream> #include <fstream> #include "NvInfer.h" #include "NvOnnxParser.h" // 实例化记录器界面。捕获所有警告消息,但忽略信息性消息 class Logger : public nvinfer1::ILogger { void log(Severity severity, const char* msg) noexcept override { // suppress info-level messages if (severity <= Severity::kWARNING) std::cout << msg << std::endl; } } logger; void ONNX2TensorRT(const char* ONNX_file, std::string save_ngine) { // 1.创建构建器的实例 nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(logger); // 2.创建网络定义 uint32_t flag = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH); nvinfer1::INetworkDefinition* network = builder->createNetworkV2(flag); // 3.
Java 并行框架 Fork Join 一.Fork Join 简介1.框架说明2.任务说明 二.应用示例1.RecursiveTask分组示例分组求和 2.RecursiveAction3.CountedCompleter 三.ForkJoin 实践代码测试1.测试用 Excel 文件2.读取结果 一.Fork Join 简介 1.框架说明 ForkJoinPool 继承自 AbstractExecutorService , AbstractExecutorService 实现了 ExecutorService 接口 ForkJoin 是 Java 自带的一个并行框架,关于并行和并发的差异则看机器是否为多核配置 ForkJoinPool 之于 ThreadPoolExecutor 的差异即封装了一个双端工作队列,用于缓存父子任务,同时引入工 作窃取算法,如果某个队列任务全部处理完成,则该任务队列的线程从其他队列头取任务进行处理,充分利 用子线程资源 2.任务说明 ForkJoin 基于分治思想将大的工作任务,分解为小的处理 任务抽象类 ForkJoinTask , 预置了三个默认实现 RecursiveTask、RecursiveAction、CountedCompleter 二.应用示例 1.RecursiveTask 分组示例 import java.util.ArrayList; import java.util.List; import java.util.concurrent.RecursiveTask; /** * @author * @date 2023-06-08 19:29 * @since 1.8 */ public class ForkRecursiveTask<T> extends RecursiveTask<List<T>> { /** * 任务拆分参数 */ private int left; private int mid; private int right; private int batch; /** * 原始数据 */ private List<T> list; public ForkRecursiveTask(int batch, List<T> list){ this.
一、 MinIO
二、 MinIO安装和启动
三、 pom.xml
四、 applicatin.properties(配置文件)
五、 编写Java业务类
六、 MinIoController
七、 调试结果
一、 MinIO MinIO 是一个基于Apache License v2.0开源协议的对象存储服务。它兼容亚马逊S3云存储服务接口,非常适合于存储大容量非结构化的数据,例如图片、视频、日志文件、备份数据和容器/虚拟机镜像等,而一个对象文件可以是任意大小,从几kb到最大5T不等。
MinIO是一个非常轻量的服务,可以很简单的和其他应用的结合,类似 NodeJS, Redis 或者 MySQL。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/ruoyi-vue-pro
视频教程:https://doc.iocoder.cn/video/
二、 MinIO安装和启动 由于MinIO是一个单独的服务器,需要单独部署,有关MinIO在Windows系统上的使用请查看以下博客。
https://blog.csdn.net/Angel_asp/article/details/128544612
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
项目地址:https://github.com/YunaiV/yudao-cloud
视频教程:https://doc.iocoder.cn/video/
三、 pom.xml <dependency> <groupId>org.
转前辈博客:https://mp.weixin.qq.com/s/VVzDYlFRrOywS9i-cwUXgA
前言 作为一个芯片相关行业的从业者,有时候一直好奇我口中的嵌入式的角度去配置的寄存器,和芯片设计人员口中的寄存器是不是一个东西,正好看见前辈发了这个文章。希望关注的前辈早点更新下一篇,下面来学习一下。
芯片设计中,寄存器(register)基本上是随处可见。无论是承担软件配置的寄存器,还是硬件状态上报的寄存器,亦或是其他类型的寄存器,在芯片的软/硬交互中,起到了桥梁的作用。
(这里的register指对软件或者core可见的寄存器。在芯片内部还存在数量巨大的内部register,但只是芯片工作中的硬件信息存储,core或者软件不可见)
(这里的软件指底层软件或者驱动部分的软件,在应用层的软件一般不会直接操作芯片的寄存器,大多是使用底软开放的API接口)
寄存器简介 寄存器它们同时受到软件和硬件的控制和访问,用于实现数据的传输、处理和存储,并在软硬件之间传递信息。
软件可以使用指令来访问寄存器,以读取或写入数据或状态信息,而硬件则通过总线连接寄存器。
做soc或者ip验证,验证工作常见的可能就是配寄存器,调试配置的顺序。(是的,SOCFPGA验证,呜呜呜)
比如软件改变看门狗的计数周期,需要向模块寄存器写操作;
软件读取芯片内部温度,则需要读取模块的寄存器。
一个寄存器占据一个地址单位,宽度一般为8bit、16bit、32bit等。而且一般会包含多个位域(field),不同的field代表不同的逻辑功能。
一般来说,一个寄存器中的多个位域具有业务相关性,但也不一定是。比如考虑面积因素,也可以将多个不相关的field放在一起,在soc的一些misc模块比较常见。 (之前总有一些misc模块,我说这个名字是啥意思来着,这模块怎么什么都能干)
不同的寄存器类型也即代表了业务类型的差别,以及软硬交互的特点。
寄存器类型多样性 使用场景区分 寄存器按照使用场景或者业务划分,可以分为如下几类:
中断寄存器 中断寄存器是很常见一种类型寄存器,指模块产生中断信号送给Core之后,软件在中断响应函数里,会进行一系列中断寄存器的查询、判断和清除动作。
常见的中断配套寄存器有:
enable寄存器,控制是否产生中断信号。mask寄存器,屏蔽或打开中断。raw寄存器,指示mask之前的中断状态。sta寄存器,指示mask之后的中断标志。clr寄存器,中断清除寄存器。 参数配置寄存器 几乎所有的module都会有参数配置模块,定时器的周期参数,滤波器的系数,总线idle等待cycle数,缓存大小配置,PLL的分频比参数等等。
参数配置寄存器一般跟业务强相关,有的参数可能还会有些约束,比如两个寄存器配置值之间需要满足大小关系,时钟分频比需要和业务模式一致等。
关于参数配置寄存器,有一类需要重点关注的特性,动/静态配置属性。
