在Docker容器中,可以通过修改 /etc/hosts文件来配置主机名和IP地址的映射关系。下面是修改Docker容器中 /etc/hosts文件的教程:
进入Docker容器:使用以下命令进入正在运行的Docker容器。
docker exec -it <container_id> bash 将 <container_id> 替换为你要进入的容器的ID或名称。
编辑 /etc/hosts文件:在容器中执行以下命令编辑 /etc/hosts文件。
vi /etc/hosts 这将使用Vi编辑器打开 /etc/hosts文件。如果你熟悉其他文本编辑器,也可以使用其他编辑器替代Vi。
在文件中添加映射关系:在打开的文件中,使用以下格式将主机名和IP地址添加到 /etc/hosts文件中。
<IP_address> <hostname> 将 <IP_address> 替换为要映射的IP地址,<hostname> 替换为要映射的主机名。
例如,添加映射关系为 192.168.0.10 example.com。
保存并退出:在Vi编辑器中,按下 Esc 键退出编辑模式,然后输入 :wq 并按下 Enter 键保存并退出编辑器。 退出容器:在容器中执行以下命令退出容器。
exit 现在,你已经成功修改了Docker容器中的 /etc/hosts文件,添加了主机名和IP地址的映射关系。这使得在容器内部可以使用指定的主机名来访问相应的IP地址。请确保在修改 /etc/hosts文件时小心,避免错误的配置导致意外的问题发生。
char类型数组有两种输出方法
1.for循环输出
char arr[] = { 'a','b','c','d','e','f','g' }; for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) { printf("%c", arr[i]); } 2.字符串输出(即把字符型数组当成字符串)
char arr[] = { 'a','b','c','d','e','f','g','\0'}; printf("%s", arr); 值得注意的是,使用第二种方法时,要在数组末端加上‘\0’,因为字符串输出时需要检测‘\0’,检测到‘\0’的停止输出,若没有‘\0’则会出现乱码,运行结果如下:
补充:字符型数组也可以存储整型数字,输出时会将整型数字当成ASCII码,并转换为相应的字符
当字符型数组存储整型数字时,使用字符型输出,数组末端加上0,因为‘\0’的ASCII码就是0
char arr[] = { 73, 32, 99, 97, 110, 32, 100, 111, 32, 105, 116 , 33, 0 }; printf("%s", arr);
文章目录 前言
PaddleOCR介绍
一、PaddleOCR环境搭建
1.Anaconda安装
2.cuda和cudnn安装
(1)判断下载什么版本
(2)下载CUDA Toolkit
(3)下载cuDNN
(3) 验证是否安装成功
3.创建虚拟环境
4.pycharm中配置环境
5.验证环境
二、制作数据集
三、训练文字检测模型
1. 下载模型训练文件
2. 配置模型文件 3.开始训练
4. 测试训练模型
四、训练文字识别模型
1. 配置模型文件 2.模型训练
3.模型测试
五、转换成推理模型
六、推理模型应用
总结
前言 前段时间搞了一个PaddleOCR相关的项目, 一路跌跌撞撞,碰了不少壁,往往很多个教程才能拼凑出正确的步骤。所以决定自己写一份详细教程,也是怕自己忘了,以后使用PaddleOCR的时候也可以再翻出来看看。
PaddleOCR介绍 PaddleOCR是一个基于飞桨开发的OCR(Optical Character Recognition,光学字符识别)系统。其技术体系包括文字检测、文字识别、文本方向检测和图像处理等模块。以下是其优点:
高精度:PaddleOCR采用深度学习算法进行训练,可以在不同场景下实现高精度的文字检测和文字识别。
多语种支持:PaddleOCR支持多种语言的文字识别,包括中文、英文、日语、韩语等。同时,它还支持多种不同文字类型的识别,如手写字、印刷体、表格等。
高效性:PaddleOCR的训练和推理过程都采用了高效的并行计算方法,可大幅提高处理速度。同时,其轻量化设计也使得PaddleOCR能够在移动设备上进行部署,适用于各种场景的应用。
易用性:PaddleOCR提供了丰富的API接口和文档说明,用户可以快速进行模型集成和部署,实现自定义的OCR功能。同时,其开源代码也为用户提供了更好的灵活性和可扩展性。
鲁棒性:PaddleOCR采用了多种数据增强技术和模型融合策略,能够有效地应对图像噪声、光照变化等干扰因素,并提高模型的鲁棒性和稳定性。
总之,PaddleOCR具有高精度、高效性、易用性和鲁棒性等优点,为用户提供了一个强大的OCR解决方案。
下面将以行驶证为例,详细介绍PaddleOCR如何使用
一、PaddleOCR环境搭建 1.Anaconda安装 打开Anaconda官网,或者去清华镜像站下载。后者下载速度快,对应自己的电脑版本即可。
Free Download | AnacondaAnaconda's open-source Distribution is the easiest way to perform Python/R data science and machine learning on a single machine.
目录
运算符
运算符 图片来源Java基础07:基本运算符哔哩哔哩bilibili
package operator; public class Demo1 { public static void main(String[] args) { //二元运算符 //ctrl + d:复制当前行到下一行 int a = 10; int b = 20; int c = 25; int d = 25; System.out.println(a+b); System.out.println(a-b); System.out.println(a*b); System.out.println(a/(double)b); } } package operator; public class Demo2 { public static void main(String[] args) { long a = 123123123123123L; int b = 123; short c = 10; byte d = 8; System.
步骤 1. 新建一个游戏模式基础
命名为“GM_Lobby”
2. 新建一个玩家控制器,命名为“PC_Lobby”
3. 新建一个游戏状态基础
命名为“GS_Lobby”
重新设置游戏模式重载、玩家控制器类、游戏状态类
4. 新建一个控件蓝图,命名为“UMG_Lobby”
打开“UMG_Lobby”,添加如下控件:
5. 打开关卡“Lobby”
6. 打开关卡“Lobby”的关卡蓝图添加如下节点,将控件蓝图进行显示
此时运行可以看到控件蓝图已经可以正常显示:
7. 打开游戏模式“GM_Lobby”
新建一个数组,命名为“PC_List”,用于存放所有玩家控制器
在事件图表中添加如下节点,表示当有玩家加入时,就把它的玩家控制器加入数组“PC_List”
继续添加如下节点,当玩家登出时从数组“PC_List”中删除相应的玩家控制器。
8. 打开“UMG_MainMenu”,添加一个可编辑文本
设置可编辑文本的填充值、提示文本、字体尺寸等
9. 打开游戏实例“GI_Main”,添加一个文本类型的变量
10. 回到“UMG_MainMenu”,找到开始游戏的点击事件
在点击“开始游戏”按钮后,判断可编辑文本内容是否为空,如果为空就打印提示信息,否则就切换显示的控件,并设置游戏实例中的文本变量“PlayerName”的值。
11. 打开玩家控制器“PC_Lobby”,添加一个自定义事件,命名为“EVE_Spawn_Player”表示生成玩家的事件。
12. 打开第三人称角色模板蓝图“BP_ThirdPersonCharacter”,添加一个文本类型变量,命名为“PlayerName”
复制选择“RepNotify”,这样每当变量“PlayerName”发生变化时,就会调用函数“OnRep_PlayerName”
勾选可编辑实例、生成时公开
再添加一个字符串类型的变量,命名为“PlayerID” 勾选可编辑实例、生成时公开,复制选择“Replicated”
13. 回到玩家控制器“PC_Lobby”中,在自定义事件“EVE_Spawn_Player”的细节面板中,复制选择“在服务器上运行”,勾选可靠函数。
“EVE_Spawn_Player”逻辑如下,首先获取玩家出生点的transform,然后生成“BP_ThirdPersonCharacter”
“EVE_Spawn_Player”添加一个输入,命名为“PlayerName”
连接到“从类生成Actor”节点的引脚上
“PlayerID”就用时间表示
控制生成的Pawn
当事件开始运行时,获取游戏实例,转为我们自定的游戏实例后,获取存储的变量“PlayerName”作为“EVE_Spawn_Player”方法的参数的值
BUG解决方案 在使用ipopt和cppad进行优化求解时,发现对优化变量或者对优化变量所得的的变量进行开方时(使用math.sqrt)会发现程序崩溃,求解失败。我的猜想是 x \sqrt x x 的导数为 1 2 x \frac{1}{2\sqrt x} 2x 1,当x为0时,则会出现非法值。
故重点来了,解决方案为,强行把x为0的值变成一个很小的值,如:
if(x==0){ x=1e-10; } BUG求助 解决完这个问题,我还有一个关于ipopt的bug,解决了bug但是不知道是什么原因导致的bug,希望有大神看到可以指点一二。
Bug描述:
程序中对优化变量使用math.atan2(y,x),如果y为负数,则math.atan2(y,x)也为负数,对math.atan2(y,x)+2*M_PI转为正数后会求解失败,但是使用math.atan2(-y,x)返回正数时就不会求解失败,非常的玄学。
余既为此文,经年拟安装ROS2和T265驱动,后发现不少问题,遂重编,欢迎补充。
SDK2分为两种安装方法,这里只是Intel的翻译和个人安装记录总结。详细应该参看Intel realsenseSDK2的github仓库Release Intel® RealSense™ SDK 2.0 (v2.51.1) · IntelRealSense/librealsense · GitHub
软件说明 如果你只需要打开相机,不做ros开发,则只需要realsenseSDK2。
如果做ros2开发,则需要realsenseSDK2和ROS2 Wrapper for Intel® RealSense两个。
每一个软件都
具体分为APT安装和源码安装。
注意一点,realsense需要ubuntu内核Kernel处于指定版本,在后续安装中也需要对内核进行修改,请自行对Kelnel降级:
Ubuntu 20/22 (focal/jammy) with LTS kernel 5.13, 5.15 **
Ubuntu 14/16/18/20 with LTS kernel (< 5.13) Ubuntu with Kernel 4.16
关于T265环境版本问题 其中2023年7月7日发布的realsenseSDK2.54版本已经不支持T265,同时ROS2-realsense4.54.1版本也不再支持T265,而 ROS2-realsense4.51.1只支持到realsenseSDK2.51.1版本,所以如果要配置T265相机环境,需要realsenseSDK2.51.1和ROS2-realsense4.51.1两个指定版本,两者都需要源码安装
apt安装 realsenseSDK2apt安装 依次运行以下命令,注意realsense的key仓库地址改变过,所以请看清楚第一行的key安装地址,如果出现问题,需要及时的删除key和apt仓库地址。这种安装方法目前up只知道会安装最新版本,不知道如何指定版本
# 依次运行 sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-key F6E65AC044F831AC80A06380C8B3A55A6F3EFCDE || sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv-key F6E65AC044F831AC80A06380C8B3A55A6F3EFCDE #如果出现key添加失败就在/etc/apt/sources.list 和/etc/apt/sources.list.d里删除对应地址 sudo add-apt-repository "
起因 网上关于MongoDB的索引结构到底是b树,还是b+树的争论有很多,无法统一结论。
由来 MongoDB从3.2版本开始默认采用了WiredTiger存储引擎,网上很多说法是此引擎是B+Tree的索引结构,甚至有图有真相。但是认为MongoDB一直是B-Tree。所以争论不止!
结论 MongoDB是B-Tree !
有图有真相 更新 原以为是之前wiredtiger版本的问题,造成网上b+tree的截图,后面在最新版本也发现了b+tree的描述,我糊涂了~
分析可能是wiredtiger指导设计是b-tree,mongodb文档是按照wiredtiger指导文章来写的,但是具体后面的实现版本没有按照指导结构来,唯一的办法看样子只能去看源码了!
