参考文章 FRIDA-API使用篇:Java、Interceptor、NativePointer(Function/Callback)使用方法及示例-安全客 - 安全资讯平台 (anquanke.com)
JavaScript API | Frida • A world-class dynamic instrumentation toolkit
文章目录 参考文章1、Java.available2、Java.androidVersion3、附加调用Java.perform4、获取类Java.use5、Hook静态方法和实例方法、修改函数参数和返回值6、Hook构造方法:$init7、Hook重载方法8、扫描实例类Java.choose9、主动调用10、获取和修改类的字段11、Hook内部类与匿名类12、Hook枚举类13、枚举所有类14、枚举类的所有方法15、Hook类的所有方法16、枚举所有类加载器17、类型转换器Java.cast18、定义任意数组类型Java.array19、注册类Java.registerClass(spec)20、注入dex21、写文件22、全局上下文环境获取23、打印函数堆栈24、Hook只在指定函数内生效25、Hook定位接口/抽象类的实现类26、Hook动态加载的Dex27、注意事项 1、Java.available 判断当前进程是否加载了JavaVM,Dalvik或ART虚拟机
function frida_Java() { Java.perform(function () { if(Java.available) { console.log("hello java vm"); }else{ console.log("error"); } }); } setImmediate(frida_Java);//setImmediate(回调方法, 参数1,参数2,...) 异步任务,立即执行 输出如下: hello java vm 2、Java.androidVersion 显示android系统版本号
function frida_Java() { Java.perform(function () { if(Java.available) { console.log("",Java.androidVersion); }else{ console.log("error"); } }); } setImmediate(frida_Java); 输出如下: 10 3、附加调用Java.perform 主要用于当前线程附加到Java VM并且调用fn方法它也有一个好兄弟:Java.performNow(fn)
4、获取类Java.use 构造实例:$new实例的一些属性 .$class == .getClass().$className == .
1.概念 2.生活中的例子 小弟-老大; 帮派识别
3.实现 3.1 初始化 3.2 中间过程 3.3合并 3.4 并查集路径优化 直接把下面的节点指向最终的老大。
3.5 伪代码实现 3.6JAVA实现 findRoot: 谁是帮派的老大。例如山鸡的老大是陈浩南
connected: 我们是不是同一个大帮派。 例如山鸡和肥仔是一个大帮派,都属于洪兴。
union:两个大帮派合并。例如洪兴和东星合并为一个大帮派。
一、解题必备模板 1.递归 2.DFS 3.BFS 4.二分查找 5.动态规划DP 6.位运算 7.动态规划&回溯&贪心 二、切题四件套&刻意练习
为什么限流 运营网站,经常会遇到各种挑战:某黑客发起DoS攻击、网络爬虫网页抓取、商品秒杀活动、双十一与618等场景,会使流量突然激增,如果不限制流量的访问就会使系统宕机。
常见的限流算法 1.漏桶算法( LEAKY BUCKET) 漏桶算法创造一个固定容量的队列(漏桶),每个请求就像一滴水,到来后会先存储在漏桶里面。漏桶的底部有个破洞,水低落下来的速率就是限流的阈值。当漏桶容量已满时,后续的请求会溢出(拒绝或者延迟处理)。
优点:可以平滑的控制流量的进出,保证系统的安全性与稳定性。
缺点:漏桶算法无法应付突然激增的流量,如果流量突增,因为算法本身的限制,只能按照固定的速度去处理请求。
2.令牌桶算法(Token Bucket) 令牌桶算法类似上面的漏桶算法,它相当于有个管理员按照限流的大小,定速地向令牌桶扔令牌。所有的请求都会从令牌桶获取令牌,获取成功处理请求逻辑,获取失败拒绝访问。令牌桶满了后,多余的令牌会丢弃。
优点:令牌桶算法是针对漏桶算法的优化,能够应对突增的流量。
我们可以使用Guava的RateLimiter来实现令牌
3.计数器算法 最简单的一种限流算法,我们可以通过原子操作类累积一秒内的请求次数,如果超过设定阈值,拒绝请求访问。
优点:实现简单,单机模式下用Atomic类来实现,分布式下使用Redis就可以实现
缺点:只能进行简单的控制请求速率,无法做到精准的控制,无法应对突发的流量增长
时序预测 | MATLAB实现基于CNN卷积神经网络的时间序列预测-递归预测未来(多指标评价) 目录 时序预测 | MATLAB实现基于CNN卷积神经网络的时间序列预测-递归预测未来(多指标评价)预测结果基本介绍程序设计参考资料 预测结果 基本介绍 1.Matlab实现CNN卷积神经网络时间序列预测未来;
2.运行环境Matlab2018及以上,data为数据集,单变量时间序列预测;
3.递归预测未来数据,可以控制预测未来大小的数目,适合循环性、周期性数据预测;
4.命令窗口输出R2、MAE、MAPE、MBE、MSE等评价指标。
运行环境Matlab2018及以上。
程序乱码是由于Matlab版本不一致造成的,处理方式如下:
先重新下载程序,随后,如main.m文件出现乱码,则在(桌面的)文件夹中找到目标文件main.m。右击选择打开方式为文本文档(txt),查看文档是否乱码,通常不乱码。
则删除Matlab中的main.m的全部代码,将文本文档中不乱码的代码复制到Matlab中的main.m中。
程序设计 完整程序和数据获取方式1:私信博主回复MATLAB实现基于CNN卷积神经网络的时间序列预测-递归预测未来(多指标评价),同等价值程序兑换;完整程序和数据下载方式2(资源处直接下载):MATLAB实现基于CNN卷积神经网络的时间序列预测-递归预测未来(多指标评价);完整程序和数据下载方式3(订阅《CNN卷积神经网络》专栏,同时可阅读《CNN卷积神经网络》专栏内容,数据订阅后私信我获取):MATLAB实现基于CNN卷积神经网络的时间序列预测-递归预测未来(多指标评价),专栏外只能获取该程序。 %% 创建混合网络架构 % 输入特征维度 numFeatures = f_; % 输出特征维度 numResponses = 1; FiltZise = 10; % 创建模型 layers = [... % 输入特征 sequenceInputLayer([numFeatures 1 1],'Name','input') sequenceFoldingLayer('Name','fold') % 特征学习 (50,'Name','lstm1','RecurrentWeightsInitializer','He','InputWeightsInitializer','He') (optVars.NumOfUnits,'OutputMode',"last",'Name','bil4','RecurrentWeightsInitializer','He','InputWeightsInitializer','He') dropoutLayer(0.25,'Name','drop3') % 全连接层 fullyConnectedLayer(numResponses,'Name','fc') regressionLayer('Name','output') ]; layers = layerGraph(layers); layers = connectLayers(layers,'fold/miniBatchSize','unfold/miniBatchSize'); %% 训练选项 % 批处理样本 MiniBatchSize =128; % 最大迭代次数 MaxEpochs = 500; options = trainingOptions( 'adam', .
文章目录 DTS和DTSIDTBdtc一、语法篇reg 属性reg 限制(注意是子节点)model 属性status 属性compatible 属性aliases 节点chosen 节点device_type 属性自定义属性 二、实例分析篇中断瑞芯微恩智浦三星其他写法总结: 实战:描述中断资源时钟CPUGPIO实战:用设备树点亮LED灯pinctrlpinctrl 客户端pinctrl 服务端 总结 三、使用篇设备树下的 device 和 driver 匹配查找节点有关的 OF 函数查找父/子节点的 OF 函数提取属性值的 OF 函数其他常用的 OF 函数获取中断号的 OF 函数获取 GPIO 的 OF 函数 四、附加篇ranges 属性 DTS和DTSI .dts文件是一种ASCII文本对Device Tree的描述,放置在内核的/arch/arm/boot/dts目录。一般而言,一个.dts文件对应一个ARM的machine。
.dtsi文件作用:由于一个SOC可能有多个不同的电路板,而每个电路板拥有一个 .dts。这些dts势必会存在许多共同部分,为了减少代码的冗余,设备树将这些共同部分提炼保存在.dtsi文件中,供不同的dts共同使用。.dtsi的使用方法,类似于C语言的头文件,在dts文件中需要进行include *.dtsi文件。当然,dtsi本身也支持include 另一个dtsi文件。
DTB DTC编译*.dts生成的二进制文件(.dtb),bootloader在引导内核时,会预先读取.dtb到内存,进而由内核解析。
目录:
Linux/kernel/arch/arm/boot/dts
Linux/kernel/arch/arm64/boot/dts
dtc (编译内核源码时会编译出该工具,看 .config 中 CONFIG_DTC 选项是否编进内核,或者在 linux/kernel/scripts/dtc/ 中有源码,看 linux/kernel/scripts/ 目录下的makefile 会有:
subdir -S(CONFIG_DTC)+= dtc 编译设备树:
dtc -I dts -O dtb -o xxx.
本文主要基于网上已有的代码以及官方给定示例代码进行修改。如有不妥请指出,谢谢啦。
一、思路分析 1.1 整体思路 据我了解,微信小程序只能通过低功耗蓝牙(BLE)进行控制。
1.2 微信小程序思路 1.3 ESP32端思路 BLE蓝牙部分设置流程(通过该程序就能让esp32广播蓝牙,同时手机也可搜索到蓝牙设备):
//
获取蓝牙接收的数据与处理(主要用到 if 语句,用于判断接收的数据是控制LED灯开还是LED灯关):
二、 控制代码 2.1 微信小程序端代码 全局变量
App({ onLaunch() { // 展示本地存储能力 }, globalData: { appdid : null, appsid : null, appcid : null } }) 蓝牙搜索与连接界面
<wxs module="utils"> module.exports.max = function(n1, n2) { return Math.max(n1, n2) } module.exports.len = function(arr) { arr = arr || [] return arr.length } </wxs> <button bindtap="openBluetoothAdapter">开始扫描</button> <button bindtap="stopBluetoothDevicesDiscovery">停止扫描</button> <button bindtap="closeBluetoothAdapter">结束流程</button> <view class="
我在windows11环境下运行paddlehub报错,提示:UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte…**
参考篇文字的解决方案:window10下运行项目报错:UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte...的解决办法_unicodedecodeerror: 'gbk' codec can't decode byte _山兮 木兮的博客-CSDN博客
我这里给自己做个笔记,他人遇到也可以参考。
报错原因时windows默认是编码是gbk,导致与python的编码冲突,所以这里需要修改windows默认的编码。
前篇 # 为什么要写这篇文章呢
现在属于网络时代,服务器的使用越来越广泛,网站搭建、软件开发、游戏开发和区块链等都是需要在服务器里操作搭建的,花时间写这篇文章是希望能有更多的人对服务器有更好的认识
一、## 检查哪些尝试入侵服务器的ip命令
ubuntu查看尝试登录服务器的ip,一般用来查看攻击ip来源:
grep "Failed password for root" /var/log/auth.log | awk '{print $11}' | sort | uniq -c | sort -nr | more
centos查看尝试登录服务器的ip,一般用来查看攻击ip来源:
cat /var/log/secure | awk '/Failed/{print (NF-3)}'| sort| uniq -c| awk '{print 2"="$1;}'
然后将以上ip加入/etc/hosts.deny 文件,格式:all:45.113.201.77
二、## 远程连接服务器非常慢
当你远程连接服务器非常慢的时候,可以参考以下步骤排查:
1、首先,ping服务器IP,看延迟是否正常
怎么ping服务器ip呢?
首先可以在开始的菜单栏里找到运行,快捷键win+R
输入格式:ping (服务器ip) -t 即可看见ping值,注意服务器ip就是指服务器的ip 不用加括号,ping后面是空格 -t前面也是空格,无法连接到服务器也是可以ping一下 看服务器的线路是否通畅
2、其次,ping服务器的网关IP,对比延迟是否正常
ping服务器的网关ip和ping服务器ip是有些不一样的,需要先找到服务器网关ip
也是先在开始的菜单栏找到运行,快捷键WIN+R
输入cmd可以进入一个界面,接着输入ipconfig/all命令然后回车,回车后就可以看见服务器ip和服务器网关ip了 服务器网关ip找到 就可以按照之前的步骤去ping一下
针对以上操作,会有两种情况
情况一:服务器IP和网关IP延迟都较大,则可能是线路问题,建议提交网络类工单联系技术排查
情况二:服务器IP延迟大,网关IP延迟正常,多半是服务器本身问题,可能是带宽跑满、服务器负载过大等原因,建议进服务器自行查看资源使用,或提交综合技术类工单联系技术排查
三、## 服务器托管用带宽拥堵如何解决
带宽是服务器托管用户最重视的资源,对于数据延迟以及流量增高往往会十分敏
感,那么当带宽跑满的时候我们该如何积极应对才能有效化解这些难题呢?