1、静态参数。有些参数需要在业务启动前配置好,工作过程中保持稳定。此类参数的设计、验证难度尚可,只要根据约束配置即可。 2、动态参数。某些参数是可以在一次业务中进行改配的,软件根据需要实时刷新参数。此类参数的设计、验证复杂度比较高。
设计中需要考虑参数变化的锁存问题;验证则需要考虑参数动态变化的时刻位置,变化时刻位置不准,经常会导致RTL和RM的计算不一致。 系统控制寄存器 还有一类寄存器用于系统的启动及其他状态控制,比如:
系统时钟选择寄存器core启动模式配置寄存器电源域isolation使能寄存器IP模块外部使能控制寄存器 此类寄存器不能放在各IP内部,一般在SOC中实现,用于系统的场景化配置。而且系统控制寄存器没有太多“随机化”的需求,大多和系统的实际场景需求保持一致即可。
时钟/复位寄存器 时钟和复位相关的寄存器也是芯片中一类重要的寄存器,这些寄存器控制着各个子系统或IP模块的时钟/复位信号的产生和关闭。
芯片的时钟和复位结构对中后端实现影响较大,时钟的频率、同步/异步时钟域、复位结构一般也会和中后端达成一致。
时钟/复位相关一般包括如下几类寄存器:
时钟使能,去使能寄存器复位,解复位寄存器时钟使能状态上报寄存器复位状态上报寄存器时钟分频比配置寄存器 时钟/复位寄存器在设计和验证需要关注如下几点:
时钟/复位寄存器的默认值。该默认值如果设置的不合理,子系统或者core没有工作时钟,芯片无法boot。时钟选择模块的无毛刺设计**。对于时钟切换的模块,必须保证在切换过程中无毛刺,一般情况,对于时钟切换,也会有严格的切换配置流程,不能随意动态切换。** dummy寄存器 子系统或者IP模块内部都会预留一些dummy寄存器,一般情况下不会使用。如果有,可能会有如下的使用需求:
软件debug使用。如果在软件调试中,觉得某个IP模块或者系统总线访问有问题,可以对这些dummy寄存器进行读写测试,以排除一些总线通路问题。
ECO预留使用。在RTL freeze之后,如果有bug需要修复,只能通过ECO方式直接修改netlist,此时预留的一些dummy寄存器可以派上用场,做出新的逻辑或者连线等等。
根据修复内容类别来分类,可以分为功能ECO和Timing ECO。功能ECO是修改芯片逻辑功能,Timing ECO是修复Setup/hold Time。 功能ECO可以手改,也可以用工具,比如cadence conformal eco,nandigits的gof eco。 Timing ECO可以直接在后端工具(Innovus、ICC/ICC2)里改,也可以用PrimeTime等STA工具来自动Fix,还可以手工Fix一小部分(有时Timing不满足,也可能是Transition或者cap太大)。 当然如果Timing相差太大,就需要从芯片架构、时钟树结构等方面进一步优化。也可能是达到了工艺的速度极限,该换工艺了。 根据芯片是否已流片,可以分为PreMask ECO和PostMask ECO。Mask就是光罩的意义,制造光罩之前和之后。PreMask ECO可以改动制造的所有的层,而PostMask ECO只能更改金属层,甚至指定的少数金属层。 在芯片设计时,总有一些不确定性,我们就需要考虑预留多种备选方案。比如,提前预留OTP/MTP来trim电路参数和逻辑,私有寄存器来切换备选功能和模式,利用TOP Metal Option、EEPROM、Flash等也是常见好用的方法。只要BUG能用软件修复或者绕过去,或者降低工作时钟频率,或者调节Process corner,反正不影响客户使用的芯片就是好芯片。实在有些影响的小BUG,让销售降低点价格也行。 ———————————————— 版权声明:本文为CSDN博主「NanDigits」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.
文章目录 01 | VMware安装Ubuntu02 | WSL2安装Ubuntu 虚拟机安装Linux的方式分为两种:APP安装、WSL安装
APP安装就是常见的VMware VirtualBox安装的方式,而WSL是Windows系统自带的一个虚拟机应用,可以更好的与Windows进行信息交互(当然,缺点就是没有VMware方式安装之后的图形化界面,WSL安装的Linux只有命令行模式,但是对于想学Linux的我来说,这不刚好吗哈哈哈)
所以下面我主要以WSL安装方式为主,毕竟VMware安装一搜一大堆了
01 | VMware安装Ubuntu 在 VMware中安装Linux的基本步骤如下
下载 VMware/VirtualBox
访问 VMware 的官方网站(https://www.vmware.com/),下载 VMware Workstation 或 VMware Player,然后按照提示进行安装。
下载 Linux ISO 镜像文件(这里以Ubuntu为例)
从指定的网站下载你想要安装的 Linux 发行版的镜像文件。例如,如果你要安装 Ubuntu,则可以从 Ubuntu 官方网站(https://ubuntu.com/)下载 Ubuntu ISO 镜像文件。
创建新虚拟机
启动 VMware,选择“创建新的虚拟机”按钮,进入虚拟机配置向导。根据向导提示设置虚拟机名称、操作系统版本、内存大小和硬盘容量等。
安装 Linux 操作系统
启动虚拟机,选择你下载的 Linux ISO 文件作为虚拟机的启动光盘。然后按照提示进入 Linux 安装向导,完成 Linux 系统的安装。
安装 VMware 工具(增强功能)
安装 Linux 后,在 VMware 菜单栏中选择“虚拟机”>“安装 VMware 工具”。将安装程序挂载到虚拟机的光驱里,然后在 Linux 系统中运行安装程序。
重启虚拟机
安装完 VMware 工具后,需要重新启动虚拟机以使其生效
02 | WSL2安装Ubuntu WSL2安装Ubuntu比之虚拟机安装的好处在于,不需要额外安装APP,与本地系统交互更方便,使用Ubuntu的时候不需要打开APP来启动开机(Windows开机时,Ubuntu就已经准备好了)
【python程序设计】——期末大作业😎 前言🙌一、所用技术:二、 系统设计三、 系统实现3.1 核心功能代码实现:3.2 演示结果展示 总结撒花💞 😎博客昵称:博客小梦
😊最喜欢的座右铭:全神贯注的上吧!!!
😊作者简介:一名热爱C/C++,算法等技术、喜爱运动、热爱K歌、敢于追梦的小博主!
😘博主小留言:哈喽!😄各位CSDN的uu们,我是你的博客好友小梦,希望我的文章可以给您带来一定的帮助,话不多说,文章推上!欢迎大家在评论区唠嗑指正,觉得好的话别忘了一键三连哦!😘
前言🙌 哈喽各位友友们😊,我今天又学到了很多有趣的知识,现在迫不及待的想和大家分享一下!😘我仅已此文,手把手带领大家用python实现学生信息管理系统~ 都是精华内容,可不要错过哟!!!😍😍😍
一、所用技术: 所用技术Python是一种高级、解释型、面向对象、动态数据类型的编程语言。现广泛运用于Web开发、运维自动化、测试自动化及数据挖掘等多个行业和领域。Python语言有很大的优势:比Java、C++简单更易于使用;比PHP易懂易学并且用途更广;比Perl更简洁的语法、更简单的设计,更具可读性、更易于维护,有助于减少Bug。但它的性能不如Java、C、C++这类编译性语言强大。因此本项目开发选用Python语言编写。
二、 系统设计 根据系统分析,画出系统功能模块结构图:
三、 系统实现 3.1 核心功能代码实现: (1)增加学生信息功能的代码实现:
def insert(): print('[新增学生] 开始!') studentId = input('请输入学生的学号:') name = input('请输入学生的姓名:') gender = input('请输入学生的性别:') if gender not in ('男', '女'): print('性别输入的内容不符合要求, 新增失败!') return className = input('请输入学生的班级:') # 使用一个字典把上述的信息给聚合起来. student = { 'studentId': studentId, 'name': name, 'gender': gender, 'className': className } global students students.append(student) # 增加保存操作 save() print('[新增学生] 完毕!