对于如何解决matolotlib中文显示异常的问题,部分教程给出如下方案:
import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 此方法大多数情况下在windows上运行良好,而在linux上不起作用。究其原因,是因为’SimHei’是windows上默认安装的字体,而Linux上没有该字体。此时,若想解决中文显示异常的问题,需要我们手动的安装可用的中文字体。
下载字体 下载支持中文的字体并安装,例如:
可以从github.com/adobe-fonts/source-fonts下载SourceHanSansSC-VF.ttf);也可以从身边的windows系统中拷贝可用的字体(“黑体”的默认路径为C:\Windows\Fonts\simhei.ttf) 在系统字体目录/usr/share/fonts/下新建文件夹(例如:myfontsdir),
cd /usr/share/fonts sudo mkdir myfontsdir 并将下载的字体文件放入其中
sudo cp ~/download/SourceHanSansSC-VF.ttf /usr/share/fonts/myfontsdir/SourceHanSansSC-VF.ttf ps:除了将字体文件放在系统字体文件夹下以外,还可以直接方法matplotlib专用的字体文件夹中,参考https://blog.csdn.net/u012915691/article/details/80616121
修改配置 确定matplotblib配置文件的位置:
>>> import matplotlib >>> matplotlib.matplotlib_fname() '/home/guozhi/miniconda3/envs/paddle_env/lib/python3.8/site-packages/matplotlib/mpl-data/matplotlibrc' 打开对应的配置文件(例如:/home/guozhi/miniconda3/envs/paddle_env/lib/python3.8/site-packages/matplotlib/mpl-data/matplotlibrc)
找到如下图两行,打开注释并添加下载好的字体(例如:SourceHanSansSC-VF)
其它常见问题记录↓ 问题:最近发现使用matplotlib绘图时,当坐标轴标签数字过大时会自动使用科学计数法显示。关于如何恢复原始数字显示,很多博客中给出的方法都是将标签数字转换成文本来显示,个人不是觉得转文本的方式略显粗暴。
经过一番搜索,在网上找到了这个设置标签style来取消自动科学计数的方法:
ax.ticklabel_format(style='plain') 很实用,也符合我个人的代码审美,在此记录一下
题目来自 Golang vs. Rust: Which Programming Language To Choose in 2023?[1]
141. Iterate in sequence over two lists Iterate in sequence over the elements of the list items1 then items2. For each iteration print the element.
依次迭代两个列表 依次迭代列表项1和项2的元素。每次迭代打印元素。
package main
import (
"fmt"
)
func main() {
items1 := []string{"a", "b", "c"}
items2 := []string{"A", "B", "C"}
for _, v := range items1 {
fmt.Println(v)
}
for _, v := range items2 {
部署MySQL wget https://dev.mysql.com/get/mysql-apt-config_0.8.1-1_all.deb dpkg -i mysql-apt-config_0.8.1-1_all.deb 安装:
Sudo apt-get install mysql-server -y 重启:
Sudo service mysql restart 创建新用户:这里的密码是踩坑之一
mysql>create user 'user'@'127.0.0.1' identified by '*passwd'; 授权:
mysql>grant all on *.* to 'user'@'127.0.0.1'; 本地授权 mysql>grant all on *.* to 'user'@'远程IP'; 远程授权 刷新:
mysql>flush privileges; 问题记录 1:创建用户的时候密码不能以特殊字符开头,现在需要更改密码
MySQL8.0更改密码,注意 这两条命令已经不起作用了
mysql>update mysql.user set password='newpassword' where user='root'; 和 mysql>update mysql.user set password=PASSWORD('newpassword') where User='root'; 现在的版本用的是:
mysql>alter user 'user'@'127.0.0.1' identified by 'passwd'; 2:更改完密码之后远程连接连不上了
2.1更改完密码的用户需要重新授权
授权: mysql>grant all on *.
先看C知道怎么说:
要设置 Docker 容器中的端口不被暴露,可以使用 -p 或 --publish 选项来控制端口的映射。标准的 -p 选项语法是 <host-port>:<container-port>,其中 <host-port> 是你希望将容器端口映射到的主机上的端口号,而 <container-port> 是容器内部的端口号。 如果你想要在运行容器时不将某个端口暴露到主机上,可以将 <host-port> 部分留空或设置为 0,如下所示: docker run -p 0:<container-port> <image-name> 这样会随机分配一个未使用的主机端口给容器内部的 <container-port>。 另外,你还可以使用 --publish-all 或 -P 选项来完全禁用端口映射,并将容器内部的所有端口都随机分配给主机上的端口。 请注意,即使端口没有被映射到主机上,容器内部的进程仍然可以通过容器内部的 IP 地址和端口访问。 很遗憾之前起的时候没有这么弄,现在该怎么做呢?
怎么设置docker监听的端口外网访问不了?
cat /etc/docker/damon.json { "graph":"/docker_images/docker" "iptables":false } 在这个问价中添加:“iptables”:false字段,添加后重启一下docker服务
问题:没有nmap就安装一下
nmap IP starting Nmap 7.01 ( https://nmap.org ) at 2023-07-26 15:47 CsT Nmapscan report for IP Hostis up(0. 043s atency)Not shown:945 filtered ports PORT STATE SERVICE 19/tcp open chargen 80/tcp open http 981/tcp open unknown .
报错信息及解决7: 报错信息详情:error LNK2001: 无法解析的外部符号“symbol”
原因:编译后的代码引用或调用符号。 该符号未在链接器搜索的任何库或对象文件中定义。
什么是未解析的外部符号?
“符号”是函数或全局变量的内部名称。 它是在已编译的对象文件或库中使用或定义的名称形式。 全局变量在为其分配了存储的对象文件中进行定义。 函数在放置函数体的已编译代码的对象文件中进行定义。 “外部符号”是在一个对象文件中引用,但在不同的库或对象文件中定义的符号。 “导出的符号”是由定义它的对象文件或库公开提供的符号。 若要创建应用程序或 DLL,使用的每个符号都必须有一个定义。 链接器必须解析或查找每个对象文件引用的每个外部符号的匹配定义。 链接器在无法解析外部符号时生成错误。 这意味着链接器在任何链接文件中都找不到匹配的导出符号的定义。
解决办法:在cpp文件Include后添加 #pragma comment(lib,"XXXX.lib")
ws2_32.lib error LNK2001: 无法解析的外部符号 __imp_htons error LNK2001: 无法解析的外部符号 __imp_ntohl error LNK2001: 无法解析的外部符号 __imp_ntohs error LNK2019: 无法解析的外部符号 in6addr_any error LNK2001: 无法解析的外部符号 __imp_htonl error LNK2019: 无法解析的外部符号 in6addr_loopback d3d11.lib error LNK2019: 无法解析的外部符号 D3D11CreateDevice winmm.lib error LNK2019: 无法解析的外部符号 __imp_timeKillEvent error LNK2019: 无法解析的外部符号 __imp_timeBeginPeriod error LNK2019: 无法解析的外部符号 __imp_timeEndPeriod error LNK2019: 无法解析的外部符号 __imp_timeSetEvent error LNK2019: 无法解析的外部符号 __imp_timeGetTime crypt32.
继承是面向对象编程中的一种重要概念,它允许一个类(称为子类或派生类)从另一个类(称为父类或基类)继承属性和方法。通过继承,子类可以获得父类的特性,并且可以添加自己特定的特性,形成类之间的层次关系。 2.1.4 Java继承语法
在Java语言中,继承是通过使用关键字"extends"实现的。继承的语法结构为:子类名 extends 父类名。通过继承,子类可以继承父类的成员变量和成员方法,并且可以添加自己特定的成员变量和成员方法。
需要注意的是,Java语言不支持多重继承,一个类只能继承一个父类,但一个父类可以有多个子类。
继承的特性包括:
单继承:Java不支持类的多继承,这意味着一个类只能有一个超类(父类),但一个超类可以有多个子类。这种单一继承的特性保证了类之间的层次结构清晰明确。传递性:子类不仅可以继承直接父类的属性和方法,还可以继承父类所继承的其他父类的属性和方法。这种传递性的特性使得类的继承关系形成了一个层次结构,子类可以逐级继承父类的特性,使代码的复用更加灵活和高效。 2.2 继承中的构造器 2.2.1 重用构造器
在上述案例中,我们使用继承将共享的属性和方法抽取到了父类Person中。然而,我们也注意到子类的构造器中出现了重复的冗余代码,即对父类属性的初始化。
Java中的构造器是不能被继承的,子类不能直接继承父类的构造器。但是,Java提供了一种机制让子类能够调用父类的构造器,从而解决这个问题。
子类可以使用关键字super调用父类的构造器。通过调用父类的构造器,可以将公共属性的初始化代码抽取到父类中,然后子类只需调用父类的构造器,而不需要再重复初始化父类的属性。
2.2.2【案例】重用构造器示例
下面是一个修改后的案例示例:
class Person{String name;int age;char gender;public Person(String name, int age,char gender){this.name = name;this.age = age;this.gender = gender;}}class Student extends Person {double score;public Student(String name, int age, char gender, double score) {super(name, age, gender); // 调用父类的构造器this.score = score;}}class Teacher extends Person {double salary;public Teacher(String name, int age, char gender, double salary) {super(name, age, gender); // 调用父类的构造器this.
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、接口常遇见的bug和问题
传入不合规参数,导致程序crash;
数据类型溢出,导致数据读出和写入不一致;
因对象权限未进行校验,可以访问其他用户敏感信息;
状态处理不当,导致逻辑出现错乱;
逻辑校验不完善,可以利用漏洞获取非法利益;
2、测试用例设计
输入- 接口处理逻辑 – 输出-
一个接口通常有输入,输出,有时候输出也是没有的,
用例设计考虑,输入, 输出
针对输入,可以按照参数类型设计;
针对处理,可以按照逻辑进行用例设计;
针对输出,可根据结果进行分析设计;
详情:
针对输入设计:
数值型:
等价类:取值范围内,取值范围外
边界法:取值范围边界:边界最大,最小;边界最小-1,最大+1等
特殊值:0,负值等
遍历法:取值范围的所有数值遍历
举例:一个输入值的范围是int 1-12,需要考虑范围内的值;边界值0,1,12,13;类型的特殊值-1,0;还有int的最小,最大边界值也需要考虑; 如果1-12有指定含义代表,还需要遍历所有数值
风险:特殊值,边界值处理不当,程序退出,数据溢出,返回错误信息等
Int: 数据类型边界:-2147483648 ,2147483648。 (Integer.MAX_VALUE)
字符串型:
字符串长度:
等价法:取值范围内,取值范围外
边界法:规定范围边界,类型边界
特殊值:0,即空字符
字符串内容:
特定类型:英文,中文,大小写等
特殊字符:>,<*!@#$%等
敏感字符:“flg”“TMD""等
举例:接口的功能字符串长度为3位,测试长度:3位,比3多,比3少;
String的最大长度;特殊的空字符;字符串内容是数字,非数字等;特殊字符;是否需要过滤敏感字符;
风险:传入其他类型,超长字符,敏感字等,程序是否异常退出,是否显示,存储有问题,时候特殊处理敏感字
数组或链表类型:
成员个数:
等价法:取值范围内,取值范围外
边界法:规定范围边界,个数边界值
特殊值:0等
成员内容:
等价类:合法和非法成员
重复法:重复的成员
举例:接口接受的数组取值长度一般是5个,取值1-5个内,范围外6个
边界值,请求允许的最大,最小值;特殊值,0个;内容的合法,不合法;重复的内容是否可以
风险:0个是是否异常退出,重复的内容是否允许
针对逻辑设计
约束条件分析:
数值限制:分数限制,金币限制,等级限制等(满足条件才可以执行)
状态限制:需要先登录等(同步信息等)
关系限制:绑定的关系,好友关系等
权限限制:管理员等
风险:约束条件判断不足,用户可以特殊手段获利等
操作对象分析:
操作通常是针对对象的,针对合法和不合法对象进行操作,后台处理会如何
风险:用户可以非权限的操作
状态转换分析:
简介 基于doris官方用doris构建实时仓库的思路,从flinkcdc到doris实时数仓的实践。
原文 Apache Flink X Apache Doris 构建极速易用的实时数仓架构 (qq.com)
前提-Flink CDC 原理、实践和优化 CDC 是什么 CDC 是变更数据捕获(Change Data Capture)技术的缩写,它可以将源数据库(Source)的增量变动记录,同步到一个或多个数据目的(Sink)。在同步过程中,还可以对数据进行一定的处理,例如分组(GROUP BY)、多表的关联(JOIN)等。
例如对于电商平台,用户的订单会实时写入到某个源数据库;A 部门需要将每分钟的实时数据简单聚合处理后保存到 Redis 中以供查询,B 部门需要将当天的数据暂存到 Elasticsearch 一份来做报表展示,C 部门也需要一份数据到 ClickHouse 做实时数仓。随着时间的推移,后续 D 部门、E 部门也会有数据分析的需求,这种场景下,传统的拷贝分发多个副本方法很不灵活,而 CDC 可以实现一份变动记录,实时处理并投递到多个目的地。
下图是一个示例,通过腾讯云 Oceanus 提供的 Flink CDC 引擎,可以将某个 MySQL 的数据库表的变动记录,实时同步到下游的 Redis、Elasticsearch、ClickHouse 等多个接收端。这样大家可以各自分析自己的数据集,互不影响,同时又和上游数据保持实时的同步。
CDC 的实现原理 通常来讲,CDC 分为主动查询和事件接收两种技术实现模式。
对于主动查询而言,用户通常会在数据源表的某个字段中,保存上次更新的时间戳或版本号等信息,然后下游通过不断的查询和与上次的记录做对比,来确定数据是否有变动,是否需要同步。这种方式优点是不涉及数据库底层特性,实现比较通用;缺点是要对业务表做改造,且实时性不高,不能确保跟踪到所有的变更记录,且持续的频繁查询对数据库的压力较大。
事件接收模式可以通过触发器(Trigger)或者日志(例如 Transaction log、Binary log、Write-ahead log 等)来实现。当数据源表发生变动时,会通过附加在表上的触发器或者 binlog 等途径,将操作记录下来。下游可以通过数据库底层的协议,订阅并消费这些事件,然后对数据库变动记录做重放,从而实现同步。这种方式的优点是实时性高,可以精确捕捉上游的各种变动;缺点是部署数据库的事件接收和解析器(例如 Debezium、Canal 等),有一定的学习和运维成本,对一些冷门的数据库支持不够。
综合来看,事件接收模式整体在实时性、吞吐量方面占优,如果数据源是 MySQL、PostgreSQL、MongoDB 等常见的数据库实现,建议使用 Debezium 来实现变更数据的捕获(下图来自 Debezium 官方文档)。如果使用的只有 MySQL,则还可以用 Canal。
查看MySQL用户名的方法(查看mysql的用户名) MySQL是一个最流行的关系型数据库,它可能是开发Web应用程序和其他网络应用程序最常使用的数据库之一。一旦用户创建在MySQL中的登录详细信息,他们就需要查看MySQL用户名以便正确凭据登录到database。那么,有什么方法可以查看MySQL用户名呢?