服务器带宽跑满原因:
目录
一,静态路由中的相关配置
查看路由表中路由信息
查看路由表中是由静态写的路由
查看路由器的端口的ip情况
手写静态路由:
创建回环接口和配置地址
配置缺省路由
配置空接口
配置浮动静态路由
二,名词解释
1.路由
2.路由器的工作原理
3.路由器生成路由条的方法:
4.获取未知网段的方法:
5.次优路径
6.负载均衡
7.回环接口
8.手工汇总——子网汇总
9.路由黑洞(黑洞路由)
10.缺省路由(默认路由)
11.空接口
12.浮动静态路由
13.VLSM--无类域间路由(子网划分)
做法:通过借用主机位来充当网络位
14.CIDR(子网汇总)
15.代理ARP
16.ICMP重定向
一,静态路由中的相关配置 查看路由表中路由信息 [r1]display ip routing-table
查看路由表中是由静态写的路由 [r1]display ip routing-table protocol static 查看路由器的端口的ip情况 [Huawei]display ip interface brief 手写静态路由: MA网络中:
[ri] ip route-static 192.168.3.0 24 192.168.2.2
目标网路号 下一跳
点到点网络中
[ri] ip route-static 192.168.3.0 24 192.168.2.2
目标网路号 出接口
写法区别:
建议在MA网络中使用下一跳写法:在点到点网络中使用出接口写法
MA:一个网段中节点的数量不限制----以太网
点到点:一个网段中只能有两个节点
1.若在MA网络中使用了出接口写法
设备为获取下一跳的MAC地址,将自动使用代理ARP和ICMP重定向来进行:---该工程将消耗网络资源,增加网络延时,故建议直接使用下一跳写法
目录
一,HCIA简介:
二,了解HCIA中的一些常用名词定义
1.计算机起源:
2.网络:
3.中继器(物理层):
4.路由器(网络层):
5.服务器:
6.交换机(数据链路层):
7.ARP——地址解析协议
8.洪范
9.封装
10.解封装
11.PDU
12.IPV4报头
13.TTL
14.TCP/IP 模型
15.DNS——域名解析系统
16.节点(集线器)
17.MAC地址
18.网络变大的过程
三,OSI开放式系统互联参考模型
7.应用层 6.表示层
5.会话层
4.传输层
3.网络层
2.数据链路层
1.物理层
四,IP地址
1.IP地址
2.IP地址的分类
3.IP报头
五, 子网掩码
子网掩码的表示方法
六,子网划分:
七,子网汇总
一,HCIA简介: HCIA的全称为Huawei Certified ICT Associate,意思是华为认证ICT工程师,是华为公司打造的世界唯一覆盖ICT全技术领域的认证体系中的初级认证,表示通过认证的人员具备安装、配置、运行ICT设备,并进行故障排除的能力。
二,了解HCIA中的一些常用名词定义 1.计算机起源: 1946年2月14日 最早用于计算导弹弹道
2.网络: 网络是由网络连接设备通过传输介质将网络终端设备连接起来,进行资源共享,信息传递的平台。
网络连接设备——路由器、交换机
传输介质——网线、光纤、同轴电缆
网络终端设备——电脑 手机 PAD 电视 等...
3.中继器(物理层): 对衰减的信号进行放大,保持与原数据相同的设备
4.路由器(网络层): 连接互联网内局域网和广域网的设备
工作过程:
路由器接收到一段比特流后,先识别二层的数据帧;查看目标mac地址,然后判断丢弃或者解封装;解封装到3层后,关注目标ip地址,查询本地的路由表,若表中存在记录将无条件按照记录转发,若没有记录将丢弃该流量
5.服务器: 一台安装了服务器操作系统的电脑。
6.交换机(数据链路层): 交换机也称交换式集线器(网桥),是专门设计使各种计算机能够高速通信的独享带宽的网络设备
工作过程
交换机接收到一段比特流后,先识别二层数据帧,优先查看数据帧中的源mac地址,将其对应的进入接口映射后记录在本地的MAC地址表中,在关注数据帧中的目标MAC地址,基于本地MAC表查询,表中存在记录将按照记录单播转发,若没有记录将洪范该流量
Xshell是一款功能强大的终端模拟器,支持SSH1,SSH2,SFTP,TELNET,RLOGIN和SERIAL。通过提供业界先进的性能,Xshell包含了其他SSH客户端无法发现的功能和优势,作为新手,可能有很多不明白的地方,今天多多简单介绍一下Xshell和连接Linux服务器方法
支持SSH1,SSH2,SFTP,TELNET,RLOGIN和SERIAL协议
支持Windows Vista / 7/8/10,Server 2008/2012/2016
支持OpenSSH和ssh.com服务器
支持在单个窗口中具有多个选项卡
支持在单个窗口中显示多个选项卡组
多用户设置
保持活力选项
SOCKS4 / 5,HTTP代理连接
自定义键映射
VB,Jscript脚本
支持IPv6
支持Kerberos(MIT Keberos,微软SSPI)认证
SSH / Telnet跟踪
Xshell的特点: 1、界面设计简洁、人性,使用方便。
2、支持标签,打开多个服务器时候很方便,点击标签切换。
3、可以保存密码,注意安全,尽量不要保存,除非个人电脑。
Xshell如何远程连接Linux服务器 要想在Windows下远程连接Linux的ssh客户端,就需要借助像Xshell这样的终端模拟器软件,那么肯定会有人问,我有了这个软件的话,那要怎么操作才会使其远程连接Linux服务器?下面就一起来学习具体操作技巧。
具体步骤如下: ① 打开Xshell软件。双击桌面上的Xshell软件快捷图标,就可以打开软件,打开的软件主界面如下图所示。
② 执行新建命令。打开Xshell软件后找到左上角第一个“文件”菜单并单击,弹出来一个下拉框,点击选择“新建”命令(或者直接按下快捷键“Alt+n”)。
③ 点击“新建”之后就会出现下面这样一个界面,“名称”根据自己的需求填写,“协议”就是默认的SSH,“主机”是这一步最关键的,一定要填写正确,否则无法登录,端口也是默认的22,其他不用填,填写完成之后先不要点确定,看下一步。
④ 找到连接选项栏中的“用户身份验证”点击,点击之后会让你填写用户名和密码,其中“方法”默认“password”,“用户名”填写你的FTP用户名,“密码”填写你的FTP密码,填写完成点击确定 ⑤ 登录刚才保存的账号,单击左上角的“文件”菜单,在其下拉选项选择“打开”命令,弹出会话对话框,左下角有一个选项“启动时显示此对话框”,这个选项的意思是:每次打开Xshell都直接跳出这个对话框,根据需求勾选,然后找到你想登录的服务器,点击“连接”即可 连接之后出现如下界面中的[root@******]样式的,就证明连接成功了。 在使用的过程中一定要保证数据的安全,离开电脑或者不需要使用的时候,将其退出,更安全的方法是如果你服务器的“主机”“用户名”“密码”这三项记得很清楚的话,尽量不要保存账号密码,每次打开重新输入来进行连接
最后分享几个Xshell快捷键 Alt + N:新建会话
Alt + S:简单模式
Alt + R:透明模式
Alt + A:总在最前面
Alt + Enter:全屏
Alt + 1 :切到第一个会话,2,3,4…类推
Ctrl + Alt + F:新建传输文件
Ctrl + Shift + L:清屏
检查本地,相关的依赖都安装了,config配置没问题。后来发现,vite中不能使用require
文章目录 一、本地节点通信1.DNS2.joined容器3.端口映射4.不同网段的容器通信5.双冗余机制 二、跨主机容器通信1.相同网段进行通信2.补充 一、本地节点通信 1.DNS 容器之间除了使用ip通信外,还可以使用容器名称通信。docker 1.10开始,内嵌了一个DNS server。dns解析功能必须在自定义网络中使用。启动容器时使用 --name 参数指定容器名称。 2.joined容器 Joined容器一种较为特别的网络模式。在容器创建时使用- -network=container:vm1指定。(vm1指定的是运行的容器名)处于这个模式下的 Docker 容器会共享一个网络栈,这样两个容器之间可以使用localhost高效快速通信。 两个容器共享一个网络栈
[root@server7 ~]# docker run -d --name web1 --network my_net1 nginx
[root@server7 ~]# docker run -it --rm --network container:web1 --name web2 busybox
web1容器的ip为 172.17.0.2 ,我们使用joined网络模型再新建容器:
发现和web1容器一模一样,即指定的容器使用相同网络栈。需要注意的点是:这两个容器监听的端口不能是一样的。
3.端口映射 外部主机访问容器可以通过DNAT规则和docker-proxy,只要有一种正常就能通信
SNAT是源地址转换、DNAT是目标地址转换。
区分这两个功能可以简单的由服务的发起者是谁来区分,内部地址要访问公网上的服务时,内部地址会主动发起连接,将内部地址转换成公有ip。网关这个地址转换称为SNAT;当内部需要对外提供服务时,外部发起主动连接。路由器或着防火墙的网关接收到这个连接,然后把连接转换到内部,此过程是由带公有ip的网关代替内部服务来接收外部的连接,然后在内部做地址转换,此转换称为DNAT主要用于内部服务对外发布。
我们可以看到一条DNAT中重定向的策略:即外部访问本机的80端口时,会重定向到172.17.0.2 的80端口。这就是端口重定向机制,而docker中使用的是一种双冗余机制;
重启容器后,DNAT规则和docker-proxy策略会自动恢复
4.不同网段的容器通信 见上一篇总结!