设备外接usb摄像头,进行基本的预览、拍照、录像。相信有些同学在工作中有遇到类似的需求。
uvc camera?不管你之前有没用过,有没遇到过,相信看完这篇文章,一定会带给你一些收获。
这篇文章将从下面几点展开讲解:
一、什么是UVC? 二、UVCCamera开源项目? 三、开源项目集成? 四、demo小改动,录像同时获取实时yuv流? 五、遇到的问题及解决? 一、什么是UVC? UVC全称为USB Video Class,直接翻译过来的意思就是:USB视频类,它是一种专门为USB视频捕获设备定义的协议标准。
这个标准是Microsoft与另外几家设备厂商联合推出的为USB视频捕获设备定义的协议标准,已经成为USB org标准之一。
现在的主流操作系统,都已提供UVC设备驱动,因此符合UVC规格的硬件设备在不需要安装任何的驱动程序下即可在主机中正常使用。是的,目前Android系统已经支持uvc设备。
小结: 讲到这里大家应该有这么个概念了,uvc是一种协议,不同的设备可能会支持不同的协议。如果我们的usb摄像头,需要在Android设备上获得支持的话,那这个摄像头就得是支持uvc协议的摄像头。
二、UVCCamera开源项目? https://github.com/saki4510t/UVCCamera
现在我们在网上搜索uvc camera相关的文章,能查找到的uvc camera相关的项目,可以毫不夸张的说,基本都是基于上面这个开源项目来改的,这个开源项目的确比较牛逼,而且类封装的很好,代码逻辑比较清晰,使用起来也是非常的方便,而且关于摄像头基本的预览、拍照、录像功能都实现了,是个比较完整的工程项目。
我们通过git pull先把代码拉到本地,导入到AndroidStudio中,(不通过git pull 也行,直接下载代码也是可以的。
github 网站在国内不翻墙的话,可能有时访问不了,如何访问不了,大家也可以尝试在gitee上去搜索这个项目下载)。
整个工程的目录结构如下图所示。当然导入的过程中,会遇到一些报错的问题,其实主要是gradle版本的问题。
导入报错的问题,我们统一在这个文章后面再给大家做详细的讲解,包括遇到的问题以及是如何去解决这些问题的。
这个开源项目,除了sdk库的源码,作者还提供了8个demo。这8个demo的具体功能介绍如下:
1)USBCameraTest0 显示如何使用SurfaceView来启动/停止预览。 2)USBCameraTest 显示如何启动/停止预览。这与USBCameraTest0几乎相同, 但是使用自定义的TextureView来显示相机图像而不是使用SurfaceView。 3)USBCameraTest2 演示如何使用MediaCodec编码器将UVC相机(无音频)的视频记录为.MP4文件。 此示例需要API>=18,因为MediaMuxer仅支持API>=18。 4)USBCameraTest3 演示如何将音频(来自内部麦克风)的视频(来自UVC相机)录制为.MP4文件。 这也显示了几种捕捉静止图像的方式。此示例可能最适用于您的定制应用程序的基础项目。 5)USBCameraTest4 显示了访问UVC相机并将视频图像保存到后台服务的方式。 这是最复杂的示例之一,因为这需要使用AIDL的IPC。 6)USBCameraTest5 和USBCameraTest3几乎相同,但使用IFrameCallback接口保存视频图像, 而不是使用来自MediaCodec编码器的输入Surface。 在大多数情况下,您不应使用IFrameCallback来保存图像,因为IFrameCallback比使用Surface要慢很多。 但是,如果您想获取视频帧数据并自行处理它们或将它们作为字节缓冲区传递给其他外部库, 则IFrameCallback将非常有用。 7)USBCameraTest6 这显示了如何将视频图像分割为多个Surface。你可以在这个应用程序中看到视频图像并排观看。 这个例子还展示了如何使用EGL来渲染图像。 如果您想在添加视觉效果/滤镜效果后显示视频图像,则此示例可能会对您有所帮助。 8)USBCameraTest7 这显示了如何使用两个摄像头并显示来自每个摄像头的视频图像。这仍然是实验性的,可能有一些问题。 9)usbCameraTest8 这显示了如何设置/获取uvc控件。目前这只支持亮度和对比度。 供的demo,代码逻辑都很清晰,大家可以根据自己的需求去看对应的demo。
这些demo包含了预览、录像、拍照这些基本的功能。关于调节亮度、对比度这点,可能是不同摄像头的原因,我本地验证了下,看实际上并没有效果,如果有哪位同学后面试试到有效果的,欢迎给我留言,大家交流交流。
Demo7我们可以看到是一个支持2个摄像头的Demo。有多摄像头支持需求的,可以参考这个里面的逻辑。
三、开源项目UVCCaemra的编译、集成? UVCCamera的核心代码都在libuvccamera里面了。
我们要在我们的项目工程中集成这个项目的话,需要2个东西,一个是so库,一个可以调用的java sdk源码。
从上面的截图我们可以很清楚的看到,代码里面主要是包含了jni和java两大部分的内容。编译jni,就可以得到我们需要的so库,java代码可以打包成aar,或者之间直接把整个代码复制到我们的工程目录下,作为库引用也是可以的。
1) so库的编译 现在so库的编译,已经非常的方便了,如下图所示,我们在as的Terminal终端界面,切到jni目录下,直接ndk-build,就可以生成我们需要的so库文件了。
nginxWebUI是一款图形化管理nginx配置的工具,可以使用网页来快速配置nginx的各项功能,包括http协议转发、tcp协议转发、反向代理、负载均衡、静态html服务器、ssl证书自动申请、续签、配置等。配置好后可一建生成nginx.conf文件,同时可控制nginx使用此文件进行启动与重载,完成对nginx的图形化控制闭环。
nginxWebUI也可管理多个nginx服务器集群, 随时一键切换到对应服务器上进行nginx配置,也可以一键将某台服务器配置同步到其他服务器,方便集群管理。
nginx本身功能复杂, nginxWebUI并不能涵盖nginx所有功能,但能覆盖nginx日常90%的功能使用配置,平台没有涵盖到的nginx配置项,可以使用自定义参数模板,在conf文件中生成配置独特的参数。
部署此项目后,配置nginx再也不用上网各种搜索配置代码,再也不用手动申请和配置ssl证书,只需要在本项目中进行增删改查就可方便的配置和启动nginx。
技术说明 本项目是基于solon的web系统,数据库使用h2,因此服务器上不需要安装任何数据库。
本系统通过Let's encrypt申请证书,使用acme.sh脚本进行自动化申请和续签,开启续签的证书将在每天凌晨2点进行续签, 只有超过60天的证书才会进行续签,只支持在linux下签发证书。
添加tcp/ip转发配置支持时,一些低版本的nginx可能需要重新编译,通过添加–with-stream参数指定安装stream模块才能使用,但在ubuntu 18.04下,官方软件库中的nginx已经带有stream模块,不需要重新编译。本系统如果配置了tcp转发项的话,会自动引入ngx_stream_module.so的配置项,如果没有开启则不引入,最大限度优化ngnix配置文件。
jar安装说明 以Ubuntu操作系统为例:
注意:本项目需要在root用户下运行系统命令,极容易被黑客利用,请一定修改密码为复杂密码
安装java运行环境和nginx
Ubuntu:
apt update apt install openjdk-11-jdk apt install nginx Centos:
yum install java-11-openjdk yum install nginx Windows:
下载JDK安装包 https://www.oracle.com/java/technologies/downloads/ 下载nginx http://nginx.org/en/download.html 配置JAVA运行环境 JAVA_HOME : JDK安装目录 Path : JDK安装目录\bin 重启电脑 下载最新版发行包jar
Linux: mkdir /home/nginxWebUI/ wget -O /home/nginxWebUI/nginxWebUI.jar http://file.nginxwebui.cn/nginxWebUI-3.4.4.jar Windows: 直接使用浏览器下载 http://file.nginxwebui.cn/nginxWebUI-3.4.4.jar 到 D:/home/nginxWebUI/nginxWebUI.jar 有新版本只需要修改路径中的版本即可
启动程序
Linux: nohup java -jar -Dfile.encoding=UTF-8 /home/nginxWebUI/nginxWebUI.jar --server.port=8080 --project.home=/home/nginxWebUI/ > /dev/null & Windows: java -jar -Dfile.