## 1.MySQL 命令
在MySQL响应窗口下, 我们可以使用以下命令来查看MySQL用户名:
`SELECT User FROM mysql.user;`
上述命令将显示当前数据库服务器中存在的所有MySQL用户名。
## 2.MySQL管理工具
上述命令也可以通过MySQL管理工具来执行。这些MySQL管理工具,例如phpMyAdmin,HeidiSQL等,都可以查看用户名。
一些管理工具允许用户在“MySQL Users”选项卡中查看MySQL用户名。例如,使用phpMyAdmin,可以在“MySQL Users”窗格中查看MySQL用户名,如下图所示:

## 3.MySQL SQL语句
此外,MySQL users also can use the SQL statement to view the username. 下面是一个查看MySQL用户名的示例SQL语句:
`SELECT user_name FROM mysql.user;`
## 总结
通过本文,我们已经掌握了如何通过MySQL命令,MySQL管理工具和MySQL SQL语句来查看MySQL用户名的方法。这样,用户就可以更加轻松地与MySQL数据库进行交互,并获取更多信息。查看MySQL用户名的方法(查看mysql的用户名)-数据库远程运维
前言
作者简介:不知名白帽,网络安全学习者。
博客主页:不知名白帽_网络安全,CTF,内网渗透-CSDN博客
网络安全交流社区:https://bbs.csdn.net/forums/angluoanquan
目录
逻辑漏洞基础
概述
分类
URL跳转漏洞
概述
危害
漏洞寻找
Bypass
短信轰炸漏洞
概述
Bypass
任意密码修改漏洞
概述
场景
任意用户登录漏洞
概述
场景
越权漏洞
概述
平行越权
垂直越权
支付逻辑漏洞
概述
场景
条件竞争漏洞
概述
场景
实战
大米cms支付逻辑漏洞
熊海CMS越权后台登录
逻辑漏洞基础 概述 逻辑漏洞,是因为程序员在编写程序的时候,跟随着人的思维逻辑产生的不足,与传统漏洞的不同在于,逻辑漏洞是用过合法的方式来达到破坏的,比如密码找回,用户登录验证等功能由于程序设计的不足会产生很多问题,这一类漏洞一般的防护手段或者设备无法阻止,漏洞扫描器也难以发现。
程序逻辑不严或逻辑太复杂,导致一些逻辑分支不能够正常处理或处理错误,一般出现在任意密码修改(没有旧密码验证)、越权访问、密码找回、交易支付金额、身份证认证、实名认证......等。
分类 url跳转漏洞
短信轰炸
任意密码修改漏洞
任意用户登录漏洞
越权漏洞
支付逻辑漏洞
条件竞争漏洞
URL跳转漏洞 概述 URL跳转漏洞也叫开放重定向漏洞,就是可以把用户重定向刀攻击者自己构造的页面去,简单的说就是可以跳转到指定的URL。
服务端未对传入的URL变量进行检查和控制,可能导致可恶意构造任意一个恶意地址,诱导用户跳转恶意网站。
危害 钓鱼
配合xss漏洞
配合csrf漏洞
配合浏览器漏洞(CVE-2018-8174)
漏洞寻找 1.登陆跳转我认为是最常见的跳转类型,认证完后会跳转,所以在登陆的时候建议多观察url参数。
2.用户分享、收藏内容过后,会跳转
3.跨站点认证、授权后,会跳转
4.站内点击其它网址链接时,会跳转
5.在一些用户交互页面也会出现跳转,如请填写对客服评价,评价成功跳转主页,填写问卷,等等业务,注意观察url。
6.业务完成后跳转这可以归结为一类跳转,比如修改密码,修改完成后跳转登陆页面,绑定银行卡,绑定成功后返回银行卡充值等页面,或者说给定一个链接办理VIP,但是你需要认证身份才能访问这个业务,这个时候通常会给定一个链接,认证之后跳转到刚刚要办理VIP的页面。
Bypass 1.利用问号绕过限制
url=https://www.baidu.com?www.xxxx.me
2.利用@绕过限制
url=https://www.baidu.com@www.xxxx.me
3.利用斜杠反斜杠绕过限制
XML基础 概述 XML是一种用于标记电子文件使其具有结构性的可扩展标记语言。
XML是一种灵活的语言,类似于HTML语言,但是并没有固定的标签,所有标签都可以自定义,其设计的宗旨是传输数据,而不是像HTML一样显示数据。
文档结构 XML声明
DTD文档类型定义
文档元素
CDATA表示包含字符或者文本数据,这些文本将被解析器检查实体以及标记。被解析的字符数据不应当包含任意&、<、>;需要使用它们的实体来替换
< < 小于
> > 大于
& & 和号
' · 省略号
" “ 引号
DTD基础 概述 DTD即文档类型定义,用来为XML文档定义语义约束
我们可以把DTD理解为一个模板,这个模板中定义了用户自己创建的根元素以及对应的子元素和根元素的合法子元素和属性
文档元素则必须以我们的DTD为模板,来对XML的元素的内容进行相应的规范化
DTD声明 内部声明
<!DOCTYPE 根元素 [元素声明]>
外部声明
<!DOCTYPE 根元素 SYSTEM “文件名/URL”>
DTD实体 内部普通实体
<!ENTITY 实体名称 “实体的值”>
外部普通实体
<!ENTITY 实体名称 SYSTEM “URI”>
<!TINTITY 实体名称 PUBLIC “DTD标识名” “公用DTD的URI”>
PUBLIC指公用DTD,其是某个权威机构指定,供特定行业或公司
SYSTEM是指该外部DYD文件是私有的,即我们自己创建的,没有公开发行,只是个人或在公司内部或者几个合作单位之间使用
公用DTD使用PUBLIC代替了原来的SYSTEM,并增加了DTD标识名
参数实体
内部 <!ENTITY % 实体名称 “实体值”>
外部 <!ENTITY % 实体名称 SYSTEM “URI”>
aws 无账号下载资源到本地 命令:aws s3 cp --no-sign-request --recursive s3://<src-key> <dest-local>
参数:cp 表示复制, src-key 表示s3上的key(路径),<dest-local>是本地文件夹路径, --recursive 表示路径下全部内容都下载,下载单个文件时需去掉该参数
下载某个tif文件到当前目录:aws s3 cp --no-sign-request s3://azavea-research-public-data/raster-vision/examples/tutorials-data/top_potsdam_2_10_RGBIR.tif ./递归下载目标目录下的所有文件到指定目录:aws s3 cp --no-sign-request --recursive s3://azavea-research-public-data/raster-vision/examples/tutorials-data/ ./data aws 无账号下查看目录下文件列表 aws s3 ls s3://<src-key>/ --no-sign-request --recursive
ls 表示列出文件列表, src-key 表示s3上的key(目录路径), --recursive 表示迭代查看目录下的文件及子目录文件
2023.7.26今天我学习了如何使用树形表格的时候进行复选框的多选效果。
当我们使用树形结构表格需要进行多选功能操作的时候会发现点击全选的时候,只有一级表格数据会被选中,问题如图:
我们需要实现的是点击全选的不管是几级表格数据都可以被选中。
处理方法如下:
html代码如下:
<el-table :data="typeList" :key="curryId" row-key="id" :tree-props="{children: 'children', hasChildren: 'hasChildren'}" ref="table" @selection-change="selection_all_operation_record" @select-all="handleSelectAll" > </el-table> js代码如下:
methods:{ handleSelectAll() { for (let item of this.typeList) { this.selectChildren(item) } }, selectChildren(item) { if (item.children != null) { for (let childItem of item.children) { this.selectChildren(childItem) this.$refs.table.toggleRowSelection(childItem) } } }, } 通过递归的方式来给每一层数据都可以被选中。
效果如下:
目录
1、设置窗口大小
2、选择字体
3、输出结果
1、设置窗口大小 setFixedSize(800,600); ui->setupUi(this); ui->pushButton->setFixedSize(250,50); ui->plainTextEdit->setFixedSize(300,300); 2、选择字体 bool ok; QFont inifont=ui->plainTextEdit->font();//获取原有的字体 QFont font=QFontDialog::getFont(&ok,font);//获得选择后的字体 if (ok){ ui->plainTextEdit->setFont(font); } 3、输出结果 总结:
1、选择字体对话框使用,参考帮助立越l
2、getFont生成选择字体对话框,返回值不能判断有效,一般是根据getFont的第一个参数逻辑变量是否为ture。
一、使用vite 构建 electron项目 npm init vite@latest Need to install the following packages: create-vite@latest Ok to proceed? (y) y √ Project name: ... CertificateDownload √ Package name: ... certificatedownload √ Select a framework: » Vue √ Select a variant: » TypeScript Scaffolding project in E:\electron\CertificateDownload... Done. Now run: cd CertificateDownload npm install npm run dev 按说明输入如下命令
cd CertificateDownload
npm install
npm run dev
VITE v4.4.6 ready in 565 ms ➜ Local: http://127.
今天给大家分享一个有意思的小案例。事情是这样的,客户那边有个等保要求,需要对数据库做一个备份,那做备份,肯定是要看看空间使用情况如何呀,然后我就人麻了QAQ…
它卡住了!一动不动的!甚至会话也被迫掐断!因为动不了!你洞洞我试试!
下面开始排查原因~
一、先通过starce命令跟踪df命令查看在哪里hang住了
strace df -hP 输出信息最后一行如下:
statfs("/var/lib/nfs/rpc_pipefs", {f_type=0x67596969, f_bsize=4096, f_blocks=0, f_bfree=0, f_bavail=0, f_files=0, f_ffree=0, f_fsid={0, 0}, f_namelen=255, f_frsize=4096}) = 0 statfs("/data/backup",... 到了这里之后就发现无法继续跟踪了,可以确定是nfs挂载点异常导致的无法跟踪,后来排查发现是NFS源端撤掉了导致异常。
二、解决流程
通过/etc/mtab文件进行nfs盘处理,该文件记载的是现在系统已经装载的文件系统,包括操作系统建立的虚拟文件等;而/etc/fstab是系统准备装载的。直接使用mount和确定就是通过查询它而来的。
处理方法,注释掉该nfs,然后df -h命令就可以使用了
vim /etc/mtab #10.100.0.233:/Data15/record /record nfs rw,vers=4,addr=10.100.0.233,clientaddr=10.100.0.236 0 0 然后强制卸载
umount -l /data/backup 然后就可以正常查询啦~!