5.双冗余机制 容器访问外网是通过iptables的SNAT(源地址转换)实现的
docker proxy:
外网访问容器用到了docker-proxy和iptables的DNAT(目标地址转换)
宿主机访问本机容器使用的是iptables DNAT
外部主机访问容器或容器之间的访问是docker-proxy实现
我们来进行双冗余测试:
我们先将iptables中的端口映射删掉:
但是此时外部仍然是可以访问的:
我们再把进程中的docker-proxy删掉:
在外部继续访问:已不能访问
这就是双冗余机制,只要有一种机制存在,就能运行。
本地容器之间的通信是通过网桥转发的,容器都连接的是docker0网桥:
重启后均会恢复
二、跨主机容器通信 跨主机网络解决方案
docker原生的overlay和macvlan
哥德巴赫猜想
描述 伟大的哥德巴赫猜想是:任何一个大于6的偶数总可以分解为两个素数之和。现在,请你 编程验证哥德巴赫猜想,即输人一个大于6的偶数n,将其分解为两个素数之和输出。如果有多种分解答案,请输出字典序最小的那一个
输入 一行一个正整数n,n<=1000。
输出 一行一个表达式,表示字典序最小的一种分解方法,具体格式参见样例。
输入样例 1 6 输出样例 1
6 = 3 + 3 提示
素数一般指质数。质数是指在大于1的自然数中,除了1和它本身以外不再有其他因数的自然数。
字典序:
在数学中,字典或词典顺序(也称为词汇顺序,字典顺序,字母顺序或词典顺序)是基于字母顺序排列的单词按字母顺序排列的方法。 这种泛化主要在于定义有序完全有序集合(通常称为字母表)的元素的序列(通常称为计算机科学中的单词)的总顺序。
对于数字1、2、3......n的排列,不同排列的先后关系是从左到右逐个比较对应的数字的先后来决定的。例如对于5个数字的排列 12354和12345,排列12345在前,排列12354在后。按照这样的规定,5个数字的所有的排列中最前面的是12345,最后面的是 54321。
下面这个代码,只要题目一样的话,百分百正确
#include<iostream> #include<cmath> using namespace std; int f(int n){ bool flag=1; for(int i=2;i<=sqrt(n);i++){ if(n%i==0){ flag=0; break; } } return flag; } int main(){ int n; cin>>n; for(int i=2;i<=n/2;i++){ if(f(i)==1 && f(n-i)==1){ cout<<n<<" = "<<i<<" + "<<n-i; break; } } return 0; } 答案正确
不同于图像分类,在物体检测任务中一幅图片上出现的目标数量和大小是任意的;与之相矛盾的是全连接层只能接受固定大小的输入。R-CNN首先提取建议区域(约2000),裁剪缩放到固定大小;然后将所有候选区域送入卷积网络进行分类和回归。显然,以上做法是非常耗时且低效的。候选区域之间存在大量重叠,这意味着提取的卷积特征包含大量冗余。
借助于RoI pooling,Fast R-CNN可以复用卷积特征。考虑到所有候选区域均位于一张图片上,Fast R-CNN对图像整体进行卷积。RoI pooling为每个候选区域提取固定大小的特征图。R-CNN在原始图像上进行裁剪,而Fast R-CNN在特征图上进行裁剪。
Fast R-CNN的网络结构如下图所示
源自Region of interest pooling in TensorFlow – example
Fast R-CNN实现了特征图共享,特征抽取仅需计算一次。RoI pooling进行自适应池化以利于后续网络的判别。
RoI pooling 兴趣区域池化(RoI pooling)是深度学习物体检测算法中常用的一种操作。其目的是对不等尺寸的输入执行最大汇集以获得固定尺寸的特征映射。
兴趣区域池化根据候选区域裁剪卷积特征图,然后用插值(通常是双线性的)将每个裁剪调整为固定大小(14×14×convdepth)。裁剪之后,用 2x2 核大小的最大池化来获得每个建议最终的 7×7×convdepth 特征图。
RoI pooling层需要两个输入:
特征提取网络(堆叠若干卷积和最大池层)馈送的特征映射。感兴趣区域列表( N × 5 N×5 N×5 矩阵,其中 N N N 是RoI的数量)。 列表的第一列表示图像索引,其余四个是该区域左上角和右下角的坐标:
[ i b a t c h , x m i n , y m i n , x m a x , y m a x ] [i_{batch}, x_{min}, y_{min}, x_{max}, y_{max}] [ibatch,xmin,ymin,xmax,ymax]
线性电源(LDO) 低压差线性稳压器(LDO)的基本电路如下所示,该电路由串联调整管VT、取样电阻R1和R2、比较放大器A组成。
对此的理解:
稳压管为运放反向端提供稳定的参考电压Uref, 输出端通过R2的分压提供运放同相端的电压。当输出电压过高时,同相端电压值大于反向端参考,输出为正值,因此三极管截止,Uout下降。当输出电压Uout过低时,同相端电压值小于反向端参考,输出为负值,因此三极管导通,Uout上升。因此,稳压电路就是通过这种机制不断调节输出电压,使其保持稳定。 取样电压加在比较器A的同相输入端,与加在反相输入端的基准电压Uref相比较,两者的差值经放大器A放大后,控制串联调整管的压降,从而稳定输出电压。
当输出电压Uout降低时,基准电压与取样电压的差值增加,比较放大器输出的驱动电流增加,串联调整管压降减小,从而使输出电压升高。
相反,若输出电压 Uout超过所需要的设定值,比较放大器输出的前驱动电流减小,从而使输出电压降低。
运放负端提供稳定的电压,运放正端通过输出电压由电阻网络分压得到。当输出电压高时,运放正端电压也高,比负端值大,运放输出为正,MOS管截止,OUT输出降低;
当输出电压低时,运放正端电压也低,比负端值小,运放输出为负,MOS管导通,OUT输出升高。
稳压芯片就是通过这种机制不断调整输出电压,使其稳定的。
学习更多硬件相关内容及最全设计资料下载,可关注微信公众号:启芯硬件
大家都知道,CPU是负责运算和处理的,而存储器则是负责交换数据的。有人是这么比喻的(场景是工程师的工作),说CPU就是工程师本人,内存就像是工作台,需要及时处理的东西需要先拿到工作台上才方便处理。那么硬盘是什么呢?硬盘就像柜子,存放电子器件仪器用的仓库,存东西。
存储器有两个基本的构成单元,SRAM 和 DRAM,充分理解这两个概念以及电路原理,对于学习应用CPU构架以及DDR非常有用。DRAM就是动态(Dynamic)随机存储器,SRAM是静态(Static)随机存储器。这一动一静的本质是什么呢?先说静态随机存储器,它是利用如D触发器的结构来完成数据的读取与写入的,资料的写入不需要刷新动作,这样不需要刷新动作的就成为静态。同时,这样使得控制器设计很简单,存取的速度比DRAM快很多。适合于高速存储的应用场景比如CPU的cache缓存。
理解了静态随机存储器之后,动态随机存储器就好理解了。动态就是指利用电容的充放电来实现资料的写入与读取动作,因为电容会慢慢放电,如果放电到阈值以下,数据可能就会丢失了,因此需要每隔一段时间来做刷新的动作,以保持资料的完整性。最常见的就是手机和电脑的内存了。
1 第一层认识—一个D触发器构成最简单 SRAM
首先,可以从最基础数字电路开始。有一个很基本但是深刻且直接的认识:SRAM cell最简单的构成单元就是一个D触发器,如下图所示,D触发器是数字电路系统里面的一个基本单元。
1 bit的SRAM单元的核心电路就是一个D触发器。当有power存在的时候,因为D触发器的特性,数据可以保存,不需要刷新。触发器是具有记忆功能的,具有两个稳定的信息存储状态。D触发器的特性方程是:Q(n+1)=D;也就是记忆前一个状态,可以从RS触发器出发,写一下真值表,推算就很好理解了。波形图如下所示:
2 第二层认识—4个单管构成的SRAM
然后,可以用基本晶体管层面来搭建一个简单的SRAM单元,仅仅由4个NMOS管和两个电阻构成的。
【电路详细分析】
SRAM的整个单元具有对称性。其中除了Q1和Q2的部分,是用来锁存1位数字信号。Q1,Q2是传输管,它们在对存储器进行读/写操作时完成将存储单元与外围电路进行连接或断开的作用。
对单元的存取通过字线WL(Word Line)使能,字线WL为高电平时传输管导通,使存储单元的内容传递到位线BL(Bit Line),单元信息的反信号传递到位线BL#,外围电路通过BL和BL#读取信息。
写操作时,SRAM单元阵列的外围电路将电压传递到BL和BL#上作为输入,字线WL使能后,信息写入存储单元。
3 第三层认识–6管单管构成的SRAM
最后,可以从IC的制造层面来看。其实,大部分与第二层差不多,只是M2与M4用PMOS代替。SRAM中的每一bit存储在由四个场效应管(M1, M2, M3, M4)构成两个交叉耦合的反相器中。另外两个场效应管(M5,M6)是存储基本单元到用于读写位线(Bit Line)的控制开关。
一个SRAM基本单元有0和1两个电平稳定状态。SRAM 基本单元由两个CMOS反相器组成。两个反相器的输入、输出交叉连接,即第一个反相器的输出连接第二个反相器的输入,第二个反相器的输出连接第一个反相器的输入。这就能实现两个反相器的输出状态的锁定、保存,即存储了一个位元的状态。分析简图:
【详细的电路分析】
SRAM的基本单元存在三种状态:standby(空闲),read(读)和write(写)。
第一种状态:standby
如果WL没有选为高电平,那么M5和M6两个作为控制用的晶体管处于断路状态,也就是基本单元与位线BL隔离。而M1-M4组成的两个反相器继续保持其状态。
第二种状态:read
首先,假设存储的内容为1,也就是Q处为高电平。读周期初始,两根位线BL, BL#预充值为高电平,因为读写状态时,WL也会为高电平,使得让作为控制开关的两个晶体管M5, M6导通。
然后,让Q的值传递给位线BL只到预充的电位,同时泄放掉BL#预充的电。具体来说,利用M1和M5的通路直接连到低电平使其值为低电平,即BL#为低;另一方面,在BL一侧,M4和M6导通,把BL直接拉高。
第三种状态:write
写周期开始,首先把要写入的状态加载到位线BL,假设要写入0,那么就设置BL为0且BL#为1。然后,WL设置为高电平,如此,位线的状态就被载入SRAM的基本单元了。具体分析过程,可以自己画一下。
学习更多硬件相关内容及最全设计资料下载,可关注微信公众号:启芯硬件
关键技术之一—差分时钟
差分时钟是DDR的一个非常重要的设计,是对触发时钟进行校准,主要原因是DDR数据的双沿采样。由于数据是在时钟的上下沿触发,造成传输周期缩短了一半,因此必须要保证传输周期的稳定以确保数据的正确传输,这就对CK的上下沿间距有了精确的控制的要求。一般说来,因为温度、电阻性能的改变等原因,CK上下沿间距可能发生变化,此时与其反相的CK#就起到纠正的作用,因为,CK上升沿快下降沿慢,CK#则是上升沿慢下降沿快。也就是,与CK反相的CK#保证了触发时机的准确性。
关键技术之二—数据选取脉冲(DQS)
DQS是DDR SDRAM中的另一项关键技术,它的功能是用来在一个时钟周期内准确的区分出每个传输周期,并便于接收方准确接收数据。每一颗芯片都有一个DQS信号线,它是双向的,在写入时它用来传送由芯片发来的DQS信号,读取时,则由内存生成DQS向芯片发送。因此可以认为DQS就是数据的同步信号。
我们知道DDR之前的SDR就是使用clock来同步的,因此理论上,DQ的读写时序完全可以由clock来同步。但是,由于速度提高之后,可用的时序余量越来越小,而引入DQS是为了降低系统设计的难度和可靠性,也就是可以不用考虑DQ和clock之间的直接关系,只用分组考虑DQ和DQS之间的关系,很容易同组同层处理。
DQ和DQS只是组成了源同步时序的传输关系,可以保证数据在接收端被正确的所存,但是IC工作时,内部真正的同步时钟是clock而不是DQS,数据要在IC内部传输存储同样需要和clock(内部时钟比外部时钟慢)去同步,所以就要求所有的DQ信号还是同步的,而且和clock保持一定的关系,所以就要控制DQS和clock之间的延时了。
在写入时,以DQS的高/低电平期中部为数据周期分割点,而不是上/下沿,但数据的接收触发仍为DQS的上/下沿。
关键技术之三—延迟锁定回路(DLL)
第三个关键技术是DLL技术,也就是延迟锁定回路。需要这种技术的原因是,内外时钟的不同步问题。内外时钟不同步在SDRAM中就存在了,不过因为它的工作/传输频率较低,所以内外同步问题并不突出。但是,DDR SDRAM对时钟的精确性有着很高的要求,而DDR SDRAM有两个时钟,一个是外部的总线时钟,一个是内部的工作时钟,在理论上DDR SDRAM这两个时钟应该是同步的,但由于种种原因,比如温度、电压波动而产生延迟使两者很难同步,更何况时钟频率本身也有不稳定的情况。我们熟悉的DDR SDRAM的tAC就是因为内部时钟与外部时钟有偏差而引起的,它很可能造成因数据不同步而产生错误。
怎么解决呢?实际上,因为不同步就是一种正/负延迟,如果延迟不可避免,那么若是设定一个延迟值,如一个时钟周期,那么内外时钟的上升与下降沿还是同步的。鉴于外部时钟周期也不会绝对统一,所以需要根据外部时钟动态修正内部时钟的延迟来实现与外部时钟的同步,这就是DLL的任务。
DLL主要的目的就是生成一个延迟量给内部时钟,来补充正负不同步造成的正负延迟。
有了这些技术就构成了内存帝国的最基本的元素,之后的DDR2,DDR3和DDR4以及即将推出的DDR5将以此为基础,内存的功耗及频率得到一次又一次的飞跃。
学习更多硬件相关内容及最全设计资料下载,可关注微信公众号:启芯硬件
代码如下
r1:
<Huawei>sys
[Huawei]sys r1
[r1]int g 0/0/1
[r1-GigabitEthernet0/0/1]ip add 12.1.1.1 24
[r1-GigabitEthernet0/0/1]int lo0
[r1-LoopBack0]ip add 1.1.1.1 24
[r2]ospf 1 router-id 2.2.2.2
[r2-ospf-1]ar 0
[r2-ospf-1-area-0.0.0.0]network 23.1.1.0 0.0.0.255
[r2-ospf-1-area-0.0.0.0]network 2.2.2.0 0.0.0.255
[r1]bgp 1
[r1-bgp]router-id 1.1.1.1
[r1-bgp]peer 12.1.1.2 as-number 2
[r1-bgp]net 1.1.1.0 24
r2:
<Huawei>sys
[Huawei]sy r2
[r2]int g 0/0/0
[r2-GigabitEthernet0/0/0]ip add 12.1.1.2 24
[r2-GigabitEthernet0/0/0]int g 0/0/1
[r2-GigabitEthernet0/0/1]ip add 23.1.1.1 24
[r2-GigabitEthernet0/0/1]int lo0
[r2-LoopBack0]ip add 2.2.2.2 24
[r2]bgp 2
[r2-bgp]router-id 2.2.2.2
文章目录
前言
一、下载Tomcat及解压
1、选择下载版本(本文选择tomcat 8版本为例)
2、解压安装包
二、配置环境
1、在电脑搜索栏里面搜索环境变量即可
2、点击高级系统设置->环境变量->新建系统变量
1) 新建系统变量,变量名为CATALINA_HOME
2)找到系统变量Path,双击空白处或新建即可在末尾加上%CATALINA_HOME%\bin
三、验证是否配置成功
1、进入Windows命令行窗口(win+R,输入cmd,回车)
2. 解决方法
总结
前言 本文主要讲解tomcat 8.5 的版本安装教程,以及一些常见的问题解答
一、下载Tomcat及解压 Apache Tomcat® - Welcome!官网:Apache Tomcat® - Welcome!