`timescale 1ns/1ns module sequence_detect( input clk, input rst_n, input data, output reg match, output reg not_match ); reg [2:0] cnt; reg [5:0] seq; always @(posedge clk or negedge rst_n) begin if(!rst_n) begin cnt <= 0; end else if(cnt == 6-1) begin cnt <= 0; end else begin cnt = cnt + 1; end end always @(posedge clk or negedge rst_n) begin if(!rst_n) begin seq <= 0; end else begin seq = {data,seq[5:1]} ; //先放进去再移位 end end always @(posedge clk or negedge rst_n) begin if(!
报错内容:
ERROR: Could not build wheels for pynacl, which is required to install pyproject.toml-based projects
解决办法:
第一步:
在python 官网下载文件包,点击PyNaCl下载
第二步: 本地安装
pip install E:\Download\PyNaCl-1.5.0-cp36-abi3-win_amd64.whl 其中E:\Download\PyNaCl-1.5.0-cp36-abi3-win_amd64.whl 为本地安装包的路径
其他安装包类似的报错也可以用同样的方式解决
ERROR: Could not build wheels for XXX, which is required to install pyproject.toml-based projects
Python 官网上xxx安装包的地址为:
https://pypi.org/project/xxx/#modal-close
枚举 使用枚举我们可以定义一些带名字的常量。 使用枚举可以清晰地表达意图或创建一组有区别的用例。 TypeScript支持数字的和基于字符串的枚举。
数字枚举 首先我们看看数字枚举,如果你使用过其它编程语言应该会很熟悉。
enum Direction { Up = 1, Down, Left, Right } 如上,我们定义了一个数字枚举, Up使用初始化为 1。 其余的成员会从 1开始自动增长。 换句话说, Direction.Up的值为 1, Down为 2, Left为 3, Right为 4。
我们还可以完全不使用初始化器:
enum Direction { Up, Down, Left, Right, } 现在, Up的值为 0, Down的值为 1等等。 当我们不在乎成员的值的时候,这种自增长的行为是很有用处的,但是要注意每个枚举成员的值都是不同的。
使用枚举很简单:通过枚举的属性来访问枚举成员,和枚举的名字来访问枚举类型:
enum Response { No = 0, Yes = 1, } function respond(recipient: string, message: Response): void { // ... } respond("Princess Caroline", Response.Yes) 数字枚举可以被混入到 计算过的和常量成员(如下所示)。 简短地说,不带初始化器的枚举或者被放在第一的位置,或者被放在使用了数字常量或其它常量初始化了的枚举后面。 换句话说,下面的情况是不被允许的:
`timescale 1ns/1ns module sequence_detect( input clk, input rst_n, input a, output reg match ); reg [8:0] seq; always@(posedge clk or negedge rst_n)begin if(!rst_n) seq <= 0; else seq <= {seq[7:0], a}; end always@(posedge clk or negedge rst_n)begin if(!rst_n) match <= 0; else casez(seq) 9'b011_???_110: match <= 1; default: match <= 0; endcase end endmodule
经典三段式:
`timescale 1ns/1ns module sequence_detect( input clk, input rst_n, input a, output reg match ); parameter[3:0] IDLE = 4'd0; parameter[3:0] S1 = 4'd1; parameter[3:0] S2 = 4'd2; parameter[3:0] S3 = 4'd3; parameter[3:0] S4 = 4'd4; parameter[3:0] S5 = 4'd5; parameter[3:0] S6 = 4'd6; parameter[3:0] S7 = 4'd7; parameter[3:0] S8 = 4'd8; reg[3:0] c_state,n_state; always @(*) begin case(c_state) IDLE: n_state <= a?IDLE:S1; S1: n_state <= a?S2:S1; S2: n_state <= a?S3:S1; S3: n_state <= a?
由于每次安装都要去翻看两个博客,太麻烦,这里做个记录总结。
参考的博客: 参考1
参考2
步骤 先去tensorflow官网找到对应的tensorflow-python-cuDNN-cuda版本
(这里选择了第三行,tensorflow2.4.0+python3.6-3.8+cuDNN8.0+cuda11.0)
选择好版本后,在创建的环境中使用conda命令安装
#安装cuda,先用conda search cuda搜索版本 conda install cudatoolkit=11.0.221 #安装cuDNN 同样使用conda search搜索 conda install cudnn==8.0.5.39 -c conda-forge #安装tensorflow-gpu pip install tensorflow-gpu==2.4.0 如果使用conda search直接搜索不到所需要版本,使用conda search cudnn -c conda-forge进行搜索,安装时的命令同样带上-c conda-forge,如果cuda找不到版本也一样操作
3. 安装完成
大文件上传 前言 在日常开发中,文件上传是常见的操作之一。文件上传技术使得用户可以方便地将本地文件上传到Web服务器上,这在许多场景下都是必需的,比如网盘上传、头像上传等。
但是当我们需要上传比较大的文件的时候,容易碰到以下问题:
上传时间比较久中间一旦出错就需要重新上传一般服务端会对文件的大小进行限制 这两个问题会导致上传时候的用户体验是很不好的,针对存在的这些问题,我们可以通过分片上传来解决,这节课我们就在学习下什么是切片上传,以及怎么实现切片上传。
原理介绍 分片上传的原理就像是把一个大蛋糕切成小块一样。
首先,我们将要上传的大文件分成许多小块,每个小块大小相同,比如每块大小为2MB。然后,我们逐个上传这些小块到服务器。上传的时候,可以同时上传多个小块,也可以一个一个地上传。上传每个小块后,服务器会保存这些小块,并记录它们的顺序和位置信息。
所有小块上传完成后,服务器会把这些小块按照正确的顺序拼接起来,还原成完整的大文件。最后,我们就成功地上传了整个大文件。
分片上传的好处在于它可以减少上传失败的风险。如果在上传过程中出现了问题,只需要重新上传出错的那个小块,而不需要重新上传整个大文件。
此外,分片上传还可以加快上传速度。因为我们可以同时上传多个小块,充分利用网络的带宽。这样就能够更快地完成文件的上传过程。
实现 项目搭建 要实现大文件上传,还需要后端的支持,所以我们就用nodejs来写后端代码。
前端:vue3 + vite
后端:express 框架,用到的工具包:multiparty、fs-extra、cors、body-parser、nodemon
读取文件 通过监听 input 的 change 事件,当选取了本地文件后,可以在回调函数中拿到对应的文件:
const handleUpload = (e: Event) => { const files = (e.target as HTMLInputElement).files if (!files) { return } // 读取选择的文件 console.log(files[0]); } 文件分片 文件分片的核心是用Blob对象的slice方法,我们在上一步获取到选择的文件是一个File对象,它是继承于Blob,所以我们就可以用slice方法对文件进行分片,用法如下:
let blob = instanceOfBlob.slice([start [, end [, contentType]]]}; start 和 end 代表 Blob 里的下标,表示被拷贝进新的 Blob 的字节的起始位置和结束位置。contentType 会给新的 Blob 赋予一个新的文档类型,在这里我们用不到。接下来就来使用slice方法来实现下对文件的分片。
JDK17的下载与安装 前言一、JDK17下载1、官方下载地址 ( Oracle中国的官方网站) 二、JDK17安装1、先看一下我现在的java版本和环境变量2、开始新的安装第一步:双击下载的jdk-17.0.7_windows-x64_bin.exe 进入到安装页面第二步:jdk一般就默认文件下就可以了- 第三步:等待安装第四步:安装完成第五步:可参考java的api 三、JDK17环境变量配置1、点击此电脑、然后点击系统属性、如图所示2、进入到系统高级设置3、点击环境变量4、修改环境变量,5、修改后,点击确认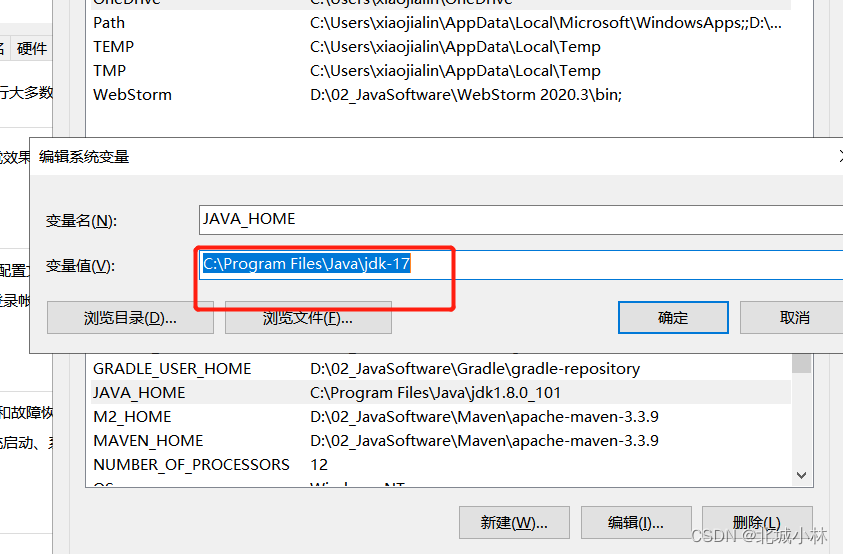6、 在看一下我的PATH中引用的JAVA_HOME,7、 点击确定退出,打开的每个页面都不要直接点×号,要点确定退出 四、安装成功 前言 JDK几乎每年都在发布新的版本,jdk17也是目前最新的 LTS版本,SpringBoot3已经出来一段时间了,也是最少需要JDK17的支撑,总体JDK17很值得学习。 因为工作较忙最近一直没有时间学习,今天有一起安装一下.
一、JDK17下载 JDK 20 is the latest release of Java SE Platform and JDK 17 LTS is the latest long-term support release for the Java SE platform.
1、官方下载地址 ( Oracle中国的官方网站) https://www.oracle.com/cn/java/
进入官方网站,并点击左上角的 下载Java
由于最近的目前是java20,下载17就需要进入的历史版本下载了。
- 直接点击就可以下载,我这里选择的是可直接运行的。exe windows推荐这种哦,方便快捷。
没有登录可能需要登录,创建账号也比较简单,没有账号的可以创建一个
下载完成
二、JDK17安装 1、先看一下我现在的java版本和环境变量 2、开始新的安装 第一步:双击下载的jdk-17.0.7_windows-x64_bin.exe 进入到安装页面 第二步:jdk一般就默认文件下就可以了 - 第三步:等待安装 第四步:安装完成 第五步:可参考java的api https://docs.oracle.com/en/java/javase/17/index.html
三、JDK17环境变量配置 1、点击此电脑、然后点击系统属性、如图所示 2、进入到系统高级设置 3、点击环境变量 4、修改环境变量, 注意我的目前是1.
一、权限分类: 系统权限:系统规定用户使用数据库的权限。(系统权限是对用户而言)。
实体权限:某种权限用户对其它用户的表或视图的存取权限。(是针对表或视图而言的)。
二、系统权限管理: 1、系统权限分类:
DBA: 拥有全部特权,是系统最高权限,只有DBA才可以创建数据库结构。
RESOURCE:拥有Resource权限的用户只可以创建实体,不可以创建数据库结构。
CONNECT:拥有Connect权限的用户只可以登录Oracle,不可以创建实体,不可以创建数据库结构。
对于普通用户:授予connect, resource权限。
对于DBA管理用户:授予connect,resource, dba权限
此次目标用户为只读权限,所以授予connect,resource和select any table 权限 三、具体语句 -- Create the user create user TEST identified by 'TEST1111' default tablespace NPCS --默认表空间名称 temporary tablespace TEMP --临时文件 grant connect to TEST; grant resource to TEST; grant select any table to TEST; grant SELECT ANY DICTIONARY to TEST; grant SELECT ANY TRANSACTION to TEST; grant SELECT ANY SEQUENCE to TEST; grant READER_ROLE to TEST; -- 创建同名service_name (此操作非必须) show parameter service_names; --查询 alter system set service_names='xxx,xxx,xxx,TEST' scope=both; --将查询出来的结果复制到前面的XXX位置,在后面添加上目标同名用户 重启监听即可完成
报错原因:
在创建完成vue 项目之后,在webstorm的命令行窗口用npm install element-ui@2.15.3
命令准备导入element-ui的时候出现这个 错误提示!
解决办法:
重新启动webstorm后直接解决!