目录
Java数据类型转换
代码实例1
代码实例2
Java数据类型转换 运算中,不同类型的数据先转化
代码实例1 public class demo3 { public static void main(String[] args) { int i = 128; byte b = (byte)i;//内存溢出 double c = i; //强制转换 (类型)变量名 高--低 //强制转换 (类型)变量名 低到高 System.out.println(i); System.out.println(b); /* //注意点 1.不能对到布尔值进行转换 2.不能把对象类型转换为不相干的类型 3.在把高容量转换到低容量的时候,强制转换 4,转换的时侯可能在内存溢出,或者精度问题 */ System.out.println("========================== "); System.out.println((int) 23.7);//23 System.out.println((int) -45.89f);//-45 System.out.println("========================== "); char C = 'a'; int d = C+1; System.out.println(d); System.out.println((char)d); } } 运行结果
ClickHouse系列文章 1、ClickHouse介绍
2、clickhouse安装与简单验证(centos)
3、ClickHouse表引擎-MergeTree引擎
4、clickhouse的Log系列表引擎、外部集成表引擎和其他特殊的表引擎介绍及使用
5、ClickHouse查看数据库容量、表的指标、表分区、数据大小等
文章目录 ClickHouse系列文章一、查看数据库容量二、查看表的各个指标三、查看表分区四、跟踪分区五、检查数据大小六、查看表中列的数据大小 本文主要介绍ClickHouse查看数据库容量、表的指标、表分区、数据大小等,每种都有具体的使用示例。
本文使用前提参考该系列文章中的部署与验证。
本文主要分为六部分,即查看数据库容量、查看表的各个指标查看表分区、跟踪分区、检查数据大小和查看表中列的数据大小。
Clickhouse是一个高性能且开源的数据库管理系统,主要用于在线分析处理(OLAP)业务。它采用列式存储结构,可使用SQL语句实时生成数据分析报告,另外它还支持索引,分布式查询以及近似计算等特性,凭借其优异的表现,ClickHouse在各大互联网公司均有广泛地应用。
官网:https://clickhouse.com/
中文官网:https://clickhouse.com/docs/zh
clickhouse有system.parts系统表记录表相关元数据,可以通过该表对clickhouse上所有表进行查询表大小、行数等操作。
一、查看数据库容量 select sum(rows) as row,--总行数 formatReadableSize(sum(data_uncompressed_bytes)) as ysq,--原始大小 formatReadableSize(sum(data_compressed_bytes)) as ysh,--压缩大小 round(sum(data_compressed_bytes) / sum(data_uncompressed_bytes) * 100, 0) ys_rate--压缩率 from system.parts 二、查看表的各个指标 select database, table, sum(bytes) as size, sum(rows) as rows, min(min_date) as min_date, max(max_date) as max_date, sum(bytes_on_disk) as bytes_on_disk, sum(data_uncompressed_bytes) as data_uncompressed_bytes, sum(data_compressed_bytes) as data_compressed_bytes, (data_compressed_bytes / data_uncompressed_bytes) * 100 as compress_rate, max_date - min_date as days, size / (max_date - min_date) as avgDaySize from system.
出现报错:
TypeError: can't convert np.ndarray of type numpy.object_. The only supported types are: float64, float32, float16, int64, int32, int16, int8, uint8, and bool.
原因:
读入的numpy数组里的元素是object类型,无法将这种类型转换成tensor。
解决:
将numpy数组进行强制类型转换成float类型(或者任何pytorch支持的类型:float64, float32, float16, int64, int32, int16, int8, uint8, and bool)
.astype(float)
可以正常运行!
文章目录 一、GPU和CPU的区别GPU: 高吞吐量导向设计CPU: 低延迟导向设计GPU适合什么场景:什么是Prefetch? 二、CUDA与OpenCL三、CUDA编程并行计算整体流程内存模型线程块网格Grid:并行线程块组合线程束SIMD 四、CUDA编程实例:向量相加CUDA 编译流程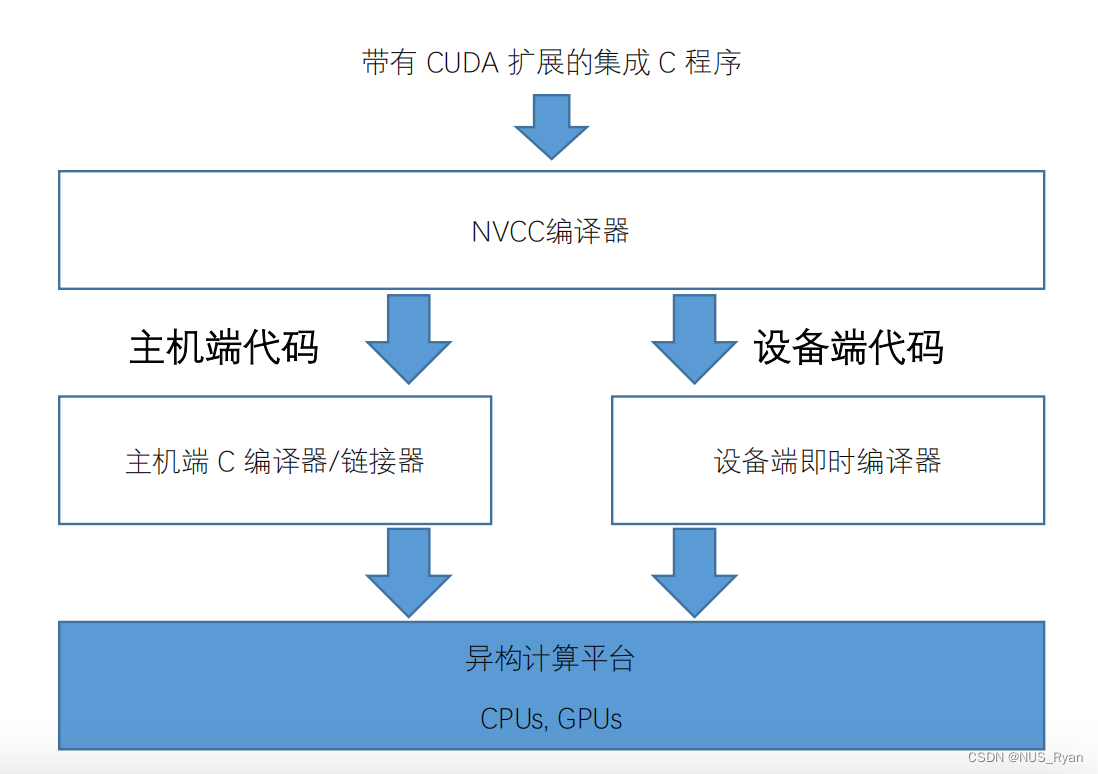 五. 代码实例 一、GPU和CPU的区别 GPU: 高吞吐量导向设计 缓存少: 提高内存吞吐控制简单: 没有分支预测机制和数据转发机制,但是同样存在Prefetch机制。运算单元精简: 长延时流水线来实现高吞吐量,需要大量线程来容忍延迟。适合场景: 并行计算占比多,吞吐优先,GPU单位时间执行指令数大大超过CPU CPU: 低延迟导向设计 大内存,多分级缓存。多级缓存结构提高缓存速度。控制复杂: 具备分支预测机制和流水线Prefetch机制,加速数据读取。运算单元强大: CPU对复杂的整型和浮点型的运算速度支持较好,速度快。适合场景: 连续计算部分,对时延要求高,对单条复杂指令延迟远远低于GPU GPU适合什么场景: 计算密集,当数值计算的比例远远高于内存操作时; 数据并行,当一个大任务可以拆分成若干个小任务时,因此对复杂流程控制的需求较低
什么是Prefetch? 预取是一种内存管理策略,旨在减少内存访问延迟,从而提高计算性能。预取机制通过预先加载数据到高速缓存(例如,从全局内存到共享内存或纹理内存)来实现这一目标,以便在执行计算任务时减少等待时间。
GPU的预取机制有两种形式:
硬件预取:这是由GPU硬件自动实现的预取机制,不需要程序员进行显式操作。GPU内部的内存控制器会预测内存访问模式,提前将可能需要的数据加载到高速缓存中。这种预取机制在许多现代GPU架构(如NVIDIA的Pascal、Volta和Ampere架构)中都有实现。
软件预取:程序员可以通过编写代码显式地实现预取,以便更好地控制数据加载的过程。在CUDA编程中,可以使用__builtin_prefetch()函数来实现软件预取,该函数将根据程序员的指示将数据加载到L1或L2高速缓存中。软件预取的好处是程序员可以根据任务的特点精确地控制预取行为,从而进一步提高性能。
实际上,预取机制是一种平衡延迟和吞吐量的策略,旨在最大限度地提高GPU的计算效率。需要注意的是,预取机制在不同的GPU架构和设备上可能有所差异。因此,在优化GPU代码时,需要充分了解目标硬件的特性。
二、CUDA与OpenCL CUDA(Compute Unified Device Architecture)和OpenCL(Open Computing Language)是用于加速计算的并行计算框架。
CUDA是由英伟达公司开发的框架,支持在NVIDIA的GPU上运行。CUDA提供了一组库和工具,可让开发人员使用C、C++和Fortran等编程语言来编写GPU加速的应用程序。CUDA的优点是它的性能非常高,而且支持广泛的NVIDIA GPU硬件,这使得它成为开发GPU加速应用程序的首选框架之一。
OpenCL是一个由多家公司共同开发的框架,可以在支持OpenCL的GPU、CPU和其他处理器上运行。OpenCL的优点是它是一个跨平台的框架,这意味着可以在不同的硬件和操作系统上运行。OpenCL还支持多种编程语言,包括C、C++、Java和Python等。
虽然CUDA和OpenCL都是用于加速计算的框架,但它们有一些不同之处。CUDA主要用于NVIDIA GPU上的计算,而OpenCL则可以在不同的硬件上运行。此外,CUDA的编程模型比较简单,而OpenCL则更加灵活。选择哪种框架取决于具体的应用场景和硬件设备。
三、CUDA编程并行计算整体流程 假设有这么一个GPU Kernel Function:
void GPUKernel(float *A,float *B,float *C,int n){} 其流程可以分为下面几个步骤: 1. Allocate GPU memory for A and B and C. 2. Copy A, B to GPU memory.
docker 一、docker compose的理论二、docker-compose工具实验创建apache容器创建LNMP 一、docker compose的理论 docker compose简而言之就是实现单机容器集群编排管理(使用一个模板文件定义多个应用容器的启动参数和依赖关系,并使用docker compose来根据这个模板文件的配置来启动容器)
三大概念:
项目/工程 > 包含一个或多个服务 > 包含一个或多个容器
默认使用项目的目录名做项目名,支持使用-p或者–project-name来指定项目名
在项目的目录中通常会包含一个docker-compose.yml模板文件,此文件为项目的默认配置模板文件(支持使用-f或compose_file来指定项目的 配置文件)
在配置模板文件里面可以定义项目的一个或者多个服务,每个服务包含容器的名称、镜像、端口映射、环境变量、挂载点、依赖关系登配置参数
Docker Compose 是 Docker 的独立产品,因此需要安装 Docker 之后在单独安装 Docker Compose #下载 curl -L https://github.com/docker/compose/releases/download/1.21.1/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose #安装 chmod +x /usr/local/bin/docker-compose #查看版本 docker-compose --version 2. YAML 文件格式及编写注意事项 YAML 是一种标记语言,它可以很直观的展示数据序列化格式,可读性高。类似于 json 数据描述语言,语法比 json 简单的很多。YAML 数据结构通过缩进来表示,连续的项目通过减号来表示,键值对用冒号分隔,数组用中括号 [] 括起来, hash 用花括号 {} 括起来。 使用 YAML 时需要注意下面事项: ●大小写敏感 ●通过缩进表示层级关系 ●不支持制表符 tab 键缩进,只能使用空格缩进 ●缩进的空格数目不重要,只要相同层级左对齐,通常开头缩进2个空格 ●用 # 号注释 ●符号字符后缩进1个空格,如冒号 : 、逗号 , 、横杠 - ●如果包含特殊字符用单引号('')引起来会作为普通字符串处理,双引号("
前言:本文为手把手教学智能车载终端项目(Linux+QT),该项目是综合性非常强的 Linux 系列项目!项目核心板使用 NXP 的 IMX6ULL 作为 CPU,整体实现了简化版本的车载终端功能需求。项目可以学习的点非常多,包含:IMX6ULL 的硬件驱动,QT 的移植与 Linux 多进程操作等。该项目的源代码适用于正点原子的出厂镜像,只学习应用层开发的也可以尝试学习该项目!希望该篇博客可以给诸位些许收获,博客篇尾代码开源!