1、选择下载版本(本文选择tomcat 8版本为例) 下载64-Bit Windows zip(Win64)
2、解压安装包 之后选择解压到任意一个盘,此处解压到D盘,解压的路径一定要记住,后面系统环境变量配置的时候要用到。
二、配置环境 1、在电脑搜索栏里面搜索环境变量即可 2、点击高级系统设置->环境变量->新建系统变量 1) 新建系统变量,变量名为CATALINA_HOME 变量值为解压文件夹的路径,即你解压的路径
2)找到系统变量Path,双击空白处或新建即可在末尾加上%CATALINA_HOME%\bin 三、验证是否配置成功 上面操作已经完成配置了,但不代表着就已经成功完成配置了
1、进入Windows命令行窗口(win+R,输入cmd,回车) 输入startup.bat回车,可依次看到如下画面
很明显弹出的Tomcat出现了乱码
此处小编安装时忘记截图了,截取了一个网图
解决方案
打开apache-tomcat-8.5.91->conf->logging.properties
用记事本打开logging.properties找到下图那一行代码
改为
java.util.logging.ConsoleHandler.encoding =GBK 即把UTF-8改为GBK
下图就是改完之后的正确显示
接下来就可以验证是否配置成功了
牢记,Tomcat窗口不能关闭!
牢记,Tomcat窗口不能关闭!
牢记,Tomcat窗口不能关闭!
不能关闭的原因是:关闭之后Tomact服务器也就关闭了,你无法查看Web页面
打开游览器输入网址
http://localhost:8080/ 什么是8080?
因为tomcat默认的端口号就是8080。
但很多人试之后会发现网页无法打开
小编的是这种情况:
成功的画面如下
什么是熔断 分布式系统都是由多个微服务构成,一个接口调用过程会存在很长的服务调用链。一旦调用链上某服务挂掉或者响应时间很长,会导致整个调用链响应缓慢,严重点的话,就可能导致系统全面崩溃,这就是服务雪崩。
为了防止服务雪崩,在被调用的服务出现故障时,调用方主动停止调用,这种行为成为服务熔断。
熔断器工作状态 熔断器一般分为以下3个工作状态:
1.关闭状态(closed)
熔断器正常情况下处于关闭状态
2.开启状态(open)
熔断器包含计数器功能,每次调用失败,计数器就会累积加1,超过一定次数,熔断器就会处于开启状态。开启状态下,任何请求都会直接被拒绝并抛出异常。
3.半开启状态(half open)
熔断器开启后,内部会启用一个计时器,计时器倒计时完毕,就会切换到半开启状态。该状态下,会允许部分请求。如果请求全部正常,状态变为Closed。如果有任一请求失败异常,重新变为开启状态。
什么是服务降级 服务降级是在高并发情况下,应对服务器压力剧增的情况,对某些边缘服务与页面进行停用或者屏蔽,释放计算机资源用来确保核心服务的平稳运行。
举个栗子,公司总共四台服务器,两台用来进行下单业务,另外两台用来进行服务评价、商品推荐。双11活动来了,公司的商品卖爆了。为了确保下单业务的正常,把服务评级与商品推荐功能停了。四台服务器全部用来供应订单业务,这就叫做服务降级。
服务降级分类 自动开关降级 响应时间超时降级请求响应时间过长引起自动降级失败次数大于设定阈值降级设定一个阈值,失败次数大于阈值自动降级故障降级降级发生网络故障或者服务器彻底崩了,服务自动降级,返回默认页面,缓存的数据等。限流降级降级商品秒杀功能设定流量阈值,到达限流阈值后展示排队页面,错误页面等。 人工开关降级 在进行双十一这些商品促销活动前,预估流量非常大,开发人员手动对某个功能进行降级。人工开关降级不一定是人在操作,可能是设置了定时任务,到点后自动触发服务降级。
大型分布式系统下的服务降级步骤 1.产品经理与开发梳理核心业务(不能降级)与非核心业务
2.指定降级策略,服务降级的先后顺序、流量的阈值与熔断的阈值等。
熔断与服务降级的区别 熔断涉及到因为服务不可用所引起的故障。
服务降级是因为系统资源有限情况下,从功能优先级考虑,采用延迟执行,异步执行或者默认值返回的策略。
常用的熔断降级工具有哪些 市面上常见的熔断降级工具有Hystrix、resilience4j、Sentinel
1.Hystrix 目前已停止开发新功能,处于维护状态。最后一个版本是2018年发布的
2.Resilience4j Hystrix停止开发后,Netflix官方推荐使用的熔断降级工具。
3.Sentinel 阿里自研的开源熔断降级工具,sentinel的官方文档有它与Hystrix的对比图
场景如下:一共三个线程a,b,c,其中c需要用到a,b,执行的结果,应该怎么处理? 1)CountDownLatch,主线程中调用await方法,每个线程调用countdown 上面两种方法需要分别调用多次join或future的get方法,不太好,有一种方法是使用CountDownLatch类
认知CountDownLatch的方法:
await():阻塞主线程,直到countDownLatch的计数器减少到0的位置,
countDown:将当前的计数器减1
getCount:返回当前的数
思路如下:让a,b线程使用CountDowmLatch,然后执行countDownLatch的await方法
主类:
public static void main(String[] args) {
CountDownLatch countDownLaunch = new CountDownLatch(5);
for(int i=1;i<6;i++){
ThreadWithCountDownLatch threadWithCountDownLatch = new ThreadWithCountDownLatch(i*1000L,countDownLaunch,"THREAD"+i);
Thread thread = new Thread(threadWithCountDownLatch);
thread.start();
}
mainThreadWork();
try {
countDownLaunch.await();//下面的代码要等待所有的countDown的计数器为零再执行
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("all done"); }
线程类:
public class ThreadWithCountDownLatch implements Runnable{
long time;
CountDownLatch countDownLatch;
String name;
public ThreadWithCountDownLatch(long time,CountDownLatch countDownLatch,String name){
实验拓扑如需,可联系作者!本人博客除特别声明外,均属原创,未经作者允许,禁止转载!如需转载请联系作者并注明出处,附带本文链接! 注意!!AR1的RIP中,配置应为filter-policy 2000 export笔记中写错了方向
以上内容均属原创,如有不详或错误,敬请指出。 本文作者: 坏坏 本文链接: https://blog.csdn.net/qq_45668124/article/details/107716617 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请联系作者注明出处并附带本文链接!
症状:1.写文档的时候,没过几秒就发现输入不上了,需要重新点一下窗口才能继续输入。
2.不论啥窗口都是过一小会儿就会变成灰的(未聚焦)
解决方案:更改注册表信息
1.打开运行,输入regedit,进入注册表
2.找到HKEY_CURRENT_USER\Control Panel\Desktop
3.右边找到ForegroundLockTimeout
4.修改数据值为30d40(选择十六进制改为30d0,选择十进制改为200000)
5.保存退出,关机重启
补充一个win10任务栏卡顿闪退问题解决方案:右键任务栏,关闭资讯。
本人是一个软件测试小白,自己在研究自动化测试时,真的入了不少坑,直到现在,可能才勉强将环境搭建了起来。
在此,我随随便便总结了一下基于java的selenium自动化测试环境搭建,送给正在学习软件测试的你,也就当自己做了个笔记,防止下次忘记。
不过,熟练之后应该也就不会忘记了,所以,开始自学时要多练呢,小伙伴们!!!
1.安装配置eclipse环境 我想大家配置eclipse应该是分分钟的事,我也就不多啰嗦了
(1)在官网上下载eclipse安装包,解压;
(2)在官网下载jdk,配置环境变量:
JAVA_HOME: jdk文件所在目录; path:%JAVA_HOME%\bin或者C:\Program Files\Java\jdk1.8.0_111\bin (3)配置完成后,在cmd控制台中输入java -version,如果出现版本信息等内容,则证明配置成功。
2、配置maven环境 使用maven的目的是不用导入selenium的jar包,可以在maven的pom文件中添加依赖,直接下载jar包,用起来比较方便。
(1)在官网下载maven文件,后缀为zip的包,将文件解压;
(2)配置maven环境变量;
MAVEN_HOME:maven文件所在目录 path:%MAVEN_HOME%\bin 此时maven已经安装成功,我们需要在cmd中输入mvn -version检查一下,出现版本信息则证明安装成功。
3、在eclipse中添加maven (1)点击window→preference进入对话框页面,在进入UserSettings设置页面,如图选择settings.xml文件和本地仓库的绝对路径。点击Apply→OK
(2)测试maven是否安装成功,打开eclipse选择上面菜单“File”–>“New”–>“Project”选择创建“Maven Project”项目试试。如下图表示配置完成:
4、在eclipse中添加testng。 运用testng的目的是方便管理用例,需要执行哪个用例就执行哪个,而不是全部执行,同时testng要在pom文件中添加依赖,这样方便jenkins中执行pom文件时可以执行测试用例。
(1)打开我们的Eclipse,点击Help ->Install New Software,如图:
(2)点击右上角的Add按钮,在弹出来的对话框中填入如下内容。Name:testNG location: beust.com/eclipse ,点击OK. 勾选testNG,然后点击next进行下一步的操作直至完成。
(3)进度条完成之后,应该已经成功。验证是否安装成功,重新启动Eclipse,点击file–>new–>other–>testNG.出现如下图所示即为安装成功。
5、编写代码示例 我这里就比较简单介绍一下我的操作步骤。
(1)新建一个maven项目(怎么新建请自行百度)
我的目录结构如图所示
下面是我的用例代码的编写,写个三个Test,从注解就能看出来。当然中间牵扯到调用其他类、调用文件、继承其他类等问题,我就不全部粘贴出来了
@Test //打开首页 public void openPage(){ driver.get(“这里是打开的地址”); waitTime(2000); driver.manage().window().maximize(); waitTime(2000); } @Test(dependsOnMethods={"openPage"}) //账号登录 public void Login(){ this.propertiesfile(); WebElement name = driver.findElement(By.id(prop.getProperty("user"))); name.sendKeys(prop.getProperty("uservalue")); waitTime(1000); WebElement passwo = driver.findElement(By.id(prop.getProperty("passwo"))); passwo.sendKeys(prop.getProperty("passwovalue")); waitTime(1000); WebElement Loginbutton = driver.