1、普通操作 [c\d\y都同理,动作]
dw删除到词尾、db删除到词首、dfa删除到向后查找到a的位置、dFa删除到向前差找到a的位置d/abc 删除到找到abc 2、标记使用 在 Vim 中,标记可以帮助您记住文本的位置。标记是在文本中设置的位置,可以使用单个字符作为名称进行标识。以下是在 Vim 中使用标记的一些常用命令:
设置标记: ma, mb, mc, … (将标记设置为a, b, c等等)跳转到标记行首: 'a, 'b, 'c, … (跳转到标记a, b, c等等所在的行首位置)跳转到标记: `a, … (跳转到标记a的位置)查看所有标记: :marks (显示所有标记的列表)删除标记: :delmarks a, :delmarks a b c ,(删除标记a,或删除多个标记) 删除所有标记: :delmarks!删除从光标到标记:d`a d’a【中间的行】 动作:d、c、y 在使用标记时,您可以将其用于定位文件中的重要位置,例如跳转到特定的行、函数、段落等。标记在 Vim 中非常有用,可以使您更有效地浏览和编辑文本。
3、操作’"[{包围的文本 diw: d[操作]、i[范围]、w[操作对象]
其中,di( 表示“删除内部括号”,即删除圆括号内的所有文本。
da( 表示“删除包括括号”,即删除圆括号内的所有文本。
操作:
y 复制文本c 修改文本d 删除文本v 选择文本
范围:i 内部的a 包括括号s 删除括号【vim-surround插件】
ysiw( 增加括号、 csw( cs([ 更改环绕
http://yyq123.github.io/learn-vim/learn-vim-plugin-surround.html
https://github.com/tpope/vim-surround 操作对象:
在平常的工作中,OpenFeign作为微服务间的调用组件使用的非常普遍,接口配合注解的调用方式突出一个简便,让我们能无需关注内部细节就能实现服务间的接口调用。
但是工作中用久了,发现Feign也有些使用起来麻烦的地方,下面先来看一个问题,再看看我们在工作中是如何解决,以达到简化Feign使用的目的。
先看问题 在一个项目开发的过程中,我们通常会区分开发环境、测试环境和生产环境,如果有的项目要求更高的话,可能还会有个预生产环境。
开发环境作为和前端开发联调的环境,一般使用起来都比较随意,而我们在进行本地开发的时候,有时候也会将本地启动的微服务注册到注册中心nacos上,方便进行调试。
这样,注册中心的一个微服务可能就会拥有多个服务实例,就像下面这样:
眼尖的小伙伴肯定发现了,这两个实例的ip地址有一点不同。
线上环境现在一般使用容器化部署,通常都是由流水线工具打成镜像然后扔到docker中运行,因此我们去看一下服务在docker容器内的ip:
可以看到,这就是注册到nacos上的服务地址之一,而列表中192开头的另一个ip,则是我们本地启动的服务的局域网地址。看一下下面这张图,就能对整个流程一目了然了。
总结一下:
两个service都是通过宿主机的ip和port,把自己的信息注册到nacos上
线上环境的service注册时使用docker内部ip地址
本地的service注册时使用本地局域网地址
那么这时候问题就来了,当我本地再启动一个serviceB,通过FeignClient来调用serviceA中的接口时,因为Feign本身的负载均衡,就可能把请求负载均衡到两个不同的serviceA实例。
如果这个调用请求被负载均衡到本地serviceA的话,那么没什么问题,两个服务都在同一个192.168网段内,可以正常访问。但是如果负载均衡请求到运行在docker内的serviceA的话,那么问题来了,因为网络不通,所以会请求失败:
说白了,就是本地的192.168和docker内的虚拟网段172.17属于纯二层的两个不同网段,不能互访,所以无法直接调用。
那么,如果想在调试时把请求稳定打到本地服务的话,有一个办法,就是指定在FeignClient中添加url参数,指定调用的地址:
@FeignClient(value = "serviceA",url = "http://127.0.0.1:8088/") public interface ClientA { @GetMapping("/test/get") String get(); } 但是这么一来也会带来点问题:
代码上线时需要再把注解中的url删掉,还要再次修改代码,如果忘了的话会引起线上问题
如果测试的FeignClient很多的话,每个都需要配置url,修改起来很麻烦
那么,有什么办法进行改进呢?为了解决这个问题,我们还是得从Feign的原理说起。
Feign原理 Feign的实现和工作原理,我以前写过一篇简单的源码分析,大家可以简单花个几分钟先铺垫一下,Feign核心源码解析。明白了原理,后面理解起来更方便一些。
简单来说,就是项目中加的@EnableFeignClients这个注解,实现时有一行很重要的代码:
@Import(FeignClientsRegistrar.class) 这个类实现了ImportBeanDefinitionRegistrar接口,在这个接口的registerBeanDefinitions方法中,可以手动创建BeanDefinition并注册,之后spring会根据BeanDefinition实例化生成bean,并放入容器中。
Feign就是通过这种方式,扫描添加了@FeignClient注解的接口,然后一步步生成代理对象,具体流程可以看一下下面这张图:
后续在请求时,通过代理对象的FeignInvocationHandler进行拦截,并根据对应方法进行处理器的分发,完成后续的http请求操作。
ImportBeanDefinitionRegistrar 上面提到的ImportBeanDefinitionRegistrar,在整个创建FeignClient的代理过程中非常重要, 所以我们先写一个简单的例子看一下它的用法。先定义一个实体类:
@Data @AllArgsConstructor public class User { Long id; String name; } 通过BeanDefinitionBuilder,向这个实体类的构造方法中传入具体值,最后生成一个BeanDefinition:
public class MyBeanDefinitionRegistrar implements ImportBeanDefinitionRegistrar { @Override public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) { BeanDefinitionBuilder builder = BeanDefinitionBuilder.
近日,我鼓起勇气从头开始正儿八经地配置一个更轻量、更趁手的 Python 开发环境。经过一番折腾,我比较顺利地在 Windows 10 上配置了一个比较满意的 Python 环境:
安装稳定版本的 Python 3.7使用微软出品的 VS Code 作为 IDE使用 venv 模块为不同 Python 项目搭建相互隔离的运行环境使用 Git 对 Python 项目进行版本管理
本文就用大白话来介绍我的配置过程,对其中涉及的专业术语和操作加以解释,供自己日后复习查看,也希望能为准备尝试 Python 的新手朋友提供参考。 欢迎闲来无事的大小朋友们一起来玩 Python!
⚠️ 注:本文的操作在 Windows 10 上进行,但配置思路和所用软件均适用于 macOS。
安装 Python 在电脑上配置 Python 开发环境,第一件事当然是安装 Python 。安装 Python 就像安装一个其他软件一样:到 Python 官网上下载安装程序,然后安装到电脑上。
在 https://www.python.org,我们选择「Downloads——Windows」(根据你电脑的操作系统来选择),就可以来到供 Windows 操作系统使用的 Python 的下载页面。
▲ 在 Python 下载页面,每个版本都有对应的下载链接。
在这个页面,我们可以看到诸多的 Python 版本可供下载。这个时候,我们就迎来了一个关键的选择:选择哪个版本的 Python ?
Python 目前有两个大版本:Python 2 和 Python 3。Python 2 目前已经不再更新,最后一个版本是 Python 2.