硬件实物图:
效果图:
考虑到该项目整体流程过于复杂化,作者将重点侧重软件即 Linux+QT 的框架实现!该项目的好处是:源代码可以直接在正点原子 IMX6ULL 开发板上使用!如果只学习应用层开发的读者朋友可以直接用正点原子的出厂镜像即可!
一、智能车载终端概述 智能车载终端是一种用于对运输车辆进行现代化管理的设备。它融合了 GPS 技术、里程定位技术以及汽车黑匣技术,可以用于多种用途,包括 DVR 行车记录仪、智能车载后视镜、网约车运营终端、两客一危车队管理终端等。智能车载终端开始普及,使得汽车行业进入智能化加速阶段。相较于传统终端产品,智能车载终端能够减少平台许可费用、减少研发费用、缩短研发与生产时间、覆盖终端知识产权、快速产品规划。智能车载终端往往需要覆盖大量商用车辆,企业对性价比存在一定需求,而智能模组产品能够助力企业快速进行产品迭代,实现更高效地研发。
随着科技与电车技术发展,智能车载终端的功能和要求越来越复杂化和高级化。作者博客篇幅有限,所以这次仅给诸位读者教学简单的 3 个功能的实现和功能切换方法! 1.1 车载终端:影音播放器 目前汽车终端上,车主使用最多的应该还是音频类设备。比如:收音机、电台、音乐播放器、听书等等。所以,车载终端上必须使用成功驱动音频类芯片(I2S等)。该音频设备无论是借助第 3 方音乐播放器还是自主设计一款音乐播放器,都是在车载终端上必不可少的!
1.2 车载终端:地图功能 车载终端上的地图功能同样是不可或缺的,车主往往需要进行地图导航(手机导航可能用得更多,但是功能你必须要有)。地图导航依赖的功能实现就比较复杂,需要驱动 GPS 等,同时,根据 GPS 等信息结合地图软件进行定位导航!
1.3 车载终端:倒车影像 如自动驾驶一般,科技的进步往往是降低人类的驾驶难度。倒车入库等操作属于有难度的驾驶技术,结合现代科技的倒车影像等技术。可以方便车主快速完成操作,享受愉快生活!
1.4 车载终端:杂项功能 车载终端是一个非常复杂且常用的装置,随着电车与自动驾驶技术的不断升级迭代,需求也与日俱增!我们往往需要在终端上附加许许多多其他的功能,比如:智能家居联动、车内环境监测、天气预报与网上浏览等!
二、IMX6ULL车载项目的驱动 作者强调:考虑到篇幅有限,作者本篇博客仅进行部分功能实现教学,并侧重应用层的实现!基础薄弱的朋友,可以直接使用正点原子出厂的镜像程序进行项目复现!
2.1 音频设备驱动 音频 CODEC 支持 I2S 协议,那么主控制器也必须支持 I2S 协议,I.MX6ULL 也提供了一个叫做 SAI 的外设,全称为 SynchronousAudio Interface,翻译过来就是同步音频接口。
I.MX6ULL 的 SAI 是一个全双工、支持帧同步的串行接口,支持I2S、AC97、TDM和音频DSP。
正点原子 ALPHA 开发板音频原理图如图所示:
地图叠加等值面效果,绘制掩体模型 地震闪动特效
地震热力图效果
以下是软件测试相关的面试题及答案,欢迎大家参考!
1、你的测试职业发展是什么?
测试经验越多,测试能力越高。所以我的职业发展是需要时间积累的,一步步向着高级测试工程师奔去。而且我也有初步的职业规划,前3年积累测试经验,按如何做好测试工程师的要点去要求自己,不断更新自己改正自己,做好测试任务。
2、你认为测试人员需要具备哪些素质
做测试应该要有一定的协调能力,因为测试人员经常要与开发接触处理一些问题,如果处理不好的话会引起一些冲突,这样的话工作上就会不好做。还有测试人员要有一定的耐心,有的时候做测试很枯燥乏味。除了耐心,测试人员不能放过每一个可能的错误。
软件测试面试教程:2023年爆火的软件测试面试大厂录音分析,从简历开始教你如何在一个月内快速找到工作_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1Wm4y1L7XU/?spm_id_from=333.999.0.0
3、你为什么能够做测试这一行
虽然我的测试技术还不是很成熟,但是我觉得我还是可以胜任软件测试这个工作的,因为做软件测试不仅是要求技术好,还有有一定的沟通能力,耐心、细心等外在因素。综合起来看我认为我是胜任这个工作的。
4、测试的目的是什么?
测试的目的是找出软件产品中的错误,是软件尽可能的符合用户的要求。当然软件测试是不可能找出全部错误的。
5、测试分为哪几个阶段?
一般来说分为5个阶段:单元测试、集成测试、确认测试、系统测试、验收测试
6、单元测试的测试对象、目的、测试依据、测试方法?
测试对象是模块内部的程序错误,目的是消除局部模块逻辑和功能上的错误和缺陷。测试依据是模块的详细设计,测试方法是采用白盒测试。
7、怎样看待加班问题
加班的话我没有太多意见,但是我还是觉得如果能够合理安排时间的话,不会有太多时候加班的。
8、结合你以前的学习和工作经验,你认为如何做好测试。
根据我以前的工作和学习经验,我认为做好工作首先要有一个良好的沟通,只有沟通无障碍了,才会有好的协作,才会有更好的效率,再一个就是技术一定要过关,做测试要有足够的耐心,和一个良好的工作习惯,不懂的就要问,实时与同事沟通这样的话才能做好测试工作。
9、你为什么选择软件测试行业
因为之前了解软件测试这个行业,觉得他的发展前景很好。
10、根据你以前的工作或学习经验描述一下软件开发、测试过程,由哪些角色负责,你做什么
要有架构师、开发经理、测试经理、程序员、测试员。我在里面主要是负责所分到的模块执行测试用例。
11、根据你的经验说说你对软件测试/质量保证的理解
软件质量保证与测试是根据软件开发阶段的规格说明和程序的内部结构而精心设计的一批测试用例(即输入数据和预期的输出结果),并根据这些测试用例去运行程序,以发现错误的过程。它是对应用程序的各个方面进行测试以检查其功能、语言有效性及其外观排布。
12、软件测试的流程是什么?
需求调查:全面了解系统概况、应用领域、软件开发周期、软件开发环境、开发组织、时间安排、功能需求、性能需求、质量需求及测试要求等。根据系统概况进行项目所需的人员、时间和工作量估计以及项目报价。
制定初步的项目计划。
测试准备:组织测试团队、培训、建立测试和管理环境等。
测试设计:按照测试要求进行每个测试项的测试设计,包括测试用例的设计和测试脚本的开发等。
测试实施:按照测试计划实施测试。
测试评估:根据测试的结果,出具测试评估报告。
13、你对SQA的职责和工作活动(如软件度量)的理解?
SQA就是独立于软件开发的项目组,通过对软件开发过程的监控,来保证软件的开发流程按照指定的CMM规程(如果有相应的CMM规程),对于不符合项及时提出建议和改进方案,必要时可以向高层经理汇报以求问题的解决。通过这样的途径来预防缺陷的引入,从而减少后期软件的维护成本。SQA主要的工作活动包括制定SQA工作计划,参与阶段产物的评审,进行过程质量、功能配置及物理配置的审计等;对项目开发过程中产生的数据进行度量等等。
14、说说你对软件配置管理的理解
项目在开发过程中要用相应的配置管理工具对配置项(包括各个阶段的产物)进行变更控制,配置管理的使用取决于项目规模和复杂性及风险的水平。软件的规模越大,配置管理就越显得重要。还有在配置管理中,有一个很重要的概念,那就是基线,是在一定阶段各个配置项的组合,一个基线就提供了一个正式的标准,随后的工作便基于此标准,并只有经过授权后才能变更这个标准。配置管理工具主要有CC,VSS,CVS,SVN等,我只用过SVN,对其他的工具不是很熟悉。
15、怎样写测试计划和测试用例
简单点,测试计划里应有详细的测试策略和测试方法,合理详尽的资源安排等,至于测试用例,那是依赖于需求(包括功能与非功能需求)是否细化到功能点,是否可测试等。
16、说说主流的软件工程思想(如CMM、CMMI、RUP,XP,PSP,TSP等)的大致情况及对他们的理解
CMM:SW Capability Maturity Model软件能力成熟度模型,其作用是软件过程的改进、评估及软件能力的评鉴。
CMMI:Capability Maturity Model Integration能力成熟度模型集成 CMMI融入了大部分最新的软件管理实践,同时弥补了SW-CMM模型中的缺陷。
RUP:rational unified process是软件工程话过程。
XP:extreme program,即极限编程的意思,适用于小型团队的软件开发,像上面第三个问题就可以结合原型法采用这样的开发流程。要明白测试对于xp开发的重要性,强调测试(重点是单元测试)先行的理念。编程可以明显提高代码的质量,持续集成对于快速定位问题有好处。
PSP,TSP分别是个体软件过程和群体软件过程。大家都知道,CMM只是告诉你做什么但并没有告诉你如何做,所以PSP/TSP就是告诉你企业在实施CMM的过程中如何做,PSP强调建立个人技能(如何制定计划、控制质量及如何与其他人相互协作等等)。而TSP着重于生产并交付高质量的软件产品(如何有效的规划和管理所面临的项目开发任务等等)。总之,实施CMM,永远不能真正做到能力成熟度的提升,只有将实施CMM与实施PSP和TSP有机结合起来,才能发挥最大的效力。因此,软件过程框架应该是CMM/PSP/TSP的有机集成。
17、你是怎样保证软件质量的,也就是说你觉得怎样才能最大限度的保证软件的质量?
测试并不能够最大限度的保证软件的质量,软件的高质量是开发和设计出来的,而不是测试出来的,它不仅要通过对软件开发流程的监控,使得软件开发的各个阶段都要按照指定的规程进行,通过对各个阶段产物的评审,QA对流程的监控,对功能及配置的审计来达到开发的最优化。当然测试也是保证软件质量的一个重要方式,是软件质量保证工程的一个重要组成部分。
18、基于目前中国的国情,大多数公司的项目进度紧张、人员较少、需求文档根本没有或者很不规范,你认为在这种情况下怎样保证软件的质量?(大多数公司最想知道的就是在这种困难面前你该怎么保证软件的质量,因为这些公司一般就是这种情况--既不想投入过多又想保证质量)
出现以上的情况,如果仅仅想通过测试来提高软件质量,那几乎是不可能的,原因是没有足够的时间让你去测试,少而不规范的文档导致测试需求无法细化到足够且有针对行的测试。所以,作为公司质量保证的因该和项目经理确定符合项目本身是和的软件生命周期模型(比如RUP的建材,原型法),明确项目的开发流程并督促项目组按照此流程开展工作,所有项目组成员(项目经理更加重要)都要制定出合理的工作计划,加强代码的单元测试,在客户既定的产品交付日期范围内,进行产品的持续集成等等,如果时间允许可以再配合客户进行必要的系统功能测试。
19、一个测试工程师应该具备哪些素质和技能?
1-掌握基本的测试基础理论
2-本着找出软件存在的问题的态度进行测试,不要以挑刺的形象出现
3-可熟练阅读需求规格说明书等文档
4-以用户的观点看问题
5-有强烈的质量意识
6-细心和责任心
7-良好的有效的沟通方式(与开发人员及客户)
8-具有以往的测试经验能够及时准确的判断出高危险区在何处
20、做好软件测试的一些关键点
1-测试人员必须经过测试基础知识和理论的相关培训
2-测试人员必须熟悉系统功能和业务
学习文档 云原生实战笔记
欢迎关注 迪答数据 公众号 ,更多技术、数据学习资源点击链接扫码关注!!!