报错如下:
我简单的查了一下说是因为权限不够,导致不能安装。win+x 选择终端管理员。
解决办法:
1、win+x 选择终端管理员
2、使用安装命令即可:msiexec /package "D:\MongoDB\mongodb-windows-x86_64-6.0.8-signed.msi"
3、文件存放地址
4、然后直接下一步下一步就行
5、连接数据库
6、连接上了之后,浏览器输入:127.0.0.1:27017
希望对你有所帮助,谢谢~
目录
一、zabbix自定义监控数据库
1、编写监控脚本
2、服务端测试
3、web页面配置
①创建自定义监控项
②创建触发器
③创建图形 ④测试自定义监控是否成功
二、zabbix自动注册
1、什么是自动注册
2、环境准备
3、 zabbix客户端配置
4、web页面配置自动注册
5、验证自动注册
三、代理服务器部署
1、代理服务器作用
2、部署环境
3、代理服务器配置
4、客户端配置
5、web页面配置
①删除原环境
② 添加代理
③创建主机 ④重启服务
6、验证结果
一、zabbix自定义监控数据库 1、编写监控脚本 首先在被监控服务器的子配置文件路径中编写监控脚本
cd /etc/zabbix/zabbix_agent2.d #进入agent2的子配置文件,本实验为yum安装为zabbix_zagent2客户端 vim mysql.conf #创建一个新的mysql.conf子配置文件,名称无所谓但是结尾必须以.conf结尾,主配置文件中有规定,yum安装的主配置文件目录为 /etc/zabbix/zabbix_agent2.conf #添加内容如下 UserParameter=lhj.user,netstat -antp | grep 3306 |wc -l #UserParameter为键名,此键名不可随意更改主配置文件中有要求 #lhj.user为键值,键值可以自定义 #,后的为此键值的内容,可以是一个有标准输出的命令也可以直接写执行某个脚本,执行脚本注意权限问题 systemctl restart zabbix-agent2.service #保存脚本内容后重启zabbix客户端 2、服务端测试 服务端测试是否可以监控到自定义键值的内容
服务端: yum install -y zabbix-get #安装zabbix主动获取命令 zabbix_get -s '192.168.30.12' -p 10050 -k 'lhj.user' #-s表示指定客户端ip -p表示指定客户端端口 -k 指定测试那个键值,返回结果为脚本命令输出结果即可以进行监控 3、web页面配置 ①创建自定义监控项 选择要监控的主机创建监控项,如何添加主机请看此博客分布式系统监控zabbix安装部署及使用_阿杰。159的博客-CSDN博客 在配置--主机中找到要监控的主机,点击监控项然后点击创建监控项 ②创建触发器 在配置--主机中找到要监控的主机,点击触发器然后点击创建触发器添加规则
t_0002 :: TC-11131: �Manage Device/My DTEN 项目�称/setting】... [ ERROR ] Tried:
1. File->Settings->Editor->File Encondings
Project Encoding(UTF-8->GBK)
Global Encoding(UTF-8->GBK)
未能解决
电脑系统中文字符 均显示为乱码 解决办法:
电脑-> 设置-> 时间和语言-> 区域,其他如下设置,设置后,重启电脑,电脑乱码显示问题解决。
Uncheck Beta
最近在寻找从kafka读取数据,同步数据写入ElasticSearch中的通用ELK方案。其中 logstash最方便简单,总结一下。
安装 下载
下载位置
Past Releases of Elastic Stack Software | Elastic
注意:下载版本和ElasticSearch的版本保持一致。es版本可以通过http://ip:9200/ 查看。
管道配置 Logstash管道通常有三个阶段:输入(input)→ 过滤器(filter)→ 输出(output)。输入生成事件,过滤器修改它们,输出将它们发送到其他地方。
input 读取kafka数据 input { kafka { bootstrap_servers => "192.168.10.153:9092" group_id => "logstash_test" auto_offset_reset => "latest" topics => ["log_info"] codec => json { ##添加json插件 charset => "UTF-8" } } } LogStash多实例并行消费kafka 1.设置相同topic
2.设置相同groupid
3.设置不同clientid
4.input 的这个参数 consumer_threads => 10 多实列相加最好等于 topic分区数
如果一个logstash得参数大于topic,则topic数据都会被这个logstash消费掉
配置示例:
input { kafka { bootstrap_servers => "192.168.10.153:9092" group_id => "
常用类--String 练习一 package String; import java.io.UnsupportedEncodingException; public class Demo01 { public static void main(String[] args) throws UnsupportedEncodingException { //字符串连续字符组成形成的数据整体 //java.lang.String String name = "zhengsan"; String name1 = new String("zhangsan"); char[] cs = {'a','中','国'}; byte[] bs = {-28,-72,-83,-27,-101,-67}; String s = new String(cs); String s1 = new String(bs,"UTF-8"); System.out.println(s1); String a = "\""; //\,\t,\n,\\ System.out.println(a); } } 练习二 package String; import java.
PWN是一个黑客语法的俚语词,自"own"这个字引申出来的,这个词的含意在于,玩家在整个游戏对战中处在胜利的优势,或是说明竞争对手处在完全惨败的情形下,这个词习惯上在网络游戏文化主要用于嘲笑竞争对手在整个游戏对战中已经完全被击败(例如:“You
just got pwned!”)。有一个非常著名的国际赛事叫做Pwn2Own,即通过打败对手来达到拥有的目的。
在CTF中PWN题型通常会直接给定一个已经编译好的二进制程序(Windows下的EXE或者Linux下的ELF文件等),然后参赛选手通过对二进制程序进行逆向分析和调试来找到利用漏洞,并编写利用代码,通过远程代码执行来达到溢出攻击的效果,最终拿到目标机器的shell夺取flag。
又到了介绍工具的时候了!首先了解一下gdb。
gdb是Linux下常用的一款命令行调试器,拥有十分强大的调试功能。本实验中需要用到的gdb命令如下:
这个工具类似逆向里面的IDA这类的神器。
除了工具还需要知道一些简单的汇编基础,读懂常见的汇编指令是CTF竞赛中PWN解题的基本要求,本实验中需要理解的汇编指令如下:
汇编语言中,esp寄存器用于指示当前函数栈帧的栈顶的位置,函数中局部变量都存储在栈空间中,栈的生长方向是向下的(即从高地址往低地址方向生长)。
缓冲区溢出是指当计算机向缓冲区内填充数据位数时超过了缓冲区本身的容量,使得溢出的数据覆盖在合法数据上,理想的情况是程序检查数据长度并不允许输入超过缓冲区长度的字符,但是绝大多数程序都会假设数据长度总是与所分配的储存空间相匹配,这就为缓冲区溢出埋下隐患。
本文涉及知识点实操练习:
[《CTFPWN练习》](https://www.hetianlab.com/expc.do?ec=ECID172.19.104.182014103116591300001&pk_campaign=freebuf-
wemedia)(PWN是CTF竞赛中的主要题型之一,主要考查参赛选手的逆向分析、漏洞挖掘以及Exploit编写能力。CTF-
PWN系列实验以最常见的栈溢出为主线,通过由浅入深的方式,一步一步讲解栈溢出攻击原理与实践,同时详细介绍了Linux下GDB调试器的基本使用方法。)。
先看题目描述,跟看web源码一样重要,主机/home/test/1目录下有一个pwn1程序,执行这个程序的时候可以输入数据进行测试,pwn1程序会输出Please
try again.的提示信息,请对pwn1程序进行逆向分析和调试,找到程序内部的漏洞,并构造特殊的输入数据,使之输出Congratulations,
you pwned it.信息。
首先第一步源码审计在实际的CTF竞赛的PWN题目中,一般是不会提供二进制程序的源代码的。这里为了方便大家学习,给出二进制程序的C语言源代码供大家分析,以源码审计的方式确定漏洞所在位置,方便后续进行汇编级别的分析。
(在没有源代码的情况下,我们通常使用IDA Pro对二进制程序进行逆向分析,使用IDA的Hex-
Rays插件可以将反汇编代码还原为C语言伪代码,可以达到类似源代码的可读效果,在后期的实验中会专门对IDA的使用进行讲解)
使用cd /home/test/1切换到程序所在目录,执行cat pwn1.c即可看到源代码:
``#include <stdio.h>int main(int argc, char argv){int modified;char buffer[64];modified = 0;gets(buffer); // 引发缓冲区溢出if (modified != 0){printf(“Congratulations, you pwned it.\n”);}else{printf(“Please try again.\n”);}return 0;}
我们看这里使用gets函数读取输入数据时,并不会对buffer缓冲区的长度进行检查,输入超长的输入数据时会引发缓冲区溢出。 漏洞找到了,我们来看利用过程执行gdb pwn1即可开始通过gdb对pwn1进行调试,现在我们需要阅读main函数的汇编代码,在gdb中执行disas main命令即可: 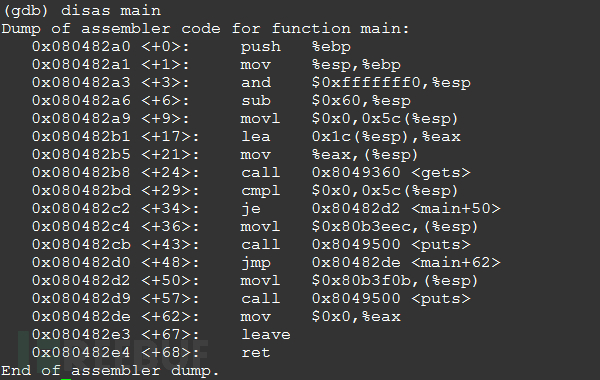 下面是对main函数中的汇编代码的解释: ``0x080482a0 <+0>: push %ebp0x080482a1 <+1>: mov %esp,%\ebp0x080482a3 <+3>: and $0xfffffff0,%\esp; esp = esp - 0x60,即在栈上分配0x60)字节的空间0x080482a6 <+6>: sub $0x60,%\esp; modified变量位于esp + 0x5C处,将其初始化为00x080482a9 <+9>: movl $0x0,0x5c(%\esp); buffer位于esp + 0x1C处0x080482b1 <+17>: lea 0x1c(%\esp),%eax0x080482b5 <+21>: mov %eax,(%\esp); 调用gets(buffer)读取输入数据0x080482b8 <+24>: call 0x8049360 <gets>; 判断modified变量的值是否是00x080482bd <+29>: cmpl $0x0,0x5c(%\esp); 如果modified的值等于0,就跳转到 0x080482d20x080482c2 <+34>: je 0x80482d2 <main+50>; modified不为0,打印成功提示0x080482c4 <+36>: movl $0x80b3eec,(%\esp)0x080482cb <+43>: call 0x8049500 <puts>0x080482d0 <+48>: jmp 0x80482de <main+62>; modified为0,打印失败提示0x080482d2 <+50>: movl $0x80b3f0b,(%\esp)0x080482d9 <+57>: call 0x8049500 <puts>0x080482de <+62>: mov $0x0,%\eax0x080482e3 <+67>: leave0x080482e4 <+68>: ret`` `` 通过对上面的汇编代码进行分析,我们知道buffer位于esp+0x1C处,而modified位于esp+0x5C处,两个地址的距离为0x5C - 0x1C = 0x40,即64,刚好为buffer数组的大小。因此当我们输入的数据超过64字节时,modified变量就可以被覆盖。 下面在gdb中进行验证,在gdb中执行b 0x080482bd命令对gets的下一条指令下一个断点: !