单机版的redis,如果这台redis挂了,所有的redis读写操作都会受影响,而且单台redis容量上限比较低,
Redis有三种集群模式:主从集群模式、哨兵集群模式和分片集群模式
(1)主从模式
所有对数据库的修改操作请求都发送到主数据库上,再由主数据库将数据同步到从数据库上,从数据库只用来读
也就是说这个过程中,主数据库承担写操作和数据同步的任务,而从数据库则可以承当读操作的任务,这样可以缓解整个系统的读压力
也就是说:将数据写(修改)到主数据库上,读数据的话是从从数据库中读
一个主数据库可以拥有多个从数据库,从数据库还可以作为其他数据库的主库
比如在上面这张图张你可以看到:
主数据库Master的从数据库是Slave-0和Slave-1
同时Slave-1作为主数据库,Slave-1-0和Slave-1-1是它的从数据库
主redis将数据同步到从redis的过程:
(1)一个从数据库在启动后,会向主数据库发送SYNC命令,表示从数据库想要同步主数据库的数据
(2)主数据库在接收到SYNC命令后会开始在后台保存快照(即RDB持久化的过程),并将保存快照期间接收到的命令缓存起来。在该持久化过程中会生成一个rdb快照文件
(3)主数据库发送RDB快照文件给从数据库
(4)从数据库收到主数据库的rdb快照文件后,载入该快照文件到本地,加载RDB文件,以上过程被称为复制初始化
(5)在复制初始化结束后,主数据库在每次收到写命令时都会将命令同步给从数据库,从而保证主从数据库的数据一致
也就是说复制初始化是通过rdb文件,后续你的同步就是直接发送主redis执行的写命令
可以认为复制初始化就是全量同步,后续同步就是增量同步
配置主从复制:
配置一台redis服务器作为从机slave(主数据库无须进行任何配置,只需要在从数据库上进行配置)
指定这台redis服务器是谁的从机,找谁当自己的主机
127.0.0.1:6380> slaveof 168.19.20.13 6379
#如果master有密码,则需设置masterauth 主数据库的密码
masterauth=123
这里表示127.0.0.1这台redis服务器的主机是168.19.20.13 (2)哨兵模式
高可用方案:故障发生时,可以自动进行主从切换,运维人员可以继续睡大觉
哨兵结点通过心跳机制持续监控主从节点的健康
客户端先连接哨兵,然后哨兵告诉它去哪台redis服务器中获取数据
在主从模式上添加了一个哨兵的角色来监控集群的运行状态,如果master故障,会将一个slave提升为master
哨兵是如何得知redis集群中每个redis结点的状态的?通过心跳机制,每隔一秒就向集群中每一个redis发送ping命令,如果未在规定时间响应就认为该redis下线了(主观下线),如果超过一定数量(比如超过一半)的sentinel都认为该实例主观下线,那该redis就是客观下线
主redis宕机了如何从从redis中选一个成为新的主redis
应用程序问哨兵我现在应该连哪一台redis服务器
redis2作为redis1的slave,再引入一台redis sentinal 哨兵,这台哨兵和两台redis服务器都进行长连接,而且采用redis2作为redis1的slave,再引入一台redis sentinal 哨兵,这台哨兵和两台redis服务器都进行长连接,而且是心跳机制,此时后端服务器不再去redis1或者redis2中查询,而是直接问redis sentinal,应该连哪一台redis,于是后端服务器就会去连接主redis(master redis)
当redis1作为master产生了异常 ,心跳就会被破坏掉,redis sentinal就会马上将redis2 切换成master,将redis1切换成slave,这个时候sentinal会告诉后端服务器产生了change,你重新来ask一下
如果哨兵监测到Master主数据库宕机时会自动将Slave从数据库切换成Master主数据库,然后通过发布与订阅模式通知其他从服务器修改配置文件,完成主数据库和从数据库的切换
一个哨兵进程对redis服务器进行监控可能会出现问题,为此,可以设置多个哨兵进行监控,各个哨兵之间还会进行监控,形成多哨兵模式
(3)分片集群模式
主从和哨兵两种集群模式有两个问题没有解决:海量数据存储和高并发写
1.分片集群有多个master,每个master保存不同数据(这些redis都是主数据库,一个redis保存20G的数据,那三个redis就可以保存60G的数据)
2.而且每个master redis有多个slave redis
3.master之间通过互相ping来监测彼此的健康状态
客户端可以请求集群内任意的结点,最终都会被转发到正确的结点
显然分片集群模式虽然没有哨兵,但是却实现了哨兵的功能
在集群中超过半数的节点检测到某个节点Fail后将该节点设置为Fail状态
将0~16383共16384个插槽值分配给master redis,每个master redis会获得一些插槽值:(N个结点每个结点可以分配到的插槽值是16384/N)
第一台master redis分配了0-5460号插槽值
第二台master redis分配了5461-10922号插槽值
第三台master redis分配了10923-16383号插槽值
最近做项目遇到一个问题,从别的地方拿过来的工程是用maven构建的,而且用了许多自有的依赖包,如果一个个的上传到私服简直是浪费时间,于是用Python 写了一个批量上传的工具,简化自己的工作量。
使用的是Python3,分别依赖了os、subprocess、re包:
os:读取本地仓库下的jar和pom;subprocess:执行mvn deploy命令;re:正则识别文件名中的groupId、artifactId、version等信息。 以下为完整代码
import os import subprocess import re REPO_URL = "仓库url" REPO_ID = "仓库id" REPO_USERNAME = "用户名" REPO_PASSWORD = "密码" FILES_DIR = "本地仓库地址" def upload_file(file_path): filename = os.path.basename(file_path) match = re.match(r'^(.+?)-(?:(\d+\.\d+(?:\.\d+)?(?:-[\w\.]+)?)?(?:-(.*?))?)((?:-SNAPSHOT)?\..+)$', filename) if match: artifact_id, version, classifier, packaging = match.groups() if classifier is None: classifier = '' packaging = packaging.replace(".","") group_id = os.path.relpath(os.path.dirname(os.path.dirname(os.path.dirname(file_path))), FILES_DIR).replace(os.path.sep, ".") print(f"Uploading {filename} (groupId={group_id}) (artifact_id={artifact_id}) (version={version}) (packaging={packaging})") if (filename.find("通过文件名过滤") != -1): subprocess.
接口 介绍 TypeScript的核心原则之一是对值所具有的结构进行类型检查。 它有时被称做“鸭式辨型法”或“结构性子类型化”。 在TypeScript里,接口的作用就是为这些类型命名和为你的代码或第三方代码定义契约。
接口初探 下面通过一个简单示例来观察接口是如何工作的:
function printLabel(labelledObj: { label: string }) { console.log(labelledObj.label); } let myObj = { size: 10, label: "Size 10 Object" }; printLabel(myObj); 类型检查器会查看printLabel的调用。 printLabel有一个参数,并要求这个对象参数有一个名为label类型为string的属性。 需要注意的是,我们传入的对象参数实际上会包含很多属性,但是编译器只会检查那些必需的属性是否存在,并且其类型是否匹配。 然而,有些时候TypeScript却并不会这么宽松,我们下面会稍做讲解。
下面我们重写上面的例子,这次使用接口来描述:必须包含一个label属性且类型为string:
interface LabelledValue { label: string; } function printLabel(labelledObj: LabelledValue) { console.log(labelledObj.label); } let myObj = {size: 10, label: "Size 10 Object"}; printLabel(myObj); LabelledValue接口就好比一个名字,用来描述上面例子里的要求。 它代表了有一个 label属性且类型为string的对象。 需要注意的是,我们在这里并不能像在其它语言里一样,说传给 printLabel的对象实现了这个接口。我们只会去关注值的外形。 只要传入的对象满足上面提到的必要条件,那么它就是被允许的。