数据分析从入门到进阶的必看书单!文末附所有200本书籍的PDF下载https://mp.weixin.qq.com/s?__biz=Mzk0NDEwNTE4OQ==&mid=2247485504&idx=3&sn=883a57602a9051079b34752a75d7d027&chksm=c328fbcaf45f72dc293ef3d47e8dd4b7ffc7c0fde70ccf5404f5b0d629d78cab43c52d631069&token=118918614&lang=zh_CN#rd
一 、 docker 常用基础命令 1.进入容器内部的系统,修改容器内容
docker exec -it 容器id /bin/bash 2.提交修改好的镜像
//提交镜像修改 docker commit -a "用户名" -m "提交注释" -m 容器id 3. 查看当前的镜像
docker images 4.将镜像保存为压缩包 可以供其他机器加载
docker save -o abc.tar didamysql:v1.0 //在别的机器加载 docker load -i abc.tar 5.推送远程仓库
docker tag 本地镜像:v1.0 远程仓库名:镜像名:v1.2 //类似于将本地镜像名改为远程指定名字,因为需要带有远程仓库的类似于用户标识,才能被远程镜像仓库识别 docker login 登录远程仓库 docker logout (推送完成后退出) docker push 远程仓库名:镜像名:v1.2(也就是新改的名字) 6.拉取镜像 到本地
docker pull 远程仓库认证路径:镜像名:v1.2 docker pull dida/my-repo:mysql:v1.2 7.运行镜像 docker run -d(后台运行) -p80:80(端口映射,端口暴露,机器的端口映射到容器端口) 镜像名:版本号 #es docker启动步骤 # 创建数据目录 mkdir -p /mydata/es-01 && chmod 777 -R /mydata/es-01 # 容器启动 docker run --restart=always -d -p 9200:9200 -p 9300:9300 \ -e "
一、前言 项目需求,检测目标产品的内接圆尺寸是否合规。
二、Halcon代码 * 输入图像 read_image (Image1, 'C:/Users/Admin/Desktop/InnerCircle/1') get_image_size (Image1, Width, Height) dev_close_window () dev_open_window (0, 0, Width*0.25, Height*0.25, 'black', WindowHandle) dev_display (Image1) * decompose3(Image1,ImageR,ImageG,ImageB) * 提取目标区域 threshold(Image1, Region, 150, 255) *binary_threshold (Image1, Region, 'max_separability', 'light', UsedThreshold) fill_up (Region, RegionFillUp) *opening_circle(RegionFillUp,RegionOpening, 3.5) connection (RegionFillUp, ConnectedRegions) select_shape_std (ConnectedRegions, SelectedRegions, 'max_area', 80) * 内接圆变换 inner_circle (SelectedRegions, Row, Column, Radius) gen_circle_contour_xld (ContCircle, Row, Column, Radius, 0, 6.28318, 'positive', 1) * 结果显示 dev_display (Image1) dev_set_color ('red') dev_set_line_width (3) dev_display (ContCircle) disp_cross (WindowHandle, Row, Column, 50, 0) write_string (WindowHandle, 'MaxDistance='+Radius*13*2/1000) 三、工具设计 四、结果展示
以下内容来自 尚硅谷,写这一系列的文章,主要是为了方便后续自己的查看,不用带着个PDF找来找去的,太麻烦!
第 4 章 FLUX语法 4.1 认识FLUX语言 1、Flux是一种函数式的数据脚本语言,它旨在将查询、处理、分析和操作数据统一为一种语法。想要从概念上理解 FLUX,你可以想想水处理的过程。我们从源头把水抽取出来,然后按照我们的用水需求,在管道上进行一系列的处理修改(去除沉积物,净化)等,最终以消耗品的方式输送到我们的目的地(饮水机、灌溉等)。
注意:InfluxData公司对FLUX语言构想并不是仅仅让它作为InfluxDB的特定查询语言,而是希望它像SQL一样,成为一种标准。按照这个计划,FLUX语言应该具备处理来自不同数据源的数据的能力。
4.2 最简示例 1、与处理水一样,使用FLUX语言进行查询时会执行以下操作。
从数据源中查询指定数量的数据根据时间或字段筛选数据将数据进行处理或者聚合以得到预期结果返回最终的结果 2、下面 3 个示例的处理逻辑都是一样的,只不过数据源有所不同, 这 3 个示例只是让大家看一下语法,不需要运行。
示例 1 :从InfluxDB查询数据并聚合 from(bucket: "example-bucket") |> range(start: -1d) |> filter(fn: (r) => r._measurement == "exa|> mean() mple-measurement") |> yield(name: "_results") 示例 2 :从CSV文件查询数据并聚合 import "csv" csv.from(file: "path/to/example/data.csv") |> range(start: -1d) |> filter(fn: (r) => r._measurement == "example-measurement") |> mean() |> yield(name: "_results") 示例 3 :从PostgreSQL数据库查询数据并聚合 import "sql" sql.from( driverName: "
代理(Proxy)模式允许将对象的操作转移给其他对象,并且可以在不改变其结构的情况下增强其功能或者控制其访问。
什么是代理模式 代理模式是一种用于控制访问和增强对象功能的设计模式。代理模式中,代理对象和目标对象都实现了相同的接口,并且代理对象在其内部维护了一个真实对象的引用。当客户端请求代理对象时,代理对象将其转发给真实对象,并在调用前或调用后进行一些增强操作。
代理模式有不同的类型,例如静态代理和动态代理。静态代理是在编译时创建的代理对象,而动态代理是在运行时创建的代理对象。因此,动态代理更加灵活和易于扩展。
在 Java 中,代理模式是广泛使用的一种设计模式,它可以用于实现 AOP(面向切面编程)等应用场景。
代理模式的使用场景 当目标对象不适合直接访问或者不方便访问时。当需要在对象的访问上增加控制和安全性时。当需要增强对象的功能时。当对象的访问需要给予其他对象或每个对象不可能记住所有细节时。 静态代理的代码示例 以下是一个使用静态代理方式的代码示例,假设我们有一个 Subject 接口和一个 RealSubject 类,我们需要实现一个 StaticProxy 代理类对其进行增强处理:
// Subject 接口 public interface Subject { void request(); } // RealSubject 接口 public class RealSubject implements Subject { public void request() { System.out.println("访问真实对象"); } } // StaticProxy 代理类 public class StaticProxy implements Subject { private Subject subject; // 构造函数初始化目标对象 public StaticProxy(Subject subject) { this.subject = subject; } public void request() { System.
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录 前言一、nvidia硬编解码是什么?二、使用步骤1.安装2.确认1.硬件解码器2.硬件编码器 3.测试 总结 前言 因为工作内容的需要,之前写过一篇文章关于ffmpeg支持英伟达的硬编解码,那个方法比较适合定制化的ffmpeg编译,如果你仅仅使用ffmpeg进行硬件编解码的话,其实不需要这么麻烦。
ffmpeg定制化编译支持cuda编解码
一、nvidia硬编解码是什么? 这个之前的文章已经说过,这里不再多做叙述。可以理解为一种专门的硬件,处理视频解码和编码。
二、使用步骤 首先你需要一张nvidia的卡,最好是GTX以上级别的,因为有些显卡没有硬件编解码器,比如GT920M这种早期笔记本显卡。
AV1在RTX30系列显卡上获得了硬件支持,因为手上没有30系显卡,所以今天只说H264和H265。
今天的比较简单,得益于ffmpeg-3.4功能,让我们在不用编译的情况下就可以直接安装这个版本。
1.安装 确保你的分发版默认的ffmpeg版本支持3.4以上的版本,Ubuntu需要>=18.04,Debian需要>=9。其他的分发版请自行查看。
安装方法也比较简单,使用官方源安装即可。
Ubuntu&Debian:
sudo apt update sudo apt install ffmpeg 2.确认 确认需要用到两个options,一个是-decoders,一个是-encoders
这里输出太长了,我只截取一部分。
1.硬件解码器 ffmpeg -decoders V..... h264_cuvid Nvidia CUVID H264 decoder (codec h264) VFS..D hap Vidvox Hap VFS..D hevc HEVC (High Efficiency Video Coding) V..... hevc_v4l2m2m V4L2 mem2mem HEVC decoder wrapper (codec hevc) V..... hevc_cuvid Nvidia CUVID HEVC decoder (codec hevc) V....D hnm4video HNM 4 video V.
目录
一、saltstack简介
1、介绍
2、Salt的核心功能
3、saltstack通信机制
二、saltstack部署
1、部署环境
2、配置yum源
3、安装master与minion
4、连接认证master和minion
三、salt运行
1、执行格式
2、实操演示
一、saltstack简介 1、介绍 saltstack是一个配置管理系统(客户端和服务端),能够维护预定义状态的远程节点。
saltstack是一个分布式远程执行系统,用来在远程节点上执行命令和查询数据。
saltstack是运维人员提高工作效率、规范业务配置与操作的利器。
2、Salt的核心功能 ①使命令发送到远程系统是并行的而不是串行的
②使用安全加密的协议
③使用最小最快的网络载荷
④提供简单的编程接口
Salt同样引入了更加细致化的领域控制系统来远程执行,使得系统成为目标不止可以通过主机名,还可以通过系统属性。
3、saltstack通信机制 SaltStack 采用 C/S模式,minion与master之间通过ZeroMQ消息队列通信,默认监听4505端口。
Salt Master运行的第二个网络服务就是ZeroMQ REP系统,默认监听4506端口。
二、saltstack部署 1、部署环境 主机名IP地址服务PC1192.168.30.11salt-masterPC2192.168.3.12salt-minion 2、配置yum源 sudo rpm --import https://repo.saltproject.io/py3/redhat/7/x86_64/latest/SALTSTACK-GPG-KEY.pub curl -fsSL https://repo.saltproject.io/py3/redhat/7/x86_64/latest.repo | sudo tee /etc/yum.repos.d/salt.repo 3、安装master与minion PC1执行: yum install -y salt-master #安装master端 systemctl enable --now salt-master #开机自启并启动master服务 PC2执行: yum install -y salt-minion #安装minion端 systemctl enable --now salt-minion.service #开机自启并启动minion服务 4、连接认证master和minion 认证原理:
本文是牛客网Linux 高并发服务器开发视频教程的笔记
1、预备知识 1.1 Linux与远程 使用ssh在widows中控制Linux系统,使用vscode控制代码
使用g++编译
1.1 静态库与动态库 静态库与动态库的制作、区别
1.2 makefile makefile文件操作就是指定所有源文件的编译顺序,因为一个正式的项目会有很多很多源文件,不可能一个个的手动g++,而且各种文件的编译可能还有先后关系,所有要有一个专门的东西来确定编译顺序和编译关系,这个命令就是make。makefile文件
1.3 GDB调试工具 编译时 -g
1.4 文件的io 标准c库io的实现是调用Linux本身的文件操作方式,这种涉及到内存与硬盘的交互的,在不同的平台都可以使用标准c库实现,但是c库回去调用不同平台对应的方法。c库对于文件操作是有缓冲区的存在的,对文件的操作会先对缓冲区操作,最后一下写进磁盘,因此一定要特别注意flush命令的使用
1.5 文件的创建与打开、读写 使用open()打开文件,如果打开成功则返回文件描述符,如果打开失败则返回最近的错误码errno,errno是linux内置的错误号。可以通过perror查看erron对应的错误描述。
使用open()也可以创建一个新的文件,在open函数中多一个O_CREAT参数即可
当一个文件被open函数打开后可以通过read和write函数进行读写操作
下面的代码是将一个文件中的内容复制到一个本来不存在的文件中:
#include<unistd.h> #include<stdio.h> #include<sys/stat.h> #include<sys/types.h> #include<fcntl.h> using namespace std; int main() { //1、读取待复制的文件 int srcfd=open("/home/lanpangzi/Desktop/Linux/lession02/test01.cpp",O_RDONLY); if(srcfd==-1){ perror("open"); return -1; } printf("文件打开成功\n"); //2、创建一个待粘贴的新的空文件,用来写入 int targetfd= open("cpy.cpp",O_WRONLY|O_CREAT,0664); if(targetfd==-1){ perror("open"); return -1; } printf("文件创建成功\n"); //3、循环读写将文件完全拷贝进去 char buff[1024]{}; int read_re = 0; while((read_re=read(srcfd,buff,sizeof(buff)))>0){ write(targetfd, buff,read_re); } printf("文件复制成功\n"); //4、关闭所有打开的文件 close(srcfd); close(targetfd); printf("
写python时发现vscode在debug时无法跳入别人的代码或者底层代码,解决方法如下:
在launch.json里添加"purpose":
"purpose": ["debug-in-terminal"] 修改"JustMyCode"为False:
"justMyCode": false launch.json如下:
{ // Use IntelliSense to learn about possible attributes. // Hover to view descriptions of existing attributes. // For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387 "version": "0.2.0", "configurations": [ { "name": "Python: Current File", "type": "python", "request": "launch", "program": "${file}", "console": "integratedTerminal", "justMyCode": false, "purpose": ["debug-in-terminal"] } ] } x.2 添加启动文件相对位置 "cwd": "/home/SpaGCN/_yingmuzhi",
java8使用Memory Analyzer大概是10左右的版本,用最新版本要java17
MemoryAnalyzer-1.10.0.20200225-win32.win32.x86_64
MAT(Memory Analyzer Tool)下载
https://www.cnblogs.com/zwh0910/p/15774590.html
Eclipse downloads - Select a mirror | The Eclipse Foundation
Eclipse Memory Analyzer Open Source Project | The Eclipse Foundation
Memory Analyzer使用教程 - 掘金
问题处理参考 记录flink taskmanager 生产环境 unable to create new native thread · 语雀
sudo vi /etc/security/limits.d/20-nproc.conf * soft nproc unlimited root soft nproc unlimited * hard nproc unlimited root hard nproc unlimited ulimit -u ulimit -u 65535 vi ~/.bash_profile vi ~/.