从最简单的程序开始 python的变量、数据类型和运算第一个python指令print()的使用python中的变量python里的数据类型数据的运算数值运算:即把整数或浮点数进行四则运算逻辑运算:即判断命题的真假,计算结果为布尔值字符串的运算2个以上的字符串拼接返回字符串字数 python的变量、数据类型和运算 第一个python指令print()的使用 print()的用途是打印输出
输出对象可以是字符也可以是数字,也可以是变量的值和运算结果
# 输出数字 print(123) # 输出字符,字符的输出必须把需要输出的字符放在成对的双引号"输出的字符"或单引号内部'输出的字符' print("name") print('name') # 单/双引号的意义是一样的,只是在某些字符串中如果带有'的话,那么你就只能使用双引号了 print("I'm a boy!") 但我们有多个字符或数字需要使用print()输出时,你可以这样使用
print('name:','Tom',"age:",18) 运行的结果: name: Tom age: 18 # 你会发现它们时在同一行上 # 如果你用多个print(),例如: print("name:","Tom") print('age:',18) 运行结果: name: Tom age: 18 #每一次print()运行后自带换行,除非你在最后写上end = '',end等于一个空值 print("name:",end = "") print("Tom") 运行结果: name: Tom 也许你会想,有没有简单一点的多行显示方式,不需要打很多的print(),比如我要输出一首诗词的时候:
print(''' 白日依山尽,黄河入海流。 欲穷千里目,更上一层楼。 ''') 最后,你可以试试如下代码:
name = 'Tom' age = 18 print(name,age) # 你会发现输出了Tom 18 # 那么对于这里的name和age为什么没有分别在两端加双引号或是单引号呢?程序为什么没报错? 这是因为它们是变量
python中的变量 变量的意思不难理解,从当中的“变”字就可以知道,它讲的就是可以变化的或者是可改变的,与之对立的就是常量
根据需求,我们可以自己定义变量,这在一个程序中非常有用,形式也是多种多样,但基本的组成结构是不变的,它由
变量名,即变量的名称赋值符号,即“=”等号变量的值 几个部分组成:变量名 = 变量的值
目录标题 基本用户认识用户的切换susu -exitsu 用户名sudo 基本用户认识 在linux系统中将用户分为两个大类一个是root用户一个是普通用户,root用户是linux操作系统的超级管理员,相当于古代的皇帝不会受到任何的权限约束,而普通用户就会受到权限约束相当于古代的老百姓。那么在后期的学习里面我们就不要使用root用户来执行操作了,因为普通老百姓犯错一般都可以挽回没有什么大问题,但是皇帝犯错一般就很难挽回了,所以在以后的学习当中我们都使用普通用户。
用户的切换 我们知道linux操作系统中有很多的用户,在平时的使用过程中肯定得需要将用户进行转换,比如说普通用户转为root用户,root用户转为普通用户,那我们如何来实现这些转换呢?这里就得需要用到下面的这些指令:
su 第一个指令就是su,这个指令的功能就是将普通用户切换成root用户,比如说下面的操作:
首先我们登录的用户是xbb,并且当前所在的路径是xbb的家路径,然后我们单独输入一个su就会出现下面的现象:
这里我们得输入root用户的密码才能实现对应的转化,将密码输入成功后就会出现这样的现象:
用户变成了root,但是切换后所在的路径依然是之前那个用户所在的路径。那么这就是一种切换的方式。
su - su -的功能也是将普通用户切换成root用户,但是这里切换后的路径就不再是之前用户所在的路径,而是root的家目录比如说下面的操作:
一开始的用户为xbb,所在的路径为家目录中的folder1目录里面,我们使用su -指令转换用户输入密码后就可以发现此时的路径为root用户的家路径,并且当前用户切换成了root,那么这就是su -和su的区别,两者切换后的路径不同su -会来到root的家路径,而su是原来用户所在的路径。
exit 当我们想从root用户切换回原来的普通用户时就可以使用exit指令,比如说下面的操作:
一开始我们登录的用户是xbb,使用su -切换到root用户之后再使用exit指令就可以切换回原来的xbb用户,并且退回之后的路径也是之前普通用户所在的路径。
su 用户名 如果我们当前是普通用户,想转换到另外一个普通用户的话就可以在su指令后面加上对应的用户名,但是这里的转换得输入另外一个普通用户的登录密码,比如说下面的操作:
一开始的用户为xbb使用su转换到wj用户时就得输入wj用户的登录密码,并且这里的转换是原路径转换如果想在转换时切换到家路径的话,就得在用户名前面加个-选项,比如说下面的操作:
如果我们当前是root用户想转换成普通用户的话就不用输入对应普通用户的登录密码,比如说下面的操作:
就可以直接转换不需要输入密码,如果我们这里想转换的时候顺便切换路径的话就可以使用在前面加个- 选项,比如说下面的操作:
那么这就是su+用户名的用法,希望大家可以理解。
sudo 当我们是普通用户但是想以root的身份执行一条指令的话,可以先将用户切换成root用户再执行相应的指令,那如果我们不想将用户进行切换成root呢?这里就可以使用sudo指令来进行提权,这里提权的时候会输入密码,这里的密码是当前用户的登录密码,并不是root的登录密码,比如说我现在的身份是wj,使用sudo提权执行指令时就得输入wj的登录密码,才可以执行比如说下面的操作:当我们使用一次sudo提权成功的话,在后面的一段时间里面再使用sudo是不需要再输入密码的,可以直接使用但是有些小伙伴在使用这个指令的时候会出现提权失败的情况比如说下面的操作:
这是因为我们当前使用用户不是系统的受信任的用户,如果说每个人都可以使用root来进行提权操作各种只有root才能执行的操作的话,那我每个指令都用root来进行提权的话我不就相当于是root了吗?所以在使用sudo指令的时候就多了一个门槛,你得是系统的受信任用户这样你才能正常的执行sudo指令,那么我们可以通过下面的操作来添加受信任用户,首先登录root的账号:
打卡这个文件: /etc/sudoers
按下回车就会出现这样的界面:
我们通过底行模式来添加行号,然后在100行左右找到 Allow root to run any commands anywhere :
然后我们将这句话下面一行的内容复制一下就是这句话:root ALL=(ALL) ALL,然后再在粘贴到下一行上去:
然后将你刚刚复制出来的内容中的root修改成你想要的普通用户比如说xbb
然后再进入底行模式中输入w!强制写入,再输入q!强制退出,这样我们添加受信任的用户的操作就完成了,然后我们再将用户切换成xbb,然后使用sudo提权指令whoami的话就可以发现可以执行了
那么这就是用户切换的全部内容,希望大家可以理解。
安装Python python的环境部署python编译器的获取python适合做什么?搭建python的开发环境Windows安装Pythonlinux下安装python 常用工具介绍PyCharm简介VS Code简介 Python的中文翻译是“蟒蛇”,但python的名字由来可不是因为它是一个很酷的动物,而是因为它的开发者Guido van Rossum喜欢一部喜剧的名字叫"Monty Python’s Flying Circus"《蒙提 派森的飞行马戏团》。
它诞生于1989年的圣诞节,因为龟叔闲的无聊了,所以为了打发时间,就有了它。
大神就是大神……既可爱又任性。
python的环境部署 学习计算机高级编程语言,总逃不开需要在自己的电脑里安装配置对应的开发环境,或者说是适合这种语言程序运行的环境。
而python作为一种解释型的编程语言,它的工作方式是通过解释器逐句逐句的对程序执行。
这过程就是像是在某个会议中,会议的发言使用的是中文,而参加会议的人员中有一个听不懂中文的老外,那我们就会为这老外配一名翻译,发言者说一句话就翻译一句,让老外事实的明白会议中在讲什么。
这个老外就是我们的电脑,而解释器就是那个翻译,要让计算机按照我们的意愿开始工作,就得让它听懂我们说的话。
python编译器的获取 作为一门开源的编程语言,它的编译器获取途径很多,但建议大家记住它的home地址:
https://www.python.org/
在这个网站上,你可以找到历来的Python版本,但要注意的是python2.X版本和python3.X版本是不完全兼容的,而现在流行的是3.X版本的python规范。
而且在2020年以及停止了2.x的版本更新维护。
python适合做什么? 其实讲的就是它的主要应用领域,大概有下述几个方面:
人工智能机器学习数据分析网络爬虫自动化运维自动化测试Web应用开发 为什么在这里会说到python的应用领域呢,正如我上一篇文章里提到的一个概念,python在开发时根据不一样的需求会引用不一样的“模块”,而Python大概有超过12500个的“模块库”,想要都知道是不现实的。
所以,最好在初学时选取一个大概的应用领域,这在你充分学习了python基础和一些高级编程通用知识后,能较快的深入使用python。
搭建python的开发环境 Windows安装Python 去Python的官网:Python,下载喜欢的python版本,及适合自己PC的安装包
需要注意的是,在安装向导的第一步时,一定要勾选配置系统变量的选项“Add Python 3.7 to PATH",否则就需要自己去配置系统变量,不难但是麻烦。
其实在windows11系统中,你直接在命令行里输入python回车,如果系统里没有安装Python那么它会自己调转到微软商店里帮大家找到适合的python,直接安装即可。
linux下安装python linux的发行版很多,如果时学习Python的话建议大家使用ubuntu,系统自带python环境,省事
其他linux发行版比如centos,则可以通过yum安装,现在像阿里或者华为的源仓库支持都做得非常好了,在配置好源地址后,比如我安装python就非常小白,也没花什么力气,其实是因为自己是真小白,看那些网上大佬的博文一知半解的,所以就乱搞搞,反正也可以用。
安装前,其实最好运行一下python 或者python3看一下系统里是否已经有python了,没有的话再自己安装,
当然如果已有版本不是你需要的,也可自行安装对应版本的python,
安装新版本python最好先把原有python进行清除或者卸载掉,我只是简单学习所以没有太多的讲究,只要能用就行。所以,怎么删除python后边介绍。
华为开源镜像仓库地址:华为开源镜像站_软件开发服务_华为云 (huaweicloud.com)
以Centos7为例:
系统安装完之后,更换源为华为:
#备份配置文件 cp -a /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak #下载新的CentOS-Base.repo文件到/etc/yum.repos.d/目录下,替换 wget -O /etc/yum.repos.d/CentOS-Base.repo https://repo.huaweicloud.com/repository/conf/CentOS-7-reg.repo #清除原有yum缓存 yum clean all #刷新 yum makecache 安装Python和python-pip
#可以先查看python版本 yum list python --showduplicates | sort -r #安装python和python-pip yum install python,python-pip -y #pip是用来下载python模块库的工具,一些常用库其实安装python就自带了,初学阶段不一定会用到pip安装python模块库 #检查是否可用 python 或python3 #也可以-V查看版本是否符合 python -V 如果你需要的是Python的最新版本的话,只能去官网下载安装包,毕竟开源仓库里不提供所有python版本的。
初识python 关于pythonpython的格言怎么开始python的学习和使用我尝试过的几个python学习的常用组合 关于python 初识python是很多年前的事了,随着大数据应用在各行各业成为一个普遍的话题,尤其人工智能在其支撑下得到飞速的发展,python被越来越多的提起,被广泛应用于系统管理的自动化和Web编程中,似乎对于一名从事IT信息化事业的工作人员而言,“不学python,非好汉!”,更甚的一些网络培训机构、无良传媒为了某些因素,大势宣传python,成一家独大,编程只有Python。
其实作为任意一门高级编程语音,在实际使用时都有其优势的一面,除去早期的一些高级编程语言被淘汰外,当前在用的能被大家耳熟能详的高级编程语言都在某些方面发挥着巨大的作用有着自有的特点,面对多样复杂的业务需求,往往相互补短。
近几年断断续续,业余时间里,我也会随手看看关于python的基础知识,包括一些网上容易找到的教学视频,不得不说Pyhton的学习相对于其他有着严格语法规范的高级语言来说是非常简单的,语法构成非常接近英文的自然语言,基本语法、数据类型、内置函数、模块和面向对象编程等内容丰富,而且第三方扩展库提供了大量的适合各种业务处理的模块和包。非常适合对编程有兴趣的初学者作为第一门编程语言学习,同时在它身上可以看到其他一些编程语言的优秀思想的体现。
python的格言 我尤其喜欢其Tim Peters写的Python格言:
The Zen of python , by Tim Peters
Beautiful is better than ugly. #美丽比丑陋好
Explicit is better than implicit. #显露优于隐藏
Simple is better than complex. #简单胜于复杂
Complex is better than complicated. #复杂总比复杂好
Flatt is better than nested. #扁平比嵌套好
Sparse is better than dense. #稀疏比秘密更好
Readability counts. #可读性至关重要
Special cases aren’t special enough to break the rules. #特殊情况没有特殊到违反规则的程度
Although practicality beats purity.