还有一点值得提的是,类型检查器不会去检查属性的顺序,只要相应的属性存在并且类型也是对的就可以。
可选属性 接口里的属性不全都是必需的。 有些是只在某些条件下存在,或者根本不存在。 可选属性在应用“option bags”模式时很常用,即给函数传入的参数对象中只有部分属性赋值了。
下面是应用了“option bags”的例子:
@TOC删除线格式
一、文件管理
目录操作
创建目录:mkdir mkdir命令可以创建一个新的目录。例如,在当前目录下创建一个名为“test”的目录:
mkdir test
2. 删除目录:rmdir
rmdir命令可以删除一个空目录。例如,要删除名为“test”的空目录,
rmdir test
如果目录不为空,可以使用rm -r命令来递归删除目录及其所有子目录和文件。
rm -r
3. 列出目录内容:ls
使用ls命令可以列出目录中的所有文件和子目录
ls
ls -l命令显示文件和文件夹的权限、所有者、大小、创建日期等详细信息。
ls -l
4. 更改目录:cd
使用cd命令可以更改当前工作目录。例如,要进入名为“test”的目录
cd test
5. 复制目录:cp -r
使用cp -r命令可以复制一个目录及其所有子目录和文件。例如,要将名为“test”的目录复制到名为“backup”的目录中
cp -r test backup
6. 移动目录:mv
使用mv命令可以移动或重命名一个目录。例如,要将名为“test”的目录移动到名为“backup”的目录中,可以在终端中输入以下命令:mv test backup。如果你想要重命名目录,可以将目录的新名称作为第二个参数传递给mv命令。
查找目录:使用find命令可以在文件系统中查找目录。例如,要查找名为“test”的目录,可以在终端中输入以下命令:find / -type d -name test。这将从根目录开始搜索名为“test”的目录。 说出10个以上的Linux命令
ls:列出当前目录下的所有文件和文件夹。
ls
该命令单独使用时,只会简单地列出当前目录下的文件和文件夹名称,不会显示文件或文件夹的详细信息。
ls -l
将显示文件和文件夹的权限、所有者、大小、创建日期等详细信息
cd:切换当前工作目录。
示例:cd ~/Documents
解释:在这个例子中,~ 表示当前用户的 home 目录,即主文件夹。这个命令会将工作目录切换到当前用户的 Documents 文件夹。
pwd:显示当前所在路径。
示例:pwd
解释:该命令会在屏幕上显示当前所在路径的绝对路径。
mkdir:创建新目录。
安装node时,位置最好不要装在c盘,这里,我在D盘下创建了文件夹"node",安装地址选择在该文件夹下
一直next,直到安装结束,打开"node"文件夹,安装完后,里面的配置文件和文件夹如下图所示:
打开黑窗口,输入dos命令,“node -v” ,测试node有没有安装成功,出现版本号即安装成功。
安装成功后必须要配置全局变量,首先在node文件夹下,创建文件夹,node_cache(缓存目录)和node_global(全局包存放目录)
打开dos命令行输入两行命令
npm config set prefix “D:\node\node_global” npm config set cache “D:\node\node_cache” npm默认全局安装路径 C:\Users\stone\AppData\Roaming\npm(可全局安装任何node第三方库查看安装位置)
最后配置全局变量,首先,右键我的电脑-属性-高级属性配置-系统属性-环境变量
在系统变量里新建 NODE_PATH D:\nodejs\node_global\node_modules
在系统变量里新建 NODE_HOME D:\node
在用户变量Path上新增D:\node\node_global
测试: 在dos中随意全局npm安装一个第三方组件库的包,再在任一路径下检测其版本`xxx -v`,最后查看在D:\node\node_global中有无安装包。以安装成功后的vue脚手架为例:
【扩展】dos查看全局下载的第三方模块npm list -g --depth 0
🏡博客主页: Passerby_Wang的博客_CSDN博客-系统运维,云计算,Linux基础领域博主
🌐所属专栏:『专治疑难系列』
🌌上期文章: 专治疑难系列 - 解决Ubuntu忘记root密码问题
📰如觉得博主文章写的不错或对你有所帮助的话,还望大家多多支持呀!关注、点赞、收藏、评论。
目录
一、问题描述
1、添加网络打印机,输入网络凭证连接到打印机IP地址,勾选“记住我的凭据”后,账户名输入错误;
2、发现账户名无法修改,点击“更多选项”,选择“使用其他账户”,重新输入用户名和密码,点击确认;
3、系统提示“提供的凭证跟现有的一套凭证相冲突。覆盖现有的一套凭证可能会造成一些正在运行的应用程序非正常停止。确实要覆盖现有的一套凭证?”
二、解决方法
1、首先使用 “Win+ R” 组合快捷打开运行对话框(Windows键是键盘上有微软标志介于Ctrl和Alt之间的那个键),打开运行命令框后,输入“control.exe”然后点击“确定”,打开win11的控制面板;
2、进入“所有控制面板项”页面,点击“凭据管理器”;
3、进入“凭据管理器”页面,点击“Windows凭据”;
4、进入“Windows凭据”页面,点击“编辑”;
5、进入“编辑Windows凭据”页面,填写用户名和密码后点击保存。
三、问题已解决
1、重新添加网络打印机,输入网络凭证连接到打印机IP地址,右键点击连接打印机;
2、安装好打印机驱动后,可以愉快的使用打印机了。
一、问题描述 1、添加网络打印机,输入网络凭证连接到打印机IP地址,勾选“记住我的凭据”后,账户名输入错误; 2、发现账户名无法修改,点击“更多选项”,选择“使用其他账户”,重新输入用户名和密码,点击确认; 3、系统提示“提供的凭证跟现有的一套凭证相冲突。覆盖现有的一套凭证可能会造成一些正在运行的应用程序非正常停止。确实要覆盖现有的一套凭证?” 二、解决方法 1、首先使用 “Win+ R” 组合快捷打开运行对话框(Windows键是键盘上有微软标志介于Ctrl和Alt之间的那个键),打开运行命令框后,输入“control.exe”然后点击“确定”,打开win11的控制面板; 2、进入“所有控制面板项”页面,点击“凭据管理器”; 3、进入“凭据管理器”页面,点击“Windows凭据”; 4、进入“Windows凭据”页面,点击“编辑”; 5、进入“编辑Windows凭据”页面,填写用户名和密码后点击保存。 三、问题已解决 1、重新添加网络打印机,输入网络凭证连接到打印机IP地址,右键点击连接打印机; 2、安装好打印机驱动后,可以愉快的使用打印机了。
一、RHCE认证教材 链接: https://pan.baidu.com/s/1cWZtYIpTsuQyEcKcW-uVUg?pwd=gkfi 提取码: gkfi --来自百度网盘超级会员v4的分享
二、RHCE认证讲义 链接: https://pan.baidu.com/s/1VuzB8rbVKAeMXLcqVIUcwA?pwd=y9k9 提取码: y9k9 --来自百度网盘超级会员v4的分享
三、RHCE认证题库 链接: https://pan.baidu.com/s/1O8QBD5PAgfAYVpBUHKOy_Q?pwd=v2vx 提取码: v2vx --来自百度网盘超级会员v4的分享
大家好,我是 Chocolate。
前不久看到一篇不错的内容,来自于 The React Ecosystem in 2023,也结合自己今年使用的 React 生态总结一下。
本文并非视频演讲稿,和视频内容还是有一点点区别,视频内容相对来说会更加详细一点,这里放一下视频传送门:
b 站: https://www.bilibili.com/video/BV1Zh4y1G78R/
youtube: https://www.youtube.com/watch?v=VvSIM1XKuIA
选择你喜欢的平台即可,如果可以的话留下你的点赞和关注就是对我更新最大的鼓励!
前言 React 不知不觉到 23 年已经有 10 年之久了,下面是来自于网图,关于 10 周年的生日蛋糕:
关于这个生态方面,也有挺多内容,去年下半年到今年上半年,这一年时间,我也逐渐接触了一些新的工具,有些非常好用,就是那种一旦使用了,在任何项目中都必须要安装了,不用就顺手,那我们就快速进入正文吧:
开始使用 我记得我在接触前端的时候,那会还在大三阶段,还只是懵懂的学了一些 html 和 js,css 都没怎么用,说实在一点,还只是使用 java + jsp 实现一些非常简单的逻辑,可是那会还是觉得很有成就感,能自己做点表单页面出来。
再到之后大三课程设计了解到了 Vue 和 React 框架,最开始其实还是接触 Vue,不过还是 Vue2 的时代。
后来因为工作需要,开始接触了 react,接触了 hooks 语法之后,感觉就很棒,可惜 Vue3 慢了那么一点点,当时还不够稳定,但现阶段 Vue 也挺香的,跟着 antfu 大佬学就是了,很多工具也是从他那里了解的。
环境问题 过去学编程总是会遇到环境问题,学生时代主要是 windows 电脑,有时候找到了不对的教程, npm run 一跑就报错,但是正因为解决了这些问题,能力也不断提升了。
现在我们也可以使用一些云端 IDE,比如 CodeSandbox 与 StackBlitz,国内的话比如 cloudstudio 等,对于初学者来说可以直接跟随文档教程去写代码了,而无需考虑环境问题,有时候就是环境老是报错,一下就劝退了。