在 SQL 查询中,如果将子查询放在 SELECT 语句的最后一行作为字段,而不是在 FROM 子句中连接表时,可能会导致无法正确映射的问题。这是因为在很多 ORM 框架中,它们通常只能处理简单的查询,即将结果映射到对象的属性上。
原始SQL select id, (select p.name from t_plot p where p.id = t_building.plot_id) as plotId, building_type, (select g.grid_name from t_grid g where g.id = t_building.grid_id) as gridId, address_generation_method, address, building_number, unit_count, unit_household_count, (select count(h.id) from t_house h where h.building_id = t_building.id) as totalHouseholdCount from t_building where id = #{id} 子查询totalHouseholdCount放在了最后一行,这样会导致无法正确查询结果到实体类中
当子查询放在 SELECT 语句的最后一行时,ORM 框架可能无法直接将其结果映射到 t_building 实体对象的属性中,因为这样的查询结果并不符合 ORM 框架的预期结构。ORM 框架通常期望结果集中的每一行都映射到一个实体对象上。
正确SQL
将子查询totalHouseholdCount放在不是最后一行即可
一、题目要求: 题目:利用条件运算符的嵌套来完成此题:
学习成绩>=90分的同学用A表示,
60-89分之间的用B表示,60分以下的用C表示。
程序分析:(a>b)?a:b这是条件运算符的基本例子。
二、常规解法,使用IF语句 #include <stdio.h> int main() { int score; char grade; printf("请输入分数:"); scanf("%d",&score); if (score>=90) { grade='A'; } else if (score<=89 && score>=60) { grade='B'; } else { grade = 'C'; } printf("你的分数评价是:%c\n",grade); return 0; } 三、使用题目要求的条件判断式 1、 一般的条件判断式是两者比较,(a>b)?a:b 三目运算符。
2、这里使用到嵌套。
/* 题目:利用条件运算符的嵌套来完成此题: 学习成绩>=90分的同学用A表示, 60-89分之间的用B表示,60分以下的用C表示。 程序分析:(a>b)?a:b这是条件运算符的基本例子。 */ #include <stdio.h> int main() { int score; char grade; printf("请输入分数:"); scanf("%d",&score); grade = (score>=90)?'A':((score<60)?'C':'B'); printf("你的分数评价是:%c\n",grade); return 0; }
文章目录 HTML1.初识HTML1.1什么是HTML 2.网页基本标签2.1标题标签2.2段落标签2.3换行标签2.4水平线标签2.5字体样式标签2.6注释和特殊符号 3.图像、超链接、网页布局3.1图像3.2链接标签3.3网页布局 4、列表、表格、媒体元素4.1列表4.2表格4.3媒体元素 5.页面结构分析6.iframe内联框架7、表单标签(重点)文本输入框密码输入框单选框多选框按钮文件域下拉框文本域简单验证滑块搜索框 8、表单应用(重点)9、表单初体验(重点) CSS(层叠样式表)学习步骤1、什么是CSS11.什么是CSS1.2.发展史1.3.快速入门1.4.CSS的三种导入方式 2、选择器2.1.基本选择器2.2.层次选择器2.3.结构伪类选择器2.4.属性选择器(常用) 3、美化网页元素3.1.为什么要美化网页3.2.字体样式3.3.文本样式3.4.阴影3.5.超链接伪类3.6.列表3.7.背景3.8.渐变 4、盒子模型4.1.什么是盒子模型4.2.边框4.3.内外边距4.4.圆角边框4.5.盒子阴影(讲解前端知识) 5、浮动5.1.标准文档流5.2.display(重要)5.3.float5.4.父级边框塌陷问题5.5.display与float对比 6、定位6.1.相对定位6.2.绝对定位6.3.固定定位 fixed6.4.z-index6.5.动画 JavaScript1.前端知识体系1.1前端三要素1.2结构层(HTML)1.3表现层(CSS)1.4行为层(JavaScript)1.5JavaScript框架 2.快速入门2.1引入JavaScript2.2基本语法入门2.3调试2.4数据类型2.5严格检查模式 3.数据类型3.1字符串3.2数组3.3对象 8.操作DOM对象(重点)8.1获得Dom节点8.2更新节点信息8.3删除节点8.4插入节点 9.操作表单(验证)10.jQuery HTML 学习网站:https://jquery.cuishifeng.cn/index.html
1.初识HTML HTML5+CSS3
1.1什么是HTML Hyper Text Markup Language - (超文本标记语言)
超文本:文字、图片、音频、视频、动画等
W3C:World Wide Web Consortium - 万维网联盟 - 中立性技术标准机构
W3C标准
结构化标准语言(HTML、XML)表现标准语言(CSS)行为标准(DOM,ECMAScript) 2.网页基本标签 <!--DOCTYPE:告诉浏览器,我们要使用什么规范--> <!DOCTYPE html> <html lang="en"> <head> <!-- meta: 描述性标签 --> <meta charset="UTF-8"> <meta name="keywords" content="音乐"> <meta name="description" content="了解音乐"> <!-- 网页标题 --> <title>我的第一个界面</title> </head> <body> <!--网页主体--> </body> </html> 2.
Redis 7.0 核心技术与实战应用 🌈 Redis 入门概述 01、Redis 是什么 Redis:REmote Dictionary Server(远程字典服务器)
官网介绍:https://redis.io/docs/about
官网定义:Remote Dictionary Server(远程字典服务)是完全开源的,使用 ANSIC 语言编写遵守 BSD 协议,是一个高性能的 Key-Value 数据库提供了丰富的数据结构,例如 String、Hash、List、Set、SortedSet 等。数据是存在内存中的,同时支持 事务、持久化、LUA脚本、发布/订阅、缓存淘汰、流技术 等多种功能特性。提供了 主从模式、Redis Sentinel 和 Redis Cluster 集群架构方案。
02、Redis 使用场景 🅰️ 1、主流功能与应用
1)分布式缓存,挡在 MySQL 数据库之前的带刀护卫
与传统数据库(MySQL)关系:
Redis 是 key-value 数据库(NoSQL 一种),MySQL 是关系数据库;Redis 数据操作主要在内存,而 MySQL 主要存储在磁盘;Redis 在某一些场景使用中要明显优于 MySQL,比如计数器、排行榜等方面;Redis 通常用于一些特定场景,需要与 MySQL 一起配合使用;两者并不是相互替换和竞争关系,而是共用和配合使用。 2)内存存储和持久化(RDB + AOF)
Redis 支持 异步 将内存中的数据写到硬盘上,同时不影响继续服务。
3)高可用架构搭配
支持 单机、主从、哨兵、集群 架构模式。
4)缓存穿透、击穿、雪崩
5)分布式锁
6)队列
Reids 提供 list 和 set 操作,这使得 Redis 能作为一个很好的消息队列平台来使用。
分而治之 fork/Join框架的思想是将一个规模为n的大任务,fork成几个规模较小的K个子任务,最后合并所有子任务的结果,返回最终结果。
工作窃取 如图一个规模为T的任务划分成12个子任务,分别有4个线程在执行。如果当前线程没有可执行任务时,会从其他线程的任务队列中窃取任务来执行。工作窃取算法保证了cpu不会处于空闲状态。
ForkJoin用法 1.带返回值RecursiveTask public class MySumTask extends RecursiveTask<Integer> { private int[] data; private int begin; private int end; @Override protected Integer compute() { //最小划分粒度 if (end-begin<=2){ int result=0; for (int i = begin; i <end ; i++) { result+=data[i]; } return result; } int middle=(begin+end)/2; MySumTask left=new MySumTask(data,begin,middle); left.fork(); MySumTask right=new MySumTask(data,middle,end); right.fork(); return left.join()+right.join(); } 打印统计结果
public static void main(String[] args) { int[] dataArr=new int[]{1,2,3,4,6,7,8}; MySumTask mySumTask=new MySumTask(dataArr,0,dataArr.
之前一直听说HuTool工具包的神奇与强大,最近才发现确实是一个大而全的宝藏工具,简单记录下供大家分享与参考使用
简介 Hutool是一个小而全的Java工具类库,通过静态方法封装,降低相关API的学习成本,提高工作效率,使Java拥有函数式语言般的优雅;Hutool是项目中“util”包友好的替代,它节省了开发人员对项目中公用类和公用工具方法的封装时间,使开发专注于业务,同时可以最大限度的避免封装不完善带来的bug。 HuTool名字的由来 Hutool = Hu + tool,是原公司项目底层代码剥离后的开源库,“Hu”是公司名称的表示,tool表示工具。Hutool谐音“糊涂”,一方面简洁易懂,一方面寓意“难得糊涂”。
HuTool如何改变我的Coding方式 以计算MD5为例:
【以前】打开搜索引擎 -> 搜“Java MD5加密” -> 打开某篇博客-> 复制粘贴 -> 改改好用
【现在】引入Hutool -> SecureUtil.md5()
只有懂得才懂,哈哈,代码真的是真正需要CV的时候才知道收藏的代码方恨少啊,只能这里那里复制粘贴下,这也正是CV工程师的魅力所在吧!
包含组件 一个Java基础工具类,对文件、流、加密解密、转码、正则、线程、XML等JDK方法进行封装,组成各种Util工具类,同时提供以下组件:
模块介绍hutool-aopJDK动态代理封装,提供非IOC下的切面支持hutool-bloomFilter布隆过滤,提供一些Hash算法的布隆过滤hutool-cache简单缓存实现hutool-core核心,包括Bean操作、日期、各种Util等hutool-cron定时任务模块,提供类Crontab表达式的定时任务hutool-crypto加密解密模块,提供对称、非对称和摘要算法封装hutool-dbJDBC封装后的数据操作,基于ActiveRecord思想hutool-dfa基于DFA模型的多关键字查找hutool-extra扩展模块,对第三方封装(模板引擎、邮件、Servlet、二维码、Emoji、FTP、分词等)hutool-http基于HttpUrlConnection的Http客户端封装hutool-log自动识别日志实现的日志门面hutool-script脚本执行封装,例如Javascripthutool-setting功能更强大的Setting配置文件和Properties封装hutool-system系统参数调用封装(JVM信息等)hutool-jsonJSON实现hutool-captcha图片验证码实现hutool-poi针对POI中Excel和Word的封装hutool-socket基于Java的NIO和AIO的Socket封装hutool-jwtJSON Web Token (JWT)封装实现 (可以根据需求对每个模块单独引入,也可以通过引入hutool-all方式引入所有模块)
安装(这里只简单介绍maven) 在项目的pom.xml的dependencies中加入以下内容:
<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.8.16</version> </dependency> BOM(Hutool-bom) 起初Hutool只提供了两种引入方式:
引入hutool-all以便使用所有工具类功能引入hutool-xxx单独模块使用 整个bom模块只由一个pom.xml组成,同时提供了dependencyManagement和dependencies两种声明。于是我们就可以针对不同需要完成引入。
使用 import方式 如果你想像Spring-Boot一样引入Hutool,再由子模块决定用到哪些模块,你可以在父模块中加入:
<dependencyManagement> <dependencies> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-bom</artifactId> <version>${hutool.version}</version> <type>pom</type> <!-- 注意这里是import --> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> 在子模块中就可以引入自己需要的模块了:
<dependencies> <dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-http</artifactId> </dependency> </dependencies> 使用import的方式,只会引入hutool-bom内的dependencyManagement的配置,其它配置在这个引用方式下完全不起作用。
目录
一、Java提供了哪些基本数据类型?
二、在Java语言中null值是什么?在内存中null是什么?
三、如何理解赋值语句String x=null?
四、int和Integer有什么区别?
五、什么是不可变类
六、在Java语言中,类型转换有哪几种类型?
(1)类型自动转换
(2)强制类型转换
七、 强制类型转换的注意事项有哪些?
八、Math类中round、ceil和floor方法的功能各是什么?
九、++i与i++有什么区别?
一、Java提供了哪些基本数据类型? Java语言一共提供了8种原始的数据类型(byte,short,int,long,float,double,char,boolean),这些数据类型不是对象,而是Java语言中不同于类的特殊类型,这些基本类型的数据变量在声明之后就会立刻在栈上被分配内存空间。
除了这8种基本的数据类型外,其他类型都是引用类型(例如类、接口、数组等),引用类型类似于C++中的引用或指针的概念,它以特殊的方式指向对象实体,这类变量在声明时不会被分配内存空间,只是存储了一个内存地址而已。
此外,Java语言还提供了对这些原始数据类型的封装类(字符类型Character,布尔类型Boolean,数值类型Byte、Short、Integer、Long、Float、Double)。
需要注意的是,Java中的数值类型都是有符号的,不存在无符号的数,它们的取值范围也是固定的,不会随着硬件环境或者操作系统的改变而改变。除了以上提到的8种基本数据类型以外,在Java语言中,还存在另外一种基本类型void,它也有对应的封装类java.lang.void,只是无法直接对它进行操作而已。
封装类型和原始类型有许多不同点:
首先,原始数据类型在传递参数时都是按值传递,而封装类型是按引用传递的。
其次,当封装类型和原始类型用作某个类的实例数据时,它们所指定的默认值不同。对象引用实例变量的默认值为null,而原始类型实例变量的默认值与它们的类型有关(例如int默认初始化为0)
二、在Java语言中null值是什么?在内存中null是什么? null不是一个合法的Object实例,所以编译器并没有为其分配内存,它仅仅用于表明该引用目前没有指向任何对象。其实,与C语言类似,null是将引用变量的值全部置0。
三、如何理解赋值语句String x=null? 在Java语言中,变量被分为两大类型:原始值(primitive)与引用值(reference)。声明为原始类型的变量,其存储的是实际的值。声明为引用类型的变量,存储的是实际对象的地址(指针,引用)。对于赋值语句String x=null,它定义了一个变量“x”,x中存放的是String引用,此处为null。
四、int和Integer有什么区别? Java语言提供两种不同的类型,即引用类型和原始类型(或内置类型)。int是Java语言的原始数据类型,Integer是Java语言为int提供的封装类。Java为每个原始类型提供了封装类。
引用类型与原始类型的行为完全不同,并且它们具有不同的语义。而且,引用类型与原始类型具有不同的特征和用法。
五、什么是不可变类 不可变类是指当创建了这个类的实例后,就不允许修改它的值了,也就是说,一个对象一旦被创建出来,在其整个生命周期中,它的成员变量就不能被修改了。它有点类似于常量(const),即只允许别的程序读,不允许别的程序进行修改。
在Java类库中,所有基本类型的包装类都是不可变类,例如Integer、Float等。此外,String也是不可变类。
要创建一个不可变类需要遵循下面5条基本原则:
1)类中所有成员变量被private所修饰。
2)类中没有写或者修改成员变量的方法,例如setxxx,只提供构造函数,一次生成,永不改变。
3)确保类中所有方法不会被子类覆盖,可以通过把类定义为final或者把类中的方法定义为final来达到这个目的。
4)如果一个类成员不是不可变量,那么在成员初始化或者使用get方法获取该成员变量时,需要通过clone方法来确保类的不可变性。
5)如果有必要,可使用覆盖Object类的equals()方法和hashCode()方法。在equals()方法中,根据对象的属性值来比较两个对象是否相等,并且保证用equals()方法判断为相等的两个对象的hashCode()方法的返回值也相等,这可以保证这些对象能被正确地放到HashMap或HashSet集合中。
六、在Java语言中,类型转换有哪几种类型? (1)类型自动转换 低级数据类型可以自动转换为高级数据类型
当类型自动转换时,需要注意以下几点:
1)char类型的数据转换为高级类型(如int,long等),会转换为其对应的ASCII码。
2)byte、char、short类型的数据在参与运算时会自动转换为int型,但当使用“+=”运算时,就不会产生类型的转换
3)另外,在Java语言中,基本数据类型与boolean类型是不能相互转换的。
总之,当有多种类型的数据混合运算时,系统会先自动地将所有数据转换成容量最大的那一种数据类型,然后再进行计算。
(2)强制类型转换 当需要从高级数据类型转换为低级数据类型时,就需要进行强制类型转换
需要注意的是,在进行强制类型转换时可能会损失精度。
七、 强制类型转换的注意事项有哪些? Java语言在涉及byte、short和char类型的运算时,首先会把这些类型的变量值强制转换为int类型,然后对int类型的值进行计算,最后得到的值也是int类型。因此,如果把两个short类型的值相加,最后得到的结果是int类型;如果把两个byte类型的值相加,最后也会得到一个int类型的值。如果需要得到short类型的结果,就必须显式地把运算结果转换为short类型
例如对于语句short s1=1;s1=s1+1
由于在运行时会首先将s1转换成int类型,因此s1+1的结果为int类型,这样编译器会报错,所以,正确的写法应该short s1=1;s1=(short)(s1+1)。
有一种例外情况。“+=”为Java语言规定的运算法,Java编译器会对其进行特殊处理,因此,语句short s1=1;s1+=1能够编译通过
八、Math类中round、ceil和floor方法的功能各是什么? 1)round方法表示四舍五入。round,意为“环绕”,其实现原理是在原来数字的基础上先增加0.5然后再向下取整,等同于(int)Math.floor(x+0.5f)。它的返回值类型为int型,例如,Math.round(11.5)的结果为12,Math.round(-11.5)的结果为-11
2)ceil方法的功能是向上取整。ceil,意为“天花板”,顾名思义是对操作数取顶,Math.ceil(a),就是取大于a的最小的整数值。需要注意的是,它的返回值类型并不是int型,而是double型。若a是正数,则把小数“入”,若a是负数,则把小数“舍”。
Math.ceil(12.5)的结果为13
Math.ceil(-12.5)的结果为-12
3)floor方法的功能是向下取整。floor,意为“地板”,顾名思义是对操作数取底。Math.floor(a),就是取小于a的最大的整数值。它的返回值类型与ceil方法一样,也是double型。若a是正数,则把小数“舍”;若a是负数,则把小数“入”。
Math.floor(12.5)的结果为12,
Math.floor(-11.5)的结果为-12
九、++i与i++有什么区别? 在编程时,经常会用到变量的自增或自减操作,尤其在循环中用得最多。以自增为例,有两种自增方式:前置与后置,即++i和i++,它们的不同点在于i++是在程序执行完毕后进行自增,而++i是在程序开始执行前进行自增
文章目录 前言一、内存映射概念二、mmap函数介绍三、ftruncate函数四、mmap函数使用五、mmap函数中的MAP_SHARED和MAP_PRIVATE总结 前言 本篇文章我们来讲解一下内存映射。
一、内存映射概念 内存映射是一种将文件或其他设备映射到进程的虚拟内存空间的技术。它通过在进程的地址空间中创建一个映射区域,使得进程可以像访问内存一样直接访问文件或设备的内容。内存映射提供了一种高效的方式来进行文件 I/O 操作和共享内存数据。
在内存映射中,操作系统为进程创建了一个虚拟内存区域,该区域与实际的文件或设备建立了映射关系。当进程通过对该内存区域进行读写操作时,对应的文件或设备内容也会被读取或写入。
内存映射的主要优点包括:
1.直接访问:通过内存映射,进程可以像访问内存一样直接访问文件或设备的内容。这消除了传统的读取和写入文件的系统调用的开销,提高了读写性能。
2.共享内存:多个进程可以将同一个文件映射到各自的地址空间中,使得它们可以共享文件的内容。这种共享内存的方式可以用于进程间通信和数据共享。
3.简化文件 I/O 操作:通过内存映射,可以将文件的内容直接映射到内存中,从而省去了使用 read() 和 write() 等传统的文件 I/O 函数的步骤。这样就可以通过简单的内存操作来处理文件数据。
内存映射的实现通常涉及以下步骤:
1.打开文件或设备:首先,需要打开要映射的文件或设备,通常使用标准的文件 I/O 函数(如 open())来打开文件并获取文件描述符。
2.创建映射:使用操作系统提供的内存映射函数(如 mmap())来创建映射区域,将文件或设备的内容映射到进程的虚拟内存空间中。
3.访问数据:一旦内存映射建立,进程就可以通过对映射区域进行读取和写入操作,无需使用传统的文件 I/O 函数。
4.解除映射:最后,当进程不需要访问映射数据时,应该使用相应的函数(如 munmap())来解除内存映射。
需要注意的是,内存映射在操作系统层面进行,因此在不同的操作系统中,对内存映射的支持和实现方式可能会有所不同。
总结起来,内存映射是一种通过让文件或设备的内容直接映射到进程的虚拟内存空间中,实现高效文件 I/O 操作和共享内存数据的技术。它提供了直接访问性能高、共享数据的能力,并简化了对文件内容的访问操作。
二、mmap函数介绍 mmap(memory map)函数是用于在应用程序和内核之间建立内存映射的系统调用函数。它允许应用程序将一个文件或者匿名内存映射到其地址空间,从而实现对文件或内存区域的直接访问。
函数原型如下:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset); 参数说明:
addr:指定欲映射的首地址,通常设为0,表示由系统自己选择映射的地址。
length:指定映射的内存区域长度,以字节为单位。
prot:指定映射区域的保护方式(权限)。可以是PROT_NONE(无权限)、PROT_READ(可读)、PROT_WRITE(可写)、PROT_EXEC(可执行)等之一,也可以通过位掩码进行组合,例如PROT_READ | PROT_WRITE。
flags:用于指示映射类型和映射属性的标志位。常用的标志包括MAP_SHARED(与其他映射该文件的进程共享更新),MAP_PRIVATE(复制映射,对映射的修改不会写回文件),MAP_ANONYMOUS(创建匿名映射)等。
fd:要映射的文件描述符,如果映射的是匿名内存,则为-1。
offset:文件映射的偏移量,对于匿名映射来说通常为0。
返回值是映射区域的起始地址,如果映射失败则返回MAP_FAILED(通常是-1)。
通过mmap函数,应用程序可以将文件(如磁盘上的文件)或匿名内存映射到自己的虚拟地址空间,从而使得应用程序能够直接对内存区域进行读写操作,就像访问普通内存一样。
mmap函数在许多场景中都很常见,常用的用途包括:
1.文件 I/O:通过将文件映射到内存,可以使用内存操作来读写文件,避免了频繁的文件 I/O 操作。
Sublime Text 3常用插件及安装方法
相关教程:sublime text 3 快捷键大全以及配置编译环境。
安装Sublime Text 3插件的方法:
直接安装
安装Sublime text 2插件很方便,可以直接下载安装包解压缩到Packages目录(菜单->preferences->packages)。
使用Package Control组件安装
也可以安装package control组件,然后直接在线安装:
1.按Ctrl+`调出console(注:安装有QQ输入法的这个快捷键会有冲突的,输入法属性设置-输入法管理-取消热键切换至QQ拼音)
2.粘贴以下代码到底部命令行并回车:
import urllib.request,os; pf = 'Package Control.sublime-package'; ipp = sublime.installed_packages_path(); urllib.request.install_opener( urllib.request.build_opener( urllib.request.ProxyHandler()) ); open(os.path.join(ipp, pf), 'wb').write(urllib.request.urlopen( 'http://sublime.wbond.net/' + pf.replace(' ','%20')).read())
1.重启Sublime Text 3。
2.如果在Perferences->package settings中看到package control这一项,则安装成功。
顺便贴下Sublime Text2 的代码
import urllib2,os; pf='Package Control.sublime-package'; ipp = sublime.installed_packages_path(); os.makedirs( ipp ) if not os.path.exists(ipp) else None; urllib2.install_opener( urllib2.build_opener( urllib2.ProxyHandler( ))); open( os.