在博弈论中,有这样一类问题:公平组合游戏(Impartial Combinatorial Games,ICG)。
若一个游戏满足:
由两名玩家交替行动;游戏中任意时刻,合法操作集合只取决于这个局面本身;若轮到某位选手时,若该选手无合法操作,则这名选手判负; 则称该游戏为一个公平组合游戏。
先来说两个概念:必胜态和必败态:
必胜态:若双方都采取最佳策略,那么持有当前状态的人必胜,当前状态则为必胜态。必败态:若双方都采取最佳策略,那么持有当前状态的人必败,当前状态则为必胜态; 如果将每个状态表示为一个节点,那么能走到必败态的一定是必胜态,走不到任何必败态的一定是必败态。
目录 Nim游戏SG函数 Nim游戏 ICG中一种叫做Nim游戏,它是最简单的且最常见的博弈论问题,学习博弈论的话首先要掌握这个问题。
Nim游戏的规则是:有 n n n堆石子,第 i i i堆石子有 a i a_i ai个,每次可以从某一堆中取走若干个,先后手轮流取,最后无石子可取的人判负。
对于这个游戏,如果双方都采用最佳策略的话,那么从开局就已经决定胜负了。现在要讨论的是,在每一步都是最佳策略的情况下,先手的人是必败还是必胜。
先给出结论:若 a 1 ⊕ a 2 ⊕ … ⊕ a n = 0 a_1⊕a_2⊕…⊕a_n=0 a1⊕a2⊕…⊕an=0,那么先手必败;否则先手必胜。
下面给出一个简单的证明:
我们已知, a 1 = a 2 = … = a n = 0 a_1=a_2=…=a_n=0 a1=a2=…=an=0为必败态,此时 0 ⊕ 0 ⊕ … ⊕ 0 = 0 0⊕0⊕…⊕0=0 0⊕0⊕…⊕0=0;若 a 1 ⊕ a 2 ⊕ … ⊕ a n = x ≠ 0 a_1⊕a_2⊕…⊕a_n=x ≠0 a1⊕a2⊕…⊕an=x=0,证明:一定可以通过某种方式让 a 1 ⊕ a 2 ⊕ … ⊕ a n = 0 a_1⊕a_2⊕…⊕a_n=0 a1⊕a2⊕…⊕an=0;
随着对 LLM(大语言模型)的了解与使用越来越多,大家开始偏向于探索 LLM 的 agent 能力。尤其是让 LLM 学习理解 API,使用工具进行对用户的 instruction(指令)进行处理。然而,目前的开源大模型并不擅长使用工具,最善于使用工具的 ChatGPT 是闭源的模型。研究人员设计了一个评测 LLM 使用工具能力的 Benchmark(基准)—— LLMBench,以及一个针对该场景的数据构建、模型训练、评测的框架—— ToolLLM。
这张图展示了构建ToolBench的三个阶段,以及如何训练API检索器和ToolLLaMA。在执行指令时,API检索器会向ToolLLaMA推荐相关的API,ToolLLaMA通过多轮API调用得出最终答案。整个推理过程由ToolEval评估。 研究人员主要是从RapidAPI来收集API,所有的API都可以分为49个粗粒度类别,例如体育、金融和天气。研究人员评测了这些API,最后经过筛选,留下了16,464个API。LLM的prompt(提示)中包括了这些API相关的文档和使用用例。
作者根据API,使用ChatGPT生成可能用到的指令,利用 {INST,API} 的格式训练API retriever。最后得到的prompt包含了任务的描述、API的文档、3个API的使用例。
作者通过序列来对执行路径进行探索{a1,r1,a2,r2.....}a为采取的function call,r为返回的response,为了避免一直错误的路径上探索,作者设计了一个基于深度优先的决策树,并将放弃执行也作为一个节点,返回到之前的路径重新选择,从而节省了对于chatgpt的调用。最后收集到了12, 657 个instruction solution pairs用来训练ToolLLaMA。
首先训练API检索器的目标是与指令检索相关的API,采用了Sentence-BERT 训练基于BERT-BASE的密集检索器。该模型分别将指令和API文档编码为两个嵌入向量,并通过这两个向量的相似性确定它们之间的相关性。在训练过程中,作者将之前生成的每个指令的相关API视为正样本,并采样一些其他API作为负样本进行对比学习。
然后,作者使用了指令-解决方案对对LLaMA 7B模型进行微调。因为工具的响应通常会非常长,原始的LLaMA模型的序列长度2048 或许不能够满足本次场景。为此,作者使用positional interpolation将上下文长度扩展到8192,最后以多轮对话模式训练模型。在训练数据格式方面,作者保持输入和输出与ChatGPT的相同。
ToolLLM 介绍了如何在LLMs中引入使用工具的能力,提出了一个指令调优的数据集ToolBench,涵盖了16k+真实世界的API和各种实际的用例场景,包括单一工具和多工具任务。ToolBench的构建只使用ChatGPT,并且最小限度的使用人工监督。此外,ToolLLM还提出了DFSDT来加强LLMs的规划和推理能力,使它们能够有策略地在推理路径中导航。并且实验结果也显示出了使用经过训练的开源模型ToolLLaMA极大的提高了使用工具能力。
相关资料:
论文: https://arxiv.org/pdf/2304.01662.pdf Github: https://github.com/OpenBMB/ToolBench 本文由 mdnice 多平台发布
CONNECT_BY_ROOT 是一个在 Oracle 数据库中使用的特殊函数,它通常用于在层次查询中获取根节点的值。在使用 CONNECT BY 子句进行层次查询时,通过 CONNECT_BY_ROOT 函数,你可以在每一行中获取根节点的值,而不仅仅是当前行的值。
假设有一个需求,给定一个编码,需要查询出来它的子级、孙级 😄
那么我们可以使用oracle中的CONNECT_BY_ROOT函数,来对编码进行层次查询。
sql如下:
SELECT CONNECT_BY_ROOT a.PCODE AS Parent, LEVEL, a.PCODE, a.RULESCODE FROM GR_REVIEWRULES a START WITH a.PCODE = '2.1.1.1' CONNECT BY PRIOR a.RULESCODE = a.PCODE; 如下图所示:
让我进行解释下:
SELECT CONNECT_BY_ROOT a.PCODE AS Parent, LEVEL, a.PCODE, a.RULESCODE: 这部分定义了查询的输出列。CONNECT_BY_ROOT a.PCODE 显示了子级和孙级的总级(根节点)编码,LEVEL 表示当前节点在层次结构中的级别,a.PCODE 显示了2.1.1.1所有的子级编码,a.RULESCODE 为2.1.1.1所有孙级编码
START WITH a.PCODE = '2.1.1.1': 定义查询的起始节点,从具有编码值为 '2.1.1.1' 的行开始。
CONNECT BY PRIOR a.RULESCODE = a.PCODE: 使用 CONNECT BY 子句来定义如何递归地遍历层次结构。在这里,PRIOR a.
ORACLE行转列、列转行实现方式及案例 行转列案例方式1.PIVOT方式2.MAX和DECODE方式3.CASE WHEN和GROUP BY 列转行案例方式1.UNPIVOT方式2.UNION ALL 行转列 案例 假设我们有一个名为sales的表,其中包含了产品销售数据。表中有三列:product(产品名称)、year(年份)和amount(销售额)。表中的数据如下:
将这个表中的数据进行行转列,使得每一行表示一个产品,每一列表示一年的销售额。
使得得到以下结果:
方式1.PIVOT PIVOT是Oracle 11g之后引入的一种用于行列转换的函数。它可以将查询结果中的行数据转换为列数据,从而实现行列转换。PIVOT函数的基本语法如下:
SELECT ... FROM ... PIVOT (aggregate_function(column_to_aggregate) FOR column_to_pivot IN (list_of_values)) 其中,aggregate_function是一个聚合函数,如SUM、MAX、MIN等;column_to_aggregate是要进行聚合的列;column_to_pivot是要进行行列转换的列;list_of_values是要转换为列的值的列表。
实现案例所示效果可以通过如下方式:
SELECT * FROM sales PIVOT (SUM(amount) FOR year IN (2018, 2019, 2020)); 方式2.MAX和DECODE DECODE 可以根据条件返回不同的值。DECODE 函数的基本语法如下:
DECODE(expression, search1, result1, search2, result2, ..., default) 其中,expression 是要进行比较的表达式;search1、search2 等是要进行比较的值;result1、result2 等是当表达式与对应的搜索值相等时返回的结果;default 是当表达式与所有搜索值都不相等时返回的默认值。
若要实现案例的效果可以通过以下方式:
SELECT product, MAX(DECODE(year, 2018, amount)) AS "2018", MAX(DECODE(year, 2019, amount)) AS "2019", MAX(DECODE(year, 2020, amount)) AS "
小区情况 规划图基本情况交房时间小区优势小区周围情况小区周围商业、医院情况小学 中学情况地铁天河路高架上下口开通小区2栋安置房情况一些高清图地址小区设计图小区采光 图片拍摄于冬天最新进展 2023年7月26日最新进展 2023年8月10日 规划图 基本情况 交房时间 合同是2023年9月交房,很多置业顾问说可能会提前几个月交
小区优势 周围有医院(郑州市第三人民医院北小区[三甲]),有小学(运河小学,就在小区路对面),中学(距离1.5公里左右),有地铁(2号线惠济区政府站,距离小区1.1公里左右,三号线北延长线(弓寨站), 目前还没开始建设,就在小区西侧);古树苑(公园)。稍远一点有惠济万达、碧源月湖、万科广场、大学城等。
小区周围情况 北面: 安置房小区。南面:大河宸院四期:建筑最高13层。西面:2栋安置房。东面:住宅用地,暂不知道具体的占地面积和容积率
小区周围商业、医院情况 最近的商业有运河广场(位于天河路与大河路西南),融创自己建的商业街(中原宸院二期南侧), 这两个都离小区比较近,1公里左右。再远一点有惠济万达、碧源月湖广场(从小区步行3公里左右,骑电动车需要10分钟左右). 医院最近有郑州市第三人民医院北院区(三甲医院), 距离小区1公里左右;惠济区人民医院距离小区2.5公里左右,远了点,但是收费相对便宜,小病可以去这家医院看看。
小学 中学情况 小区西南是小学,惠济区运河小学(网上有这个学校的招标信息,上面写着 2022年5月工程完工)
中学是郑州市第七十九中学(惠济区的朋友说教学质量不太好)
地铁 目前开通可2号线惠济区政府站,距离小区路程(不是直线距离)1.2km。 步行大约12分钟
3号线北延长线目前没有批复,但是惠济区政府已经留有换乘口,小区里的业主有在地铁上班的(其中有几位是在3号线上班的)
天河路高架上下口开通 有人给政府留言询问过,得到的回答是要等3号线北延修好后才能开始增加高架上下口
小区2栋安置房情况 小区最西面的那两栋房屋是安置房,置业顾问说会采用软隔离的形式(很可能就是绿化带隔离)跟商品房隔离开
一些高清图地址 https://github.com/wanmei002/zhengzhou-dahechenyuan/
小区设计图 小区采光 图片拍摄于冬天 最新进展 2023年7月26日 房子是不可能按时交房了。如果加加油,可能年底能交房,但是有 70%不可能。如果年底交不了房,有小区里的其他人猜测可能到明年5月份了旁边的安置房目前不盖了,优先盖商品房。本来规划小区里有个 2、3层物业公共房也不盖了。目前消防 绿化已进场建设资金应该还需要 8kw吧 最新进展 2023年8月10日 建设二局退场,好像是钱的问题,派人进入工地关电,不让工人工作,目前项目处于停工
一、HTML 部分 @select=“rowSelect” 监听elementUI表格事件:当用户手动勾选数据行的Checkbox时触发的事件
@select-all=“selectAll” 监听当用户手动勾选全选Checkbox时触发的事件
<el-table :data="list" default-expand-all ref="multipleTable" header-cell-class-name="table-header" @selection-change="handleSelectionChange" :tree-props="{ children: 'children' }" row-key="id" @select="rowSelect" @select-all="selectAll" style="width: 100%" > > <el-table-column type="selection" width="55"></el-table-column> <el-table-column label="类别名称" prop="name"></el-table-column> <el-table-column label="分类级别" prop="level"></el-table-column> <el-table-column label="类别描述" prop="detail"></el-table-column> </el-table> 二、功能实现部分 注:每个数据都要有 isChecked:false 作初始标志参数
1. 单行勾选 ① selection 是选中的数据集合
② toggleRowSelection(row, selected) 多选表格切换某一行选中状态,selected 为 true 则选中
rowSelect(selection, row) { // 1.当前点击是父节点 if (row.children) { // 1.1 当前父节点没被选中 if (!row.isChecked) { // 子节点全部变为选中 row.children.map((item) => { this.
使用fabric.js+pdf.js实现简易盖章 - 掘金
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 在测试时,我们经常需处理请求返回的响应数据,比如很多时候 cookie 或 token 或 Authorization授权码 会返回在 Response headers(响应头)中,这时我们便需要从中进行提取,以供其他接口使用。
如何在Jmeter中通过正则提取响应数据中 Response headers 的数据?
总的设置界面如下:
发送请求,获取响应数据
首先,设置一个HTTP请求,如下:
接着,设置一个察看结果树,然后执行,得到响应数据,下图中的cookie即我们需要提取的数据:
正则提取响应数据
接下来,我们便设置一个正则提取器(用于提取出cookie),另外再设置一个调试后置处理程序(用于查看提取结果)
说明:
1、引用名称:即变量名,后续请求中可以通过 引用名称来调用 2 、正则表达式:按实际情况填写 3 、模板: {引用名称} 来调用 2、正则表达式:按实际情况填写 3、模板: 引用名称来调用2、正则表达式:按实际情况填写3、模板:$表示需要哪个正则表达式获取的值,1代表第一个,-1代表全部,0代表随机
4、匹配数字:1代表第一个,-1代表全部,0代表随机
5、缺省值:如果正则未匹配到,就会使用缺省值
正则说明:
.:表示除“\r\n”之外的任意字符 *:表示匹配前面的子表达式任意次 +:表示匹配前面的子表达式1次或多次 ?:表示匹配前面的子表达式0次或1次 .*:贪婪匹配原则,即匹配到不能匹配为止 .*?:非贪婪匹配,即在匹配成功的情况下尽可能少的匹配 实例:
存在字符串 7adbcfgfbesw ,要匹配7和b之间的字符
匹配1:使用 .* ,7开始之后,遇到第一个b不结束,继续找下一个b,直到不能匹配,即匹配到 adbcfgf 匹配2:使用 .*? ,7开始之后,遇到第一个b就结束了,即匹配到 ad 查看提取结果提取结果
以上就是本次的提取结果,在这里,如果需在后续请求使用,可通过 ${response_data} 来关联调用。
可能遇到的问题
假如,我们需提取 Set-Cookie 里的所有内容。此时,如果依然使用 .*? ,就会发现提取是不成功的,如下:
要解决这个问题也很简单,我们修改正则表达式,使用 .* 贪婪匹配原则既可以。
以上就是通过Jmeter正则提取的内容,提取其他数据,如 token 、 Authorization 等的方法与上面类似。
很多题目需要求组合数 C a b C^b_a Cab,而面对题目的不同要求,求组合数的方法略有不同。下面来看看几种主要的求组合数的算法。
目录 1、根据定义求2、预处理结果(数的范围较小)3、预处理阶乘(数的范围较大)4、卢卡斯(Lucas)定理(数的范围巨大)5、不模的组合数6、组合数应用:卡特兰数 1、根据定义求 我们拿最基本的求法来引入。组合数的公式: C a b = a ! ( a − b ) ! b ! C^b_a=\frac{a!}{(a-b)!b!} Cab=(a−b)!b!a!。因此只要根据公式即可写出。规定 C n 0 = 1 C^0_n=1 Cn0=1。给出代码来求解 C a b C^b_a Cab:
int C(int a, int b) { if (b > a) return 0; int res = 1; for (int i = 1, j = a; i <= b; i ++ , j -- ) { res = res * j; res = res / i; } return res; } 如果数据范围略大,需要模上一个数,这时候除法使用逆元来求 C b a m o d p C^a_bmodp Cbamodp:
对于有残基缺失的晶体结构往往采用同源建模的方式补全,但常规的同源建模方法往往造成非缺失区域残基的挪动,有时我们并不想出现这种状况,尤其是涉及到多个截短体拼合的情况,这时就需要用到约束性同源建模的方法,只对缺失区域补全而尽可能少地改动非缺失区域。效果图如下所示:
1、准备建模序列文件 >P1;Target sequence:Target:::::::0.00: 0.00 TCFSGDDDSGLNLGFSTSFAEYNEFDGGEKALIGFSTSFAEFDAEAGDSDEQPIFPQHKLTCFS* 前两行格式严格遵守!!!
保存文件名为Target.ali
将模板结构文件存储为temp.pdb文件(单链,除去水和离子)
以下是从pdb文件中提取fasta序列的脚本:
from Bio import PDB from Bio.PDB import PDBParser, PDBIO from Bio.PDB.Polypeptide import PPBuilder from Bio.Seq import Seq from Bio.SeqRecord import SeqRecord import sys def extract_fasta_from_pdb(pdb_file, type): parser = PDBParser(QUIET=True) if type == "pdb": structure = parser.get_structure('PDB', pdb_file) if type == "pdb.gz": with gzip.open(pdb_file, 'rb') as f_in: with open('temp.pdb', 'wb') as f_out: f_out.write(f_in.read()) structure = parser.get_structure('PDB', 'temp.pdb') ppb = PPBuilder() fasta_records = [] for model in structure: for chain in model: polypeptides = ppb.
Pyside6可视化界面 安装Pyside6 激活之前的虚拟环境yolov5
在该环境的终端输入以下命令
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyside6 输入where python找到当前使用的Python的路径
找到该路径下的designer.exe文件(/Lib/site-packages/PySide6/designer.exe),然后发送到桌面创建快捷方式
UI设计 打开designer选择Main Window 移除菜单栏 拖两个label个一个line进来 拖两个button进入,并进行命名 调整界面,填写两个label里面文件,将界面调小一些 居中对齐,同时勾选scaledContents 元素名称更改 Ctrl+S保存,保存到上一部分训练数据集的文件内 设置Pyside6-uic 工具 在当前虚拟环境的Python路径下,打开Scripts文件夹夹,找到pyside6-uic.exe,记住当前路径 创建工具 名称:PyUic(可自己定义) 程序:E:\kaifa\Anaconda3\envs\yolov5\Scripts\pyside6-uic.exe 实参:$FileName$ -o $FileNameWithoutExtension$.py 工作目录: $FileDir$ 使用该工具 先在pycharm中打开刚才生成的ui文件
双击打不开的话,把文件拖到右边就可以打开了
然后在【工具】选项卡下的【external tools】下,点击【PyUic】(这个名称是你刚才自己设计的)
如果生成了相同文件名的.py文件,即说明设置成功
编写运行程序 创建模板文件base_ui.py import sys import torch from PySide6.QtGui import QPixmap, QImage from PySide6.QtWidgets import QMainWindow, QApplication, QFileDialog from main_window import Ui_MainWindow #main_windows是刚才生成的ui对用的Python文件名 def convert2QImage(img): height, width, channel = img.shape return QImage(img, width, height, width * channel, QImage.
开发环境的部署搭建 超级小星星:时间过得可真快ESPFriends创客沙龙已经在武汉举办了两期,在这里有行业内的工程师、高校的学生以及极客,在这里我们交流分享自己的开发心得,提出遇到的“大坑”也可以得到小伙伴们的解决方案,希望活动可以越办越好,在这里我也记录一下自己的开发历程和学习心得与大家共勉。
内容源码地址:link
本期的主题是模型的训练与部署,AI这个东西确实很神奇,我们之所以感觉这东西很“虚”,是因为我们并没有将其落到实处,这里我们就开始本期的探索之旅吧!o( ̄▽ ̄)ブ
软件配置 我的的测试训练环境:
电脑系统:
Win11 软件:
VScodeESP-IDF(V4.4.5)AnacondaPyCharmGit 参考资料:
TensorFlow Lite Micro for Espressif Chipsets(乐鑫官方例程)esp-whoesp-skainetTensorFlow Lite 为了避免下载到有病毒的资源,所有的链接都是出自官方网站或者国内源
编译并运行官方的第一个例程 俗话说的好写程序从hello_world开始,当然我们检验自己的开发环境搭建是否正确当然先编译一下啦,这里解释一下为什么没有使用最新版本的IDF,因为在使用ESP-WHO框架的话,需要使用官方建议的软件分支,不然谁知道会出现什么问题,我使用过5.1分支的去set-target,不出所料第一步就出现问题/(ㄒoㄒ)/~~,当然官方之后会更新的啦!
这里需要我们打开文件目录使用命令行的方式去编译项目工程,并烧录到ESP32-S3-EYE (感谢官方的开发板\^o^/)
当然对应的例程目录下面都有一个README文件,这里按照上面的说明操作即可:
# 设置芯片型号 idf.py set-target esp32s3 # 编译工程 idf.py build # 烧录并打开串口监视 # 在这里使用命令行的话win平台下会自动找到设备串口并烧录 idf.py flash monitor 表示设置芯片信号成功,后面就会很顺利了
编译成功
烧录成功
查看测试程序
程序成功跑起来啦o(/ ̄▽ ̄)ブ
命令是不是很简单,当然这只是成功的一小步,后面还有更多的未知等待着我们去探索
跑一遍Tensorflow lite官方的示例程序 link
这里按照官方文件夹中的README文件操作,安装了bazel,在其根目录下运行指令
bazel build tensorflow/lite/micro/examples/hello_world:evaluate 第一步都过不了,找了半天都没找到解决办法/(ㄒoㄒ)/~~,好像是因为软件源的问题,但是在linux下可以使用清华源设置,在win下目前还没有找到解决方法
这里不影响我们用它的代码做参考,接下来我们就要自己敲代码了o(* ̄▽ ̄)ブ
导入依赖项
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt import math # 生成从0到2派的数据,并将数据转换为np的float32的格式 x_values = np.
环境依赖 gcc gcc-c++ [root@redis ~]# yum install gcc* -y 下载安装包 [root@redis ~]# wget https://download.redis.io/redis-stable.tar.gz --2023-07-13 16:54:01-- https://download.redis.io/redis-stable.tar.gz Resolving download.redis.io (download.redis.io)... 45.60.125.1 Connecting to download.redis.io (download.redis.io)|45.60.125.1|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 3071850 (2.9M) [application/octet-stream] Saving to: ‘redis-stable.tar.gz’ 100%[======================================>] 3,071,850 29.8KB/s in 65s 2023-07-13 16:55:06 (46.3 KB/s) - ‘redis-stable.tar.gz’ saved [3071850/3071850] [root@redis ~]# ll total 3004 -rw-------. 1 root root 1294 Jul 13 11:32 anaconda-ks.cfg -rw-r--r--. 1 root root 3071850 Jul 10 19:52 redis-stable.
tempent
<AFormItem label="白色图标" name="iconWhiteUrl"> <div class="inputBox"> <span>上传文件 <input id="iconWhiteInp" accept="image/png" class="img-input" type="file" @change="(file)=>handleChangeIconWhiteUrl(file)" /> </span> </div> <p>{{ value.iconWhiteUrl }}</p> </AFormItem> ts
import { defineComponent, reactive,ref ,nextTick} from 'vue' import {uploadImg} from "./addOrChange" const handleChangeIconWhiteUrl = async(e:any)=>{ iconWhiteUrlList.value =[] // 自己展示的返回图片地址 uploadImg(e,'white') //调用上传方法 const iconWhiteInp = document.getElementById('iconWhiteInp') as HTMLInputElement | null; //获取元素清空value if(iconWhiteInp){ iconWhiteInp.value = '' } } //addOrChange文件封装引入,这里是传formData的 import { reactive } from 'vue'; import { message } from 'ant-design-vue' import api from '@/api/api' export const addOrChangeForm = reactive({ iconWhiteUrl